 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banane
Google - Gemini, Nano Banane Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance – Das Beste von ByteDance
ByteDance – Das Beste von ByteDance Alle Modelle
Alle Modelle Unternehmenspläne
Unternehmenspläne KI-Anwendungsentwicklung
KI-Anwendungsentwicklung KI-Übersetzer-API
KI-Übersetzer-API KI-SEO/GEO-Dienst
KI-SEO/GEO-Dienst Geooptimierter PR-Service
Geooptimierter PR-Service Web-Scraping-Dienst
Web-Scraping-Dienst OpenClaw
OpenClaw Die besten KI-Tools
Die besten KI-Tools Top-KI-Roboter
Top-KI-Roboter
 Einloggen
Einloggen



const Anthropic = require('@anthropic-ai/sdk');
const api = new Anthropic({
baseURL: 'https://api.ai.cc/',
authToken: '',
});
const main = async () => {
const message = await api.messages.create({
model: 'anthropic/claude-sonnet-4.5',
max_tokens: 2048,
system: 'You are an AI assistant who knows everything.',
messages: [
{
role: 'user',
content: 'Tell me, why is the sky blue?',
},
],
});
console.log('Message:', message);
};
main();
import asyncio
from anthropic import Anthropic
client = Anthropic(
base_url="https://api.ai.cc/",
auth_token="",
)
def main():
message = client.messages.create(
model="anthropic/claude-sonnet-4.5",
max_tokens=2048,
system="You are an AI assistant who knows everything.",
messages=[
{
"role": "user",
"content": "Hello, Claude",
}
],
)
print("Message:", message.content)
if __name__ == "__main__":
main()


Produktdetails
🚀 Bringen Sie Ihre Projekte mit der Claude 4.5 Sonnet API auf ein neues Level.
Anthropics Claude 4.5 Sonett zeichnet sich als eines der hochentwickeltsten verfügbaren KI-Modelle aus, das speziell für herausragende Leistungen entwickelt wurde. Software-Programmierung, Ausführung komplexe Agentenaufgabenund die Ermöglichung umfassender autonome ComputernutzungDieses Modell ist außerordentlich gut geeignet, mehrstufige Prozesse über lange Zeiträume hinweg zu bewältigen und zeichnet sich durch überlegenes Denkvermögen, tiefgreifendes Fachwissen und eine nahtlose Interaktion mit Computersystemen aus.
Sonnet 4.5 wurde für unternehmenskritische Umgebungen entwickelt und bietet beispiellose Genauigkeit, Zuverlässigkeit und Sicherheit in anspruchsvollen realen Anwendungen wie z. B. Finanzen, Cybersicherheit, Forschung und fortschrittliche EntwicklungsabläufeDie
⚙️ Technische Spezifikationen
- 💻 Hauptstärken: Spezialisiert auf Softwareentwicklung, komplexe Agenten und die Automatisierung der Computernutzung.
- 📜 SWE-bench-verifiziert: Erreicht ein beeindruckendes 77,2 % Genauigkeit mit aktiviertem erweiterten Denkmodus, was erstklassige Programmierkenntnisse demonstriert.
- 💬 OSWorld Benchmark: Ergebnisse 61,4 % für die Erledigung realer Computeraufgaben, wodurch der praktische Nutzen hervorgehoben wird.
- 🧠 Erweiterter Denkmodus: Verbessert die Leistung bei komplexen Denkprozessen, mehrstufiger Codierung und agentenbasierten Arbeitsabläufen erheblich, indem eine tiefere kognitive Verarbeitung ermöglicht wird, allerdings mit einem leichten Kompromiss bei Latenz und Caching-Effizienz.
- 📚 Kontextmanagement: Bietet eine außergewöhnliche Langzeit-Zustandsverfolgung durch ein fortschrittliches Kontextfenster und die Berücksichtigung externer Dateizustände, wodurch effektives Erinnern und anhaltende Konzentration über viele Stunden hinweg gewährleistet werden.
📊 Leistungsbenchmarks
Sonnet 4.5 verfügt über ein fortschrittliches Langzeit-Kontextmanagement, das es ermöglicht, auch über stundenlange Sitzungen hinweg die Aufmerksamkeit und Konzentration aufrechtzuerhalten. Diese Fähigkeit ist unerlässlich für anspruchsvolle Programmierprojekte, komplexe Multiagenten-Koordination und langwierige Computerinteraktionen. Die verbesserte Werkzeugnutzung erlaubt es dem Modell, mehrere Prozesse gleichzeitig zu steuern und so die Effizienz autonomer Arbeitsabläufe wie komplexes Software-Debugging, Datensynthese und tiefgreifende Finanz- oder Cybersicherheitsanalysen zu steigern. Ein wesentliches Unterscheidungsmerkmal ist die hybride Architektur, die sowohl schnelles Schlussfolgern als auch einen spezialisierten Modus für erweitertes Denken zur Lösung komplexer Probleme unterstützt.
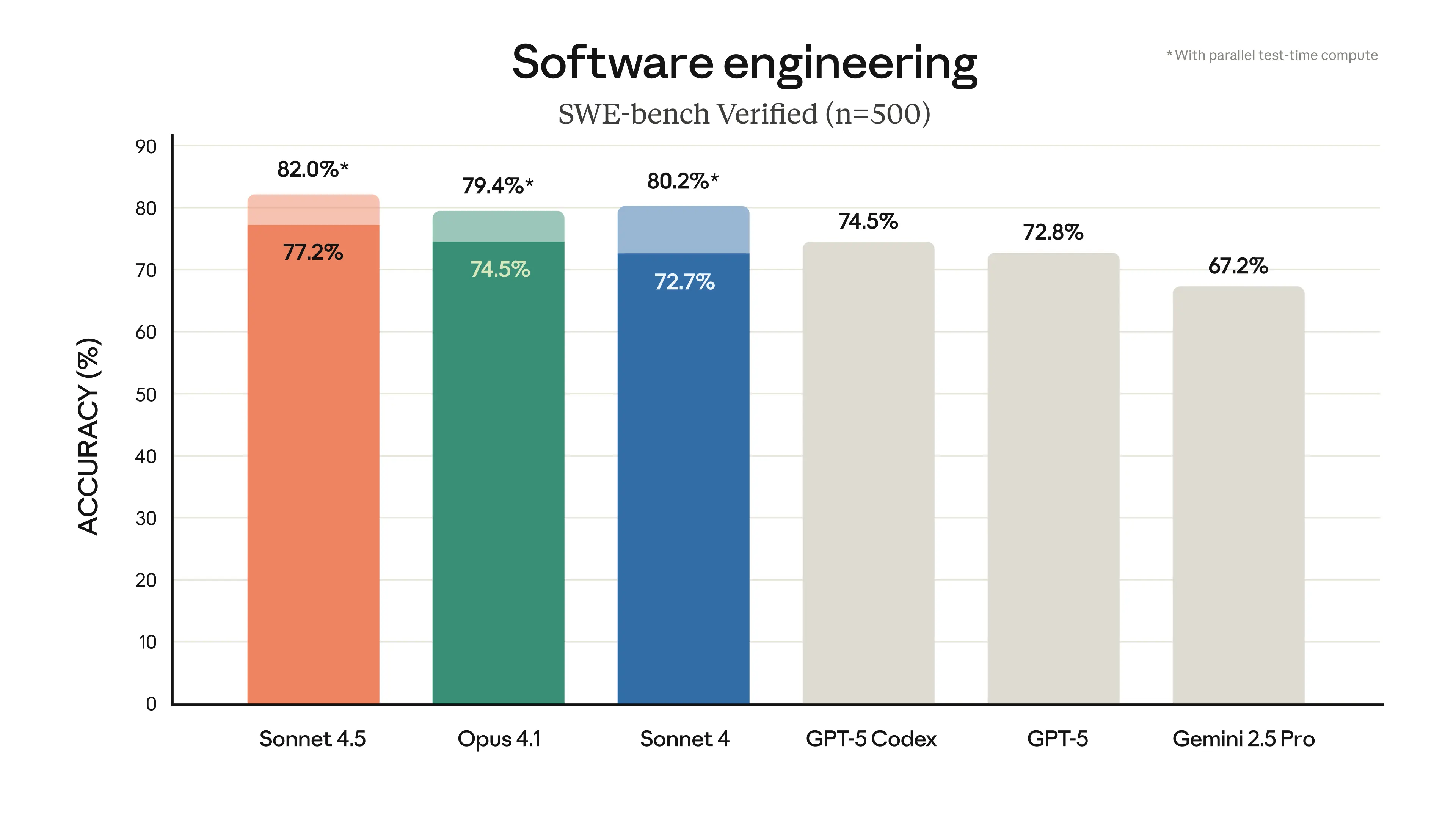
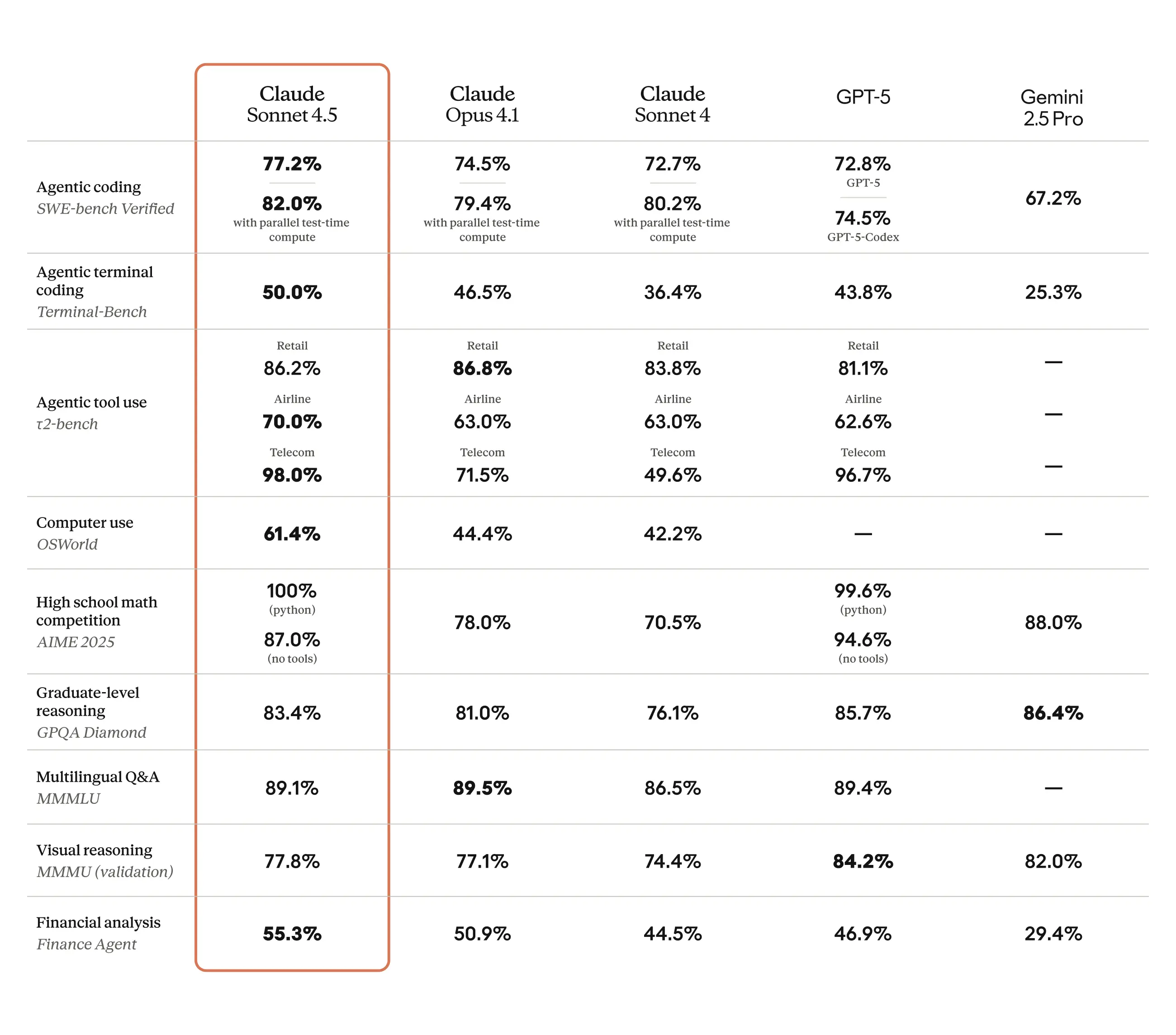
Leistungsbenchmarks: Visualisierung der Fähigkeiten von Claude 4.5 Sonnet.
✨ Hauptmerkmale
- 💻 Bestes Codierungsmodell bis dato: 77,2 % Genauigkeit auf SWE-Benchmark verifiziertSonnet 4.5 setzt neue Maßstäbe bei Codierungs-Benchmarks. Es zeichnet sich durch seine Leistungsfähigkeit im gesamten Softwareentwicklungszyklus aus, von der ersten Planung und dem Systemdesign bis hin zum komplexen Debugging.
- 🕑 Erweiterter autonomer Betrieb: Es kann über 30 Stunden selbstständig an komplexen, mehrstufigen Aufgaben arbeiten. Dabei behält es stets den Überblick und liefert regelmäßige Fortschrittsberichte, wodurch die Zuverlässigkeit für langlaufende, kritische Arbeitsabläufe gewährleistet wird.
- 🧠 Hybride Argumentationsarchitektur: Integriert einen leistungsstarken erweiterten Denkmodus zur Steigerung der Leistung bei komplexen Programmier- und Denkaufgaben, ergänzt durch einen standardmäßigen schnellen Denkmodus für mehr Effizienz.
- 🔒 Verbesserte Sicherheit: Integriert robuste Sicherheitsarchitektur und fortschrittliche Schwachstellenerkennung. Dies reduziert Risiken in sensiblen Programmierbereichen und kritischen Finanzanwendungen erheblich.
- 📚 Umfassende Fachkenntnisse: Zeigt deutliche Verbesserungen im domänenspezifischen Denken über alle Bereiche hinweg Finanzen, Cybersicherheit, Medizin und MINT-Bereicheund ermöglicht so anspruchsvolle Anwendungen in der realen Welt.
💲 Claude 4.5 Sonnet API-Preise
| Preiskennzahl | Kosten pro Million Token |
|---|---|
| Basis-Eingabetoken | 3,15 € |
| 5 Minuten Cache-Schreibvorgänge | 3,9375 USD |
| 1 Stunde Cache-Schreibvorgänge | 6,30 € |
| Cache-Treffer und Aktualisierungen | 0,315 $ |
| Ausgabetoken | 15,75 $ |
🎯 Wichtigste Anwendungsfälle
- 💻 Programmierhilfe: Unterstützung beim Schreiben, Debuggen und Überprüfen von komplexem, mehrstufigem Code über längere Sitzungen hinweg.
- 🧠 Autonome Agenten: Verwaltung komplexer Arbeitsabläufe, die mehrere Softwaretools und diverse Datenquellen koordinieren.
- 💰 Finanzanalyse-Agenten: Fachgerechtes Parsen und Analysieren großer Datensätze mit spezialisiertem Domänenwissen.
- 🔒 Automatisierung der Cybersicherheit: Verbesserung der Schwachstellenerkennung und Automatisierung der Skripterstellung für die Bedrohungsabwehr.
- 🔍 Unterstützung bei der Recherche: Erleichterung der Multiagentenkoordination für fortgeschrittene Datensynthese- und Zusammenfassungsaufgaben.
💻 Codebeispiel
Nachfolgend ein Beispiel für die Interaktion mit der Claude 4.5 Sonnet API:
import anthropic client = anthropic.Anthropic( # Standardwert ist os.environ.get("ANTHROPIC_API_KEY") api_key="my_api_key", ) message = client.messages.create( model="claude-sonnet-4.5", max_tokens=1024, messages=[ {"role": "user", "content": "Erklären Sie die Vorteile des Quantencomputings in einfachen Worten."} ] ) print(message.content) 🆚 Vergleich mit anderen Modellen
Claude Sonett 4.5 vs. GPT-5
Claude Sonnet 4.5 gilt weithin als überlegenes Codierungsmodell für praktische Anwendungen und übertrifft GPT-5 Codex in Live-Codierungstests und Benchmarks häufig. Während GPT-5 bei einigen abstrakten Denkaufgaben auf hohem Niveau leichte Vorteile bieten mag, glänzt Sonnet 4.5 bei komplexen, mehrstufigen Codierungen und vereint Geschwindigkeit mit bemerkenswerter Genauigkeit. Obwohl Sonnet 4.5 einen höheren Preis hat, bietet es hohe Zuverlässigkeit und erweiterte Sicherheitsfunktionen.
Claude Sonett 4.5 vs. Qwen3-Next-80B
Sonnet 4.5 übertrifft Qwen3-Next-80B in realen Programmier- und autonomen Agenten-Benchmarks und bietet höhere Genauigkeit sowie tiefergehende Schlussfolgerungsfähigkeiten. Qwen3 ist zwar auf Durchsatzeffizienz optimiert, verfügt aber nicht über die fortschrittliche Multiagenten-Unterstützung und das spezialisierte Domänenwissen von Sonnet 4.5. Darüber hinaus bietet Sonnet 4.5 überlegene Sicherheitsprotokolle und ein größeres Kontextfenster.
Claude Sonett 4.5 vs. Gemini 2.5 Pro
Claude Sonnet 4.5 übertrifft Gemini 2.5 Pro in Programmier-Benchmarks deutlich und erzielt ein beeindruckendes Ergebnis. 77,2 % Genauigkeit im SWE-Benchmark im Vergleich zu 63,8 % bei Gemini.Es unterstützt außerdem einen längeren autonomen Betrieb (über 30 Stunden) und bietet überlegenes Multitasking in agentenbasierten Szenarien, was es zur bevorzugten Wahl für komplexe Softwareentwicklung und fortschrittliche KI-Agenten-Workflows macht.
Claude Sonett 4.5 vs. Opus 4.1
Sonett 4.5 stellt einen deutlichen Fortschritt gegenüber Anthropics vorherigem Opus 4.1 dar und demonstriert nahezu eine 20% Steigerung bei realen KI-Computeraufgaben und verbesserte Codierungsgenauigkeit. Das neuere Modell integriert die Nutzung fortschrittlicher Multiagenten-Tools und bietet erweiterte Kontextfenster, wodurch sowohl die Genauigkeit als auch die nachhaltige Aufgabenausführung verbessert werden.

Ein vergleichender Blick auf Claude 4.5 Sonett im Vergleich zu anderen führenden KI-Modellen.
🔗 API-Integration
Claude 4.5 Sonett ist über eine KI/ML-API leicht zugänglich. Eine umfassende Dokumentation ist verfügbar. Hier verfügbarWir begleiten Sie durch die nahtlose Integration in Ihre bestehenden Systeme.
❓ Häufig gestellte Fragen (FAQ)
Was macht Claude 4.5 Sonnet ideal für die Entwicklung komplexer Software?
Claude 4.5 Sonnet basiert auf einer hybriden Architektur für logisches Denken und fortschrittlichem Langzeitkontextmanagement und eignet sich daher hervorragend für mehrstufige Codierung, Systemdesign und Debugging. Die im SWE-Benchmark verifizierte Genauigkeit von 77,2 % unterstreicht die überragende Leistungsfähigkeit über den gesamten Softwareentwicklungszyklus hinweg und macht es zur ersten Wahl für komplexe Projekte.
Wie gewährleistet Claude 4.5 Sonett langfristige Aufgabenkonsistenz und Konzentration?
Das Modell zeichnet sich durch eine außergewöhnliche Langzeit-Statusverfolgung mittels eines fortschrittlichen Kontextfensters und der Berücksichtigung des Status externer Dateien aus. Dadurch kann es Fokus und Kohärenz über Sitzungen hinweg aufrechterhalten, die sich über Stunden oder sogar Tage erstrecken – ein entscheidender Faktor für komplexe Projekte, die kontinuierliche Aufmerksamkeit und inkrementelle Fortschrittsaktualisierungen erfordern.
Was sind die wichtigsten Unterschiede zwischen Claude 4.5 Sonnet und anderen führenden KI-Modellen wie GPT-5 oder Gemini 2.5 Pro?
Claude 4.5 Sonnet übertrifft Modelle wie GPT-5 und Gemini 2.5 Pro in praktischen Programmier-Benchmarks und Aufgaben mit autonomen Agenten im Allgemeinen. Beispielsweise erreicht es im SWE-Benchmark eine Genauigkeit von 77,2 % im Vergleich zu Geminis 63,8 % und bietet überlegene Langzeit-Autonomie (über 30 Stunden) sowie Fähigkeiten zur Multiagenten-Koordination. Es legt Wert auf Zuverlässigkeit und Sicherheit und ist daher eine robuste Wahl für Anwendungen im Unternehmensbereich.
Kann Claude 4.5 Sonett für risikoreiche Anwendungen wie Finanzen und Cybersicherheit verwendet werden?
Absolut. Claude 4.5 Sonnet wurde für anspruchsvolle reale Umgebungen entwickelt und integriert robuste Sicherheitsfunktionen, Schwachstellenerkennung und signifikante Verbesserungen im domänenspezifischen Denken in den Bereichen Finanzen und Cybersicherheit. Dank seiner erhöhten Genauigkeit, Zuverlässigkeit und Sicherheit eignet es sich hervorragend für sensible Anwendungen, die strenge Leistungs- und Ethikstandards erfordern.
Was ist der „erweiterte Denkmodus“ und wie wirkt er sich positiv auf die Problemlösung aus?
Der erweiterte Denkmodus ist ein Alleinstellungsmerkmal von Claude 4.5 Sonnet, das eine tiefere kognitive Verarbeitung für komplexes Denken, mehrstufige Codierung und agentenbasierte Arbeitsabläufe ermöglicht. Durch die Zuweisung zusätzlicher Rechenressourcen für Introspektion und vertieftes Nachdenken wird die Leistung bei anspruchsvollen Aufgaben deutlich gesteigert und eine präzisere und differenziertere Problemlösung gewährleistet, allerdings mit nur geringfügigen Auswirkungen auf die Latenz.
KI-Spielplatz

