 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banane
Google - Gemini, Nano Banane Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance – Das Beste von ByteDance
ByteDance – Das Beste von ByteDance Alle Modelle
Alle Modelle Unternehmenspläne
Unternehmenspläne KI-Anwendungsentwicklung
KI-Anwendungsentwicklung KI-Übersetzer-API
KI-Übersetzer-API KI-SEO/GEO-Dienst
KI-SEO/GEO-Dienst Geooptimierter PR-Service
Geooptimierter PR-Service Web-Scraping-Dienst
Web-Scraping-Dienst OpenClaw
OpenClaw Die besten KI-Tools
Die besten KI-Tools Top-KI-Roboter
Top-KI-Roboter
 Einloggen
Einloggen



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'x-ai/grok-4-1-fast-non-reasoning',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="x-ai/grok-4-1-fast-non-reasoning",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Produktdetails
🚀 Grok 4.1 Fast API: Ultraschnelles, nicht-logisches LLM für effiziente Arbeitsabläufe
Der Grok 4.1 Fast Non-Reasoning API Das von xAI entwickelte Sprachmodell stellt einen bedeutenden Fortschritt in der Technologie großer Sprachmodelle dar und wurde speziell für beispiellose Geschwindigkeit und deterministische Text-zu-Text-Generierung entwickelt. Es eignet sich hervorragend für Umgebungen, in denen komplexes Schließen nicht im Vordergrund steht, sondern ultraschnelle Ausgabe und die Verarbeitung umfangreicher Kontextinformationen. Dank seines Designs ist es die ideale Lösung für Workflows mit hohem Datenvolumen, schnelle Stapelverarbeitung und Anwendungen, die konsistente Ergebnisse bei minimaler Latenz erfordern.
🔧 Technische Kernspezifikationen
- Modelltyp: Fortschrittliches Transformer-basiertes LLM (Text-zu-Text)
- Betriebsmodus: Nicht-logisches Denken (liefert direkte Ausgabe für höhere Geschwindigkeit)
- Latenz: Sofortige Inferenz mit extrem niedriger Latenz
- Sicherheitsprotokolle: Nutzt adversarial testing und umfassende mehrsprachige Evaluierungen, um eine robuste Leistungsfähigkeit über verschiedene Sprachen hinweg, einschließlich Englisch, Spanisch, Chinesisch, Japanisch, Arabisch und Russisch, zu gewährleisten.
📊 Leistungshighlights & Benchmarks
Im Vergleich zu anderen Systemen zeigt Grok 4.1 Fast Non-Reasoning anhand wichtiger Kennzahlen durchweg überlegene Genauigkeit, Sicherheit und operative Effizienz. Es übertrifft seine Vorgänger und weist eine verbesserte Genauigkeit (erkennbar an niedrigeren Punktzahlen) in Tests mit 500 biografischen Fragen auf, die durch Web-Suchfunktionen ergänzt wurden.
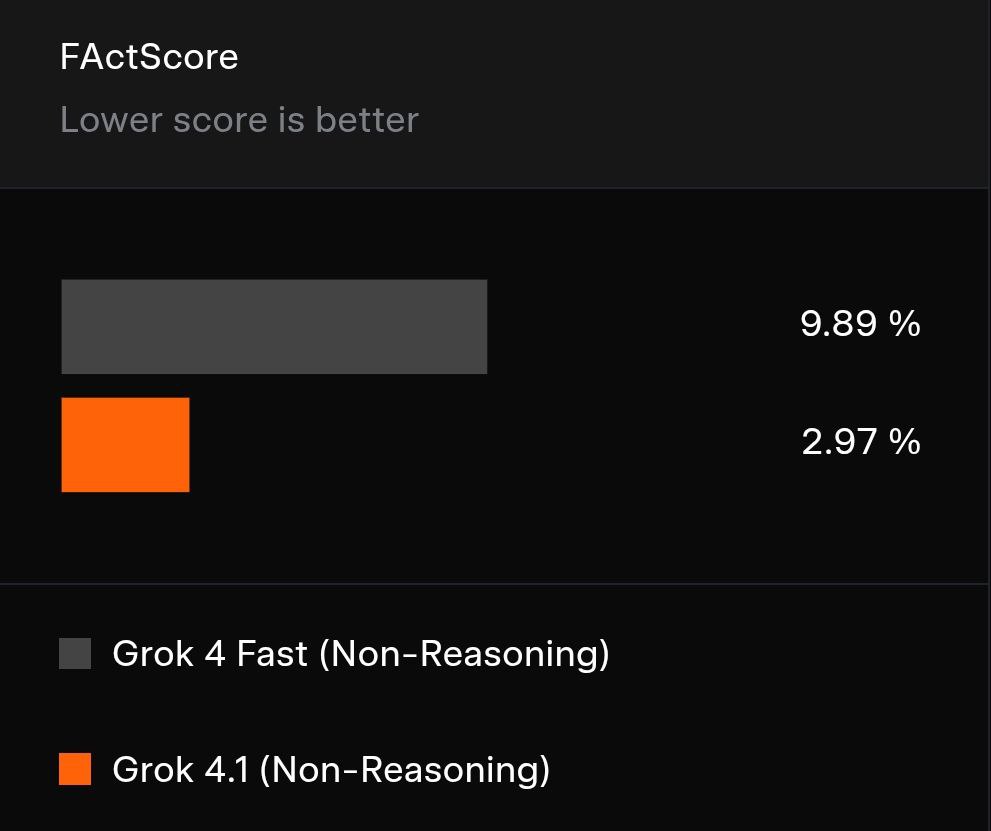
Visuelle Darstellung der Leistungsverbesserungen, die eine erhöhte Genauigkeit aufzeigt.
✅ Besondere Merkmale
- 📜 Verarbeitung extrem langer Kontexte: Verarbeitet nahtlos Dokumente und Konversationen von extrem langer Länge ohne jeglichen Kohärenzverlust.
- 🔄 Deterministische Ausgaben: Gewährleistet stabile und vorhersehbare Antworten auf identische Eingabeaufforderungen.
- 💭 Hohe faktische Genauigkeit: Optimiert für minimale Halluzinationen und maximale faktische Genauigkeit bei einfachen Anfragen.
- ⚠️ Optimiert für Geschwindigkeit: Priorisiert die schnelle Massenverarbeitung durch bewussten Verzicht auf den Einsatz von Werkzeugen oder fortgeschrittenen Denkfähigkeiten.
- 🚨 Erweiterte Sicherheit: Verfügt dank robuster Sicherheitsmechanismen über extrem niedrige Ablehnungs- und Ausbruchsraten.
💸 API-Preisstruktur
- Eingabe-Tokens: 0,21 US-Dollar pro 1 Million Token
- Ausgabetoken: 0,53 US-Dollar pro 1 Million Token
💡 Ideale Anwendungen & Anwendungsfälle
- 📝 Zusammenfassung eines langen Dokuments: Umfangreiche Forschungsarbeiten, juristische Dokumente oder Berichte schnell zusammenfassen.
- 💬 Verarbeitung des Gesprächsverlaufs: Effiziente Annotation und Verarbeitung großer Mengen an Chatprotokollen und Gesprächsdaten.
- 🔀 Massentextumwandlung: Führen Sie umfangreiche Aufgaben zur Inhaltsreformatierung, Umformulierung oder Datenextraktion durch.
- 🎤 Automatisierte Besprechungsprotokollierung & Suche: Generieren Sie Transkripte aus Audiodateien und ermöglichen Sie die schnelle Suche in umfangreichen Archiven.
- 🤖 Chatbots mit hohem Datenaufkommen: Leistungsstarke Kundenservice-Chatbots, die einfache, sich wiederholende Anfragen effizient bearbeiten.
💻 API-Codebeispiel (Python)
import openai client = openai.OpenAI( base_url="https://api.xai.com/v1", api_key="YOUR_API_KEY", # Ersetzen Sie dies durch Ihren tatsächlichen API-Schlüssel ) completion = client.chat.completions.create( model="x-ai/grok-4-1-fast-non-reasoning", messages=[ {"role": "system", "content": "Sie sind ein hilfreicher Assistent."}, {"role": "user", "content": "Fassen Sie die wichtigsten Funktionen von Grok 4.1 Fast in weniger als 50 Wörtern zusammen."} ], max_tokens=100 ) print(completion.choices[0].message.content) 🔍 Grok 4.1 Fast: Ein vergleichender Überblick
Die einzigartigen Stärken von Grok 4.1 Fast Non-Reasoning werden deutlicher, wenn man es mit anderen führenden Sprachmodellen vergleicht:
vs. Grok 4.1 Begründung: Grok 4.1 Fast priorisiert höchste Geschwindigkeit und deterministische Reaktionen, während die Variante „Reasoning“ für mehrstufige Logik und tiefergehende Analysen ausgelegt ist. Weitere Informationen finden Sie in der Dokumentation. Offizielle Grok 4.1 ProduktdokumentationDie
vs. DeepSeek V3.1: Grok 4.1 Fast bietet eine deutlich größere Kontextfenster mit 2 Millionen TokenDies ist ein massiver Vorteil gegenüber den 128k Tokens von DeepSeek V3.1 und macht es für die Verarbeitung umfangreicher Dokumente überlegen.
gegen Claude 4: Grok 4.1 Fast bietet ein wesentlich größeres Kontextfenster und verarbeitet bis zu 2 Millionen TokenClaude 4 operiert typischerweise in einem Kontext von 100.000 bis 200.000 Token.
vs. GPT-4o: GPT-4o ist ein vielseitiges Allzweckmodell, das sich durch robustes logisches Denken, Kreativität und fortgeschrittene Problemlösungsfähigkeiten auszeichnet. Grok 4.1 Fast hingegen beschränkt die Komplexität bewusst, um eine beispiellose Geschwindigkeit und deterministische Ergebnisse zu erzielen. Dadurch ist es die bevorzugte Wahl für Aufgaben mit hohem Durchsatz, die kein logisches Denken erfordern und bei denen die fortgeschrittenen Fähigkeiten von GPT-4o nicht benötigt werden.
❓ Häufig gestellte Fragen (FAQ)
Was ist Grok 4.1 Schnelles Nicht-Reasoning?
Grok 4.1 Fast Non-Reasoning ist ein umfangreiches Sprachmodell von xAI, optimiert für ultraschnelle, deterministische Textgenerierung und umfassende Kontextverarbeitung. Es ist für Aufgaben konzipiert, bei denen Geschwindigkeit und hoher Durchsatz wichtiger sind als komplexe interne Schlussfolgerungen.
Welche maximale Kontextfenstergröße wird von Grok 4.1 Fast unterstützt?
Grok 4.1 Fast Non-Reasoning unterstützt ein beeindruckendes Kontextfenster von bis zu 2 Millionen Tokens, wodurch es extrem lange Dokumente und Konversationen verarbeiten und verstehen kann, ohne an Kohärenz zu verlieren.
Wie gewährleistet Grok 4.1 Fast Sicherheit und Genauigkeit?
Es integriert robuste Sicherheitsmechanismen, darunter Adversarial Testing und mehrsprachige Auswertungen. Dies gewährleistet eine hohe faktische Genauigkeit bei einfachen Anfragen und hält die Ablehnungs- und Jailbreak-Raten extrem niedrig.
Welche Anwendungsarten profitieren am meisten von Grok 4.1 Fast?
Es eignet sich ideal für Aufgaben wie das Zusammenfassen langer Dokumente, die Verarbeitung umfangreicher Chatverläufe, die Massentexttransformation, die automatisierte Transkription von Besprechungen und die Bereitstellung unkomplizierter Chatbots mit hoher Kundeninteraktionsgeschwindigkeit.
Wie hoch sind die API-Preise für Grok 4.1 Fast?
Die API kostet 0,21 US-Dollar pro 1 Million Input-Tokens und 0,53 US-Dollar pro 1 Million Output-Tokens und bietet damit eine kostengünstige Lösung für den Bedarf an umfangreicher Textgenerierung.
KI-Spielplatz

