 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banane
Google - Gemini, Nano Banane Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance – Das Beste von ByteDance
ByteDance – Das Beste von ByteDance Alle Modelle
Alle Modelle Unternehmenspläne
Unternehmenspläne KI-Anwendungsentwicklung
KI-Anwendungsentwicklung KI-Übersetzer-API
KI-Übersetzer-API KI-SEO/GEO-Dienst
KI-SEO/GEO-Dienst Geooptimierter PR-Service
Geooptimierter PR-Service Web-Scraping-Dienst
Web-Scraping-Dienst OpenClaw
OpenClaw Die besten KI-Tools
Die besten KI-Tools Top-KI-Roboter
Top-KI-Roboter
 Einloggen
Einloggen



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'deepseek/deepseek-v3.2-speciale',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2-speciale",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Produktdetails
DeepSeek V3.2 Spezial ist ein hochentwickeltes, auf logisches Denken ausgerichtetes großes Sprachmodell (LLM), das für die hervorragende Lösung mehrstufiger logischer Probleme und die Verarbeitung umfangreicher Kontexte entwickelt wurde. Mit einem beeindruckenden Kontextfenster von bis zu 128.000 TokenEs ist für komplexe Analyseaufgaben konzipiert. Ein bahnbrechendes Merkmal ist die "Nur-Denkmodus"Dadurch kann das Modell im Hintergrund interne Schlussfolgerungen ziehen, bevor es eine Ausgabe generiert. Dieser innovative Ansatz verbessert die Genauigkeit, die faktische Kohärenz und die schrittweise Deduktion deutlich, insbesondere bei komplexen Anfragen.
Dieses Modell entspricht den Chat-Prefix/FIM-Vervollständigungsspezifikationen von DeepSeek und bietet leistungsstarke Funktionen zum Aufruf von Tools. Es ist über einen Speciale-Endpunkt für begrenzte Zeiträume zugänglich und schließt die Lücke zwischen Spitzenforschung und praktischen KI-Anwendungen. So gewährleistet es analytische Konsistenz in verschiedenen Bereichen wie Codegenerierung, mathematischen Berechnungen und wissenschaftlicher Forschung.
✨ Technische Spezifikationen ✨
- ✅ Architektur: Textbasiertes Denken LLM
- ✅ Kontextlänge: 128.000 Token
- ✅ Fähigkeiten: Chat, fortgeschrittenes logisches Denken, Werkzeugnutzung, FIM-Abschluss
- ✅ Trainingsdaten: Optimierte Datensätze für logisches Denken, Abstimmung mit menschlichem Feedback
🧠 Leistungsbenchmarks 🧠
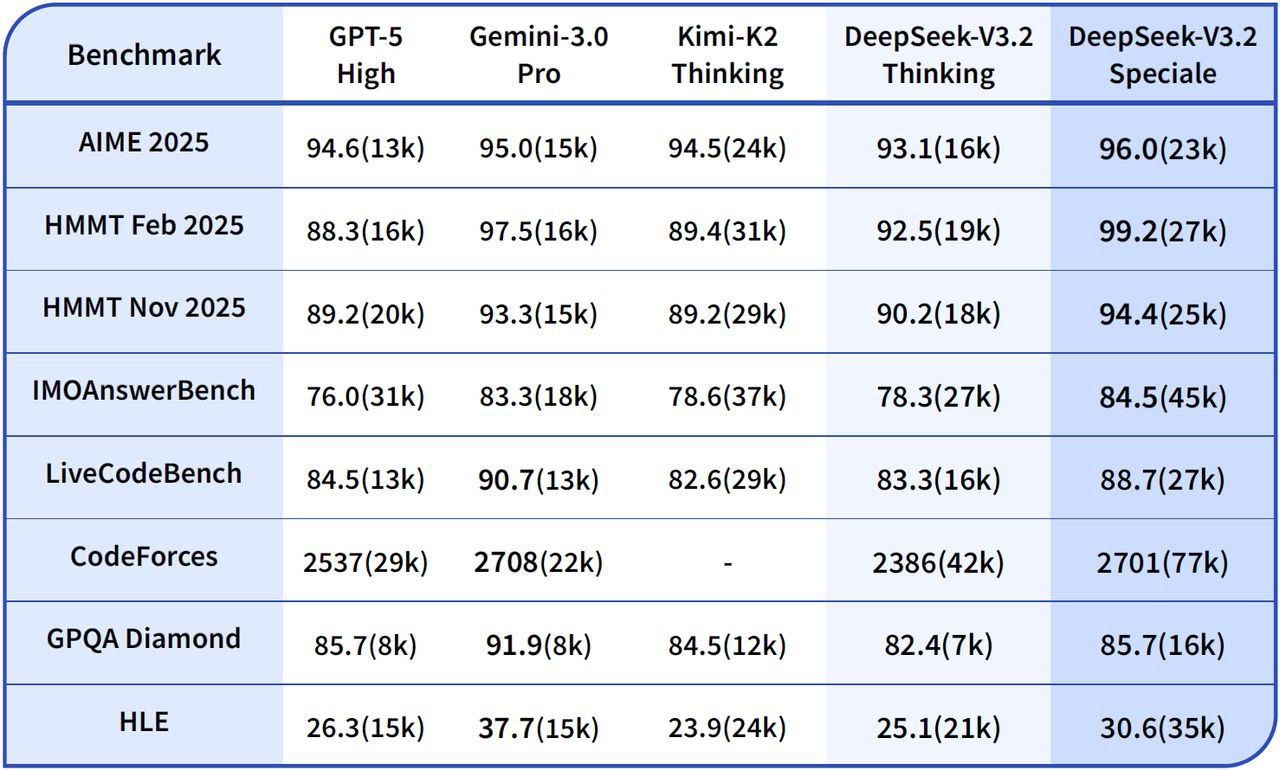
- 📈 Komplexes Denken: Zeigt verbesserte Stabilität bei mehrstufigen Ketten, einschließlich mathematischer und symbolischer Aufgaben.
- 💻 Code-Synthese / Debugging: Bietet eine bessere Nachvollziehbarkeit der Ablaufverfolgung und unterstützt so Entwicklungs- und Debugging-Prozesse.
💡 Ausgabequalität & Argumentationsleistung 💡
🌟 Qualitätsverbesserungen
- ✔️ Kohärentes Denken: Konsistente Argumentationsstränge gewährleisten Kohärenz über mehr als 100.000 Token hinweg.
- ✔️ Verbesserte Fehlerbehebung: Verbesserte Fehlerbehebung bei langen Ketten durch adaptive Aufmerksamkeitssteuerung.
- ✔️ Überlegene symbolische Genauigkeit: Übertrifft frühere DeepSeek-Modelle in multivariater Logik und Code-Inferenz.
- ✔️ Ausgewogener, analytischer Ton: Liefert präzise Erklärungen und reduziert gleichzeitig Überanpassungen oder semantische Abweichungen.
⚠️ Einschränkungen
- Formeller Ton: Kann bei alltäglichen Aufgaben übermäßig formell oder steif klingen.
- Erhöhte Latenz: Der „Nur-Denkmodus“ erhöht die Latenz bei hochkomplexen Ketten geringfügig.
- Begrenzte kreative Variation: Geringe Variation des kreativen Tons im Vergleich zu erzählerisch orientierten LLM-Programmen.
🚀 Neue Funktionen & technische Verbesserungen 🚀
DeepSeek-V3.2-Speciale führt bahnbrechende Reasoning-Frameworks und interne Optimierungsschichten ein, die für überlegene Stabilität, Interpretierbarkeit und Genauigkeit im Langzeitkontext entwickelt wurden.
Wichtige Verbesserungen
- 🧠 Nur-Denk-Modus: Fügt einen stillen kognitiven Filter vor der für den Benutzer sichtbaren Ausgabe hinzu, wodurch Widersprüche und Halluzinationen drastisch reduziert werden und zuverlässigere Ergebnisse erzielt werden.
- 📏 Erweitertes Kontextfenster (128 KB): Ermöglicht die umfassende Synthese langer Dokumente, das nachhaltige Speichern von Dialogen und datengestütztes Schließen über mehrere Quellen hinweg.
- 🔍 Interne Kettenprüfung: Bietet eine verbesserte Nachvollziehbarkeit der Schlussfolgerungen, was für Forscher, die mehrstufige Schlussfolgerungen validieren und Transparenz gewährleisten, von unschätzbarem Wert ist.
- ✏️ FIM (Fill-in-the-Middle) Fertigstellung: Ermöglicht kontextbezogene Einfügungen und strukturierte Codekorrekturen, ohne dass eine vollständige, sofortige Neuvorlage erforderlich ist, und steigert so die Effizienz der Entwickler.
Praktische Auswirkungen
Diese bedeutenden Verbesserungen führen zu einer höheren Interpretationstiefe in Mathematik, wissenschaftlicher Logik und komplexen Analyseaufgaben. DeepSeek V3.2 Speciale eignet sich daher ideal für anspruchsvolle Automatisierungsprozesse und fortgeschrittene kognitive Forschungsexperimente.
💰 API-Preise 💰
- Eingang: 0,2977 US-Dollar pro 1 Million Token
- Ausgabe: 0,4538 US-Dollar pro 1 Million Token
💻 Codebeispiel 💻
# Beispiel-Python-Code für den DeepSeek V3.2 Speciale API-Aufruf import openai client = openai.OpenAI( base_url="https://api.deepseek.com/v1", api_key="YOUR_API_KEY" ) response = client.chat.completions.create( model="deepseek/deepseek-v3.2-speciale", messages=[ {"role": "user", "content": "Erklären Sie das Konzept der Quantenverschränkung Schritt für Schritt logisch."}, {"role": "assistant", "content": "(Nur-Denk-Modus aktiviert: Anfrage dekonstruieren, Schlüsselkonzepte identifizieren, logischen Ablauf planen, relevante physikalische Prinzipien abrufen, Erklärung in einzelne Schritte gliedern.)"} ], # Der 'Nur-Denk-Modus' ist ein interner Mechanismus. # Der API-Aufruf selbst bleibt Standard, aber die interne Verarbeitung des Modells ändert sich. temperature=0.7, max_tokens=500 ) print(response.choices[0].message.content) 🆚 Vergleich mit anderen Modellen 🆚
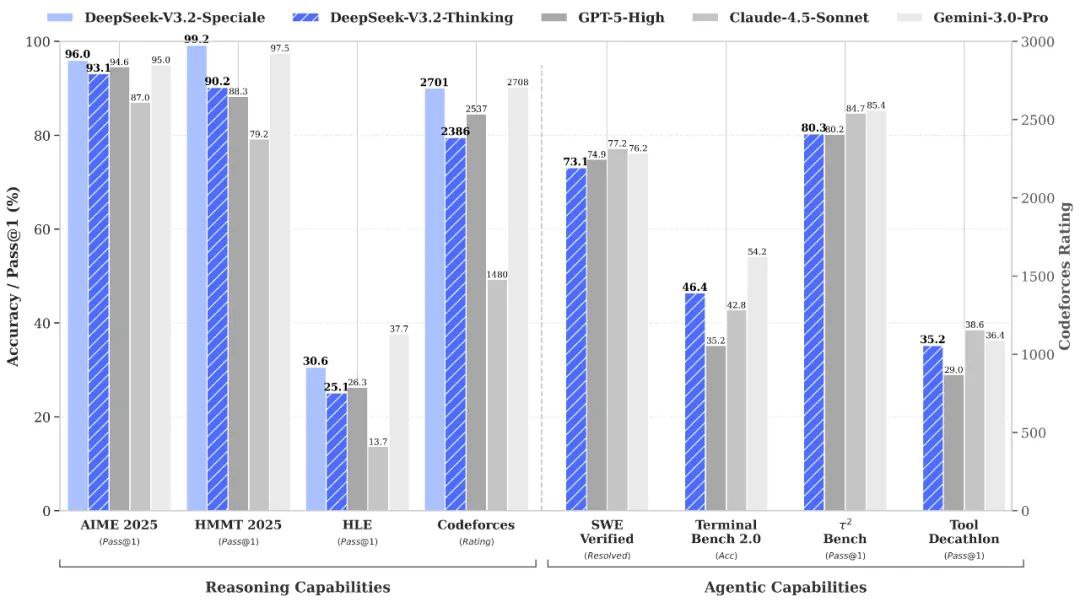
DeepSeek V3.2 Spezial vs. Gemini-3.0-Pro: Benchmarks zeigen, dass DeepSeek-V3.2-Speciale eine vergleichbare Gesamtleistung wie Gemini-3.0-Pro erzielt. DeepSeek legt jedoch einen deutlich stärkeren Fokus auf transparentes, schrittweises Schließen, was es besonders vorteilhaft für Anwendungen mit agentenbasierter KI macht.
DeepSeek V3.2 Spezial vs. GPT-5: Laut vorliegenden Evaluierungen liegt DeepSeek-V3.2-Speciale bei anspruchsvollen Logikaufgaben, insbesondere bei mathematikintensiven und wettbewerbsorientierten Benchmarks, vor GPT-5. Auch in puncto Zuverlässigkeit bei der Programmierung und der Werkzeugnutzung zeigt es eine hohe Wettbewerbsfähigkeit und stellt somit eine überzeugende Alternative für komplexe Aufgaben dar.
DeepSeek V3.2 Spezial vs. DeepSeek-R1: Speciale wurde für noch extremere Denkszenarien entwickelt und verfügt über ein 128K Kontextfenster sowie einen rechenintensiven „Denkmodus“. Dadurch eignet es sich hervorragend für fortgeschrittene agentenbasierte Frameworks und Benchmark-Experimente und unterscheidet sich somit von DeepSeek-R1, das für den eher alltäglichen interaktiven Einsatz konzipiert ist.
💬 Feedback aus der Community 💬
Nutzerfeedback auf Plattformen wie Reddit DeepSeek V3.2 Speciale wird immer wieder als herausragend für anspruchsvolle Logikaufgaben hervorgehoben. Entwickler loben insbesondere seine Benchmark-Dominanz und beeindruckende Kosteneffizienz und heben seine Überlegenheit gegenüber GPT-5 bei Mathematik-, Programmier- und Logik-Benchmarks hervor, oft zu einem deutlich niedrigeren Preis. 15-mal geringere KostenViele beschreiben es als „hervorragend“ für agentenbasierte Arbeitsabläufe und die Lösung komplexer Probleme. Anwender loben zudem die beeindruckende Kohärenz in langen Verarbeitungsketten, die deutlich reduzierten Fehler und die „menschenähnliche“ Tiefenwahrnehmung, insbesondere im Vergleich zu früheren DeepSeek-Versionen.
❓ Häufig gestellte Fragen (FAQ) ❓
Frage 1: Worauf liegt der Hauptfokus von DeepSeek V3.2 Speciale?
A1: Der Schwerpunkt liegt auf fortgeschrittenem Denken und mehrstufiger logischer Problemlösung, die für komplexe analytische Aufgaben in den Bereichen Programmierung, Mathematik und Naturwissenschaften konzipiert ist.
Frage 2: Wie funktioniert der „Nur-Denk“-Modus?
A2: Dieser Modus ermöglicht es dem Modell, im Hintergrund interne Schlussfolgerungen zu ziehen, bevor sichtbare Ausgaben generiert werden. Dieser interne kognitive Prozess verbessert die Genauigkeit, die faktische Kohärenz und den logischen Ablauf der Antworten deutlich, insbesondere bei komplexen Anfragen.
Frage 3: Was ist die maximale Kontextlänge für DeepSeek V3.2 Speciale?
A3: DeepSeek V3.2 Speciale unterstützt ein erweitertes Kontextfenster von bis zu 128K Tokens, wodurch es sehr lange Dokumente verarbeiten, einen nachhaltigen Dialogspeicher aufrechterhalten und datengesteuerte Schlussfolgerungen über mehrere Quellen hinweg durchführen kann.
Frage 4: Wie verhält sich die Preisgestaltung im Vergleich zu anderen Modellen?
A4: Rückmeldungen aus der Community lassen darauf schließen, dass DeepSeek V3.2 Speciale eine sehr wettbewerbsfähige Preisgestaltung bietet. Entwickler berichten, dass die Kosten für vergleichbare komplexe Aufgaben bis zu 15-mal niedriger sein können als bei einigen Konkurrenten wie GPT-5.
Frage 5: Ist DeepSeek V3.2 Speciale für kreative Schreibaufgaben geeignet?
A5: Obwohl es analytisches Denken hervorragend fördert, weist es im Vergleich zu erzählerisch orientierten LLM-Programmen eine geringere kreative Ausdrucksfähigkeit auf. Es kann für informelle oder besonders kreative Aufgaben zu formell oder starr wirken.
KI-Spielplatz

