 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banane
Google - Gemini, Nano Banane Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance – Das Beste von ByteDance
ByteDance – Das Beste von ByteDance Alle Modelle
Alle Modelle Unternehmenspläne
Unternehmenspläne KI-Anwendungsentwicklung
KI-Anwendungsentwicklung KI-Übersetzer-API
KI-Übersetzer-API KI-SEO/GEO-Dienst
KI-SEO/GEO-Dienst Geooptimierter PR-Service
Geooptimierter PR-Service Web-Scraping-Dienst
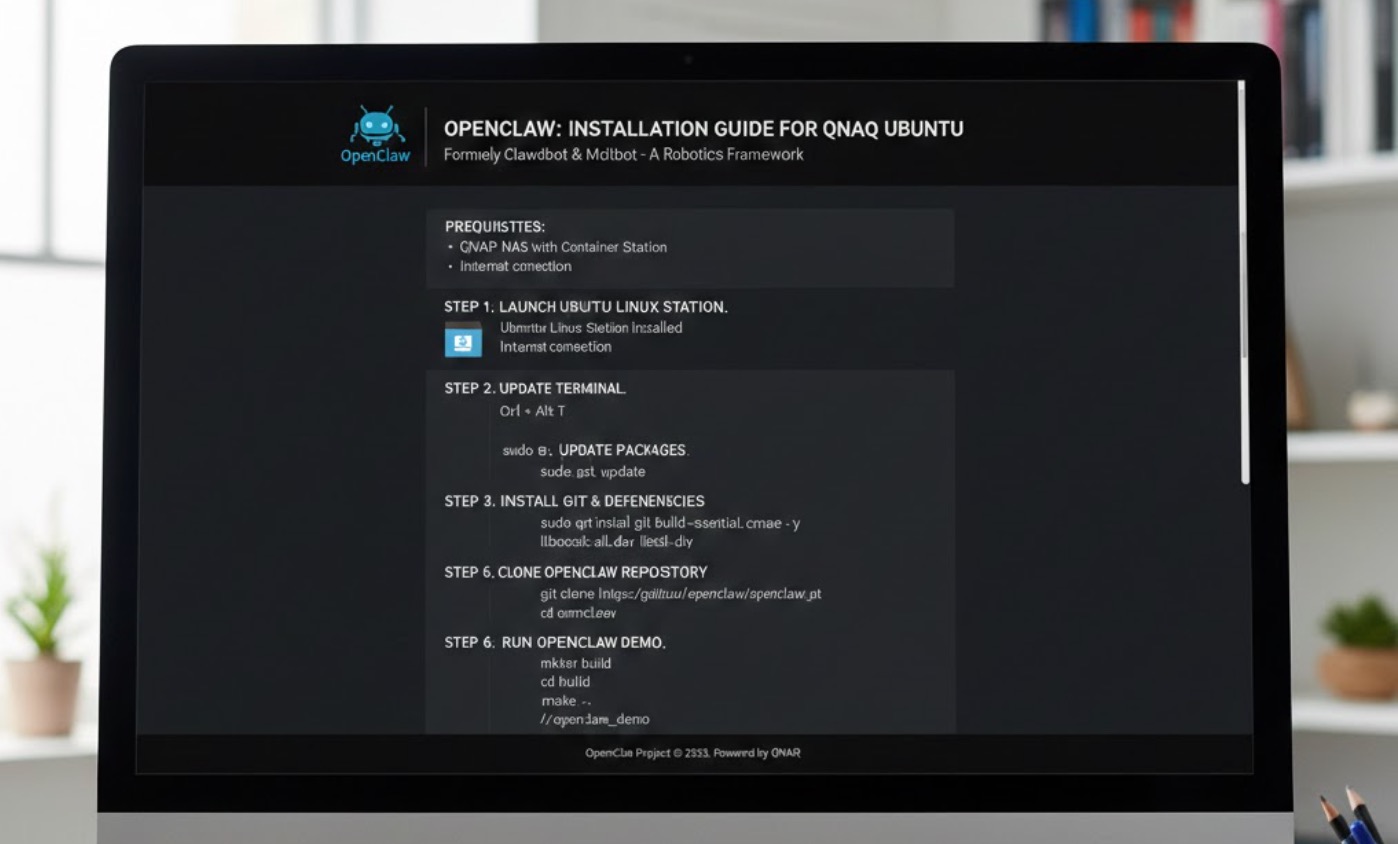
Web-Scraping-Dienst OpenClaw
OpenClaw Die besten KI-Tools
Die besten KI-Tools Top-KI-Roboter
Top-KI-Roboter
 Einloggen
Einloggen












1
Komplexe Codierung & Fehlersuche
Claude Sonett 4.6 bleibt unangefochten. Es versteht ganze Repositories besser und macht weniger „selbstsichere, aber falsche“ Änderungen.

Benchmarks, Praxistests, Preisgestaltung, Anwendungsfälle und Expertenurteil – alles, was Sie für die Wahl des richtigen Modells benötigen.
Der Februar 2026 wird als der Monat in Erinnerung bleiben, in dem sich die KI-Landschaft in zwei Teile spaltete. Google entfesselte Gemini 3.1 Pro Am 19. Februar, während Anthropic fiel Claude Sonett 4.6 nur 48 Stunden zuvor, am 17. Februar. Beide Modelle bieten eine Intelligenz auf nahezu Opus-Niveau, zeichnen sich aber durch völlig unterschiedliche Eigenschaften aus.
Gemini 3.1 Pro dominiert Benchmarks für reine Intelligenz. Claude Sonnet 4.6 übertrifft seine Preisklasse bei praktischen, produktionsreifen Aufgaben deutlich.
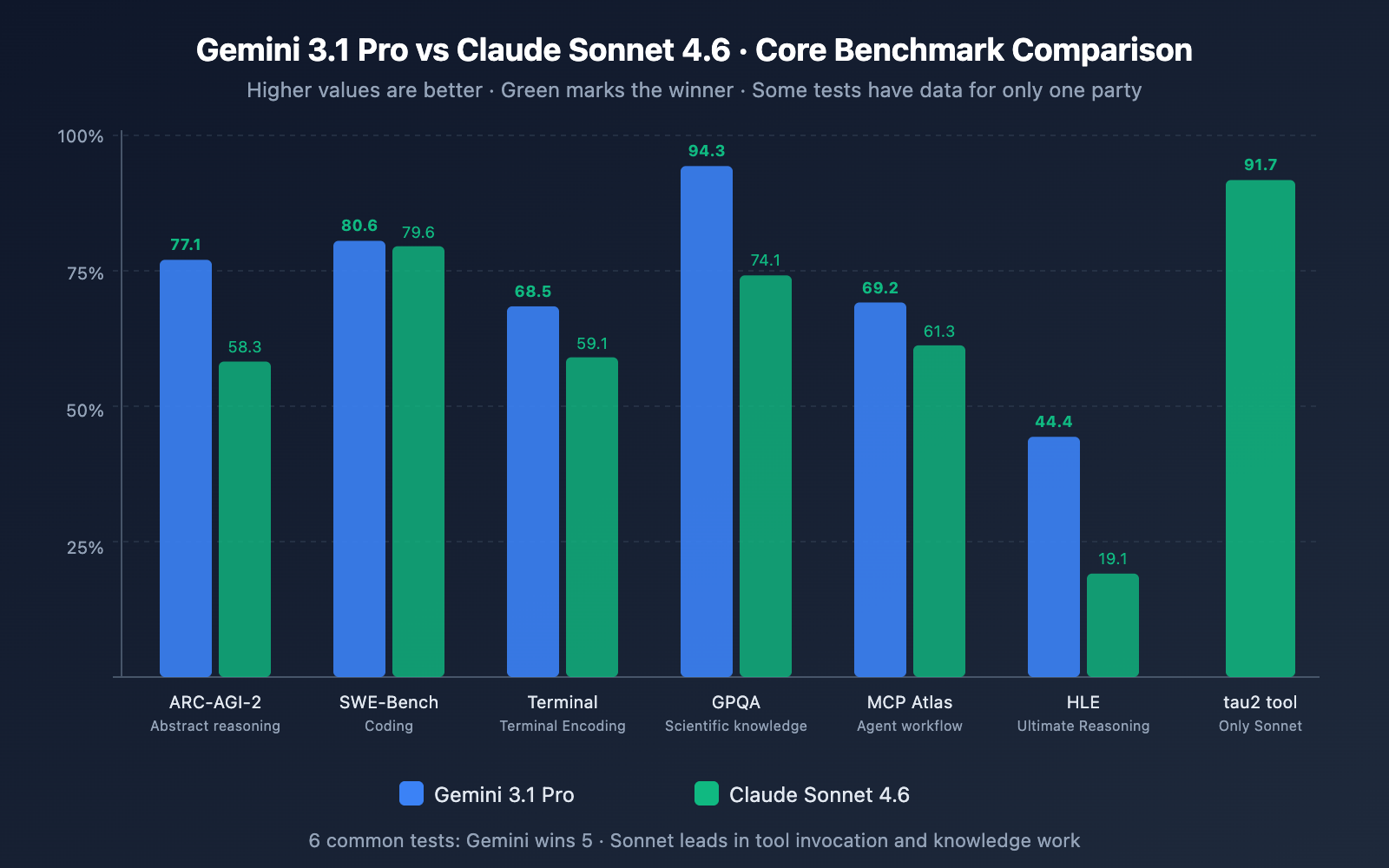
| Benchmark | Gemini 3.1 Pro | Claude Sonett 4.6 | Gewinner | Was es testet |
|---|---|---|---|---|
| ARC-AGI-2 (Abstraktes Denken) | 77,1 % | 58,3 % | Zwillinge +18,8 Punkte | Neuartige Rätsellösung, Verallgemeinerung |
| GPQA Diamond (Graduiertenwissenschaft) | 94,3 % | 74,1 % | Zwillinge +20,2 Punkte | Physik, Chemie, Biologie auf Doktorandenniveau |
| Die letzte Prüfung der Menschheit (HLE) | 44,4 % | 19,1 % | Zwillinge +25,3 Punkte | Grenzebenen-Mehrschrittschlussfolgerung |
| SWE-Bench-Verifizierung (Codierung) | 80,6 % | 79,6 % | Claude (nahezu gleichauf) | Lösung eines echten GitHub-Problems |
| MCP Atlas (Mehrstufiger Agent) | 69,2 % | 61,3 % | Zwillinge +7,9 Punkte | Agentische Planung + Ausführung |
| tau2 Tool-Aufruf | — | 91,7 % | Claude | Zuverlässige Werkzeugwahl und Computernutzung |

Claude Sonett 4.6 bleibt unangefochten. Es versteht ganze Repositories besser und macht weniger „selbstsichere, aber falsche“ Änderungen.

Gemini 3.1 Pro ist unantastbar — Native Videoanalyse bis zu 1 Stunde, Audio-Transkription + Begründung in einem Durchgang.
Zwillinge haben in der Breite die Nase vorn; Claude punktet mit Zuverlässigkeit. und weniger Ausführungsschleifen.
Forschungssynthese, kreative Langform, Datenanalyse, juristische Überprüfung, mathematische Beweise, UI-Automatisierung, Enterprise RAG – das Muster ist klar: Zwillinge für intellektuelle Breite, Claude für Ausführungszuverlässigkeit.
Reddit · X (Twitter) · Hacker News – 20.–27. Februar 2026
Zwillinge scheinen im Bereich des logischen Denkens endlich auf GPT-5-Niveau zu sein.
Mehr als 70 % der Entwickler verwenden für die Copilot-Programmierung immer noch standardmäßig Claude Sonnet 4.6.
Wir verwenden Gemini für Strategie-Decks und Claude für die eigentliche Code-Bereitstellung.
Die Strategie, die Top-Teams im Jahr 2026 tatsächlich anwenden
Vereinheitlichte API-Plattformen ermöglichen den Wechsel mit nur einer Codezeile.

Erwarten Zwillinge 3.2 mit noch stärkerem Videoverständnis und 2M-Kontext, und Claude Opus 4.7 oder Sonett 5.0 Die Programmierstandards werden immer weiter angehoben. Der wahre Gewinner Ende 2026? Nutzer, die die Grundlagen beherrschen. Multi-Modell-OrchestrierungDie