 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banane
Google - Gemini, Nano Banane Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance – Das Beste von ByteDance
ByteDance – Das Beste von ByteDance Alle Modelle
Alle Modelle Unternehmenspläne
Unternehmenspläne KI-Anwendungsentwicklung
KI-Anwendungsentwicklung KI-Übersetzer-API
KI-Übersetzer-API KI-SEO/GEO-Dienst
KI-SEO/GEO-Dienst Geooptimierter PR-Service
Geooptimierter PR-Service Web-Scraping-Dienst
Web-Scraping-Dienst OpenClaw
OpenClaw Die besten KI-Tools
Die besten KI-Tools Top-KI-Roboter
Top-KI-Roboter
 Einloggen
Einloggen



const axios = require('axios').default;
const api = axios.create({
baseURL: 'https://api.ai.cc/v1',
headers: { Authorization: 'Bearer ' },
});
const main = async () => {
const response = await api.post('/tts', {
model: 'inworld/tts-1-max',
text: 'OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.',
voice: 'coral',
});
console.log('Audio URL:', response.data.audio.url);
console.log('Characters:', response.data.usage.characters);
};
main();
import requests
def main():
url = "https://api.ai.cc/v1/tts"
headers = {
"Authorization": "Bearer ",
}
payload = {
"model": "inworld/tts-1-max",
"text": "OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.",
"voice": "coral"
}
response = requests.post(url, headers=headers, json=payload)
data = response.json()
print("Audio URL:", data["audio"]["url"])
print("Characters:", data["usage"]["characters"])
main()


Produktdetails
Inworld TTS-1-Max: Revolutionierung der Text-zu-Sprache-Technologie
Entdecken Sie die Inworld TTS-1-Max API, ein hochmodernes, auf Transformer basierendes autoregressives Text-to-Speech-Modell (TTS). Entwickelt für unübertroffene Sprachqualität und Ausdruckskraft, ist es die erste Wahl für professionelle und kommerzielle Anwendungen, die eine hochauflösende und nuancierte Sprachsynthese erfordern.
Mit einer beeindruckenden 8,8 Milliarden ParameterTTS-1-Max verschiebt die Grenzen der natürlichen Sprachgenerierung und erzeugt Stimmen, die von menschlicher Sprache praktisch nicht zu unterscheiden sind.
Technische Spezifikationen und Leistung
- ⚙️ Architektur: Erweitertes Transformer-basiertes autoregressives Modell
- 🔢 Parameter: Ein gewaltiges 8,8 Milliarden (das größte Modell der Inworld TTS-1-Familie)
- 🔊 Audioausgabe: Kristallklare, hochauflösende 48 kHz Rede
- 🌐 Unterstützte Sprachen: Umfassende Unterstützung für 11 Hauptsprachen
- ⚡ Inferenzgeschwindigkeit: Erreicht auf einem 32 H100-System etwa 8.000 Token pro Sekunde pro GPU und gewährleistet so hohe Effizienz.
Führend in den Qualitätsrankings
Das Modell TTS-1-Max zählt durchweg zu den Besten. Spitzenleister auf unabhängigen Qualitätsranglisten, die seine überlegene Leistung und Natürlichkeit in verschiedenen Bewertungen unter Beweis stellen.
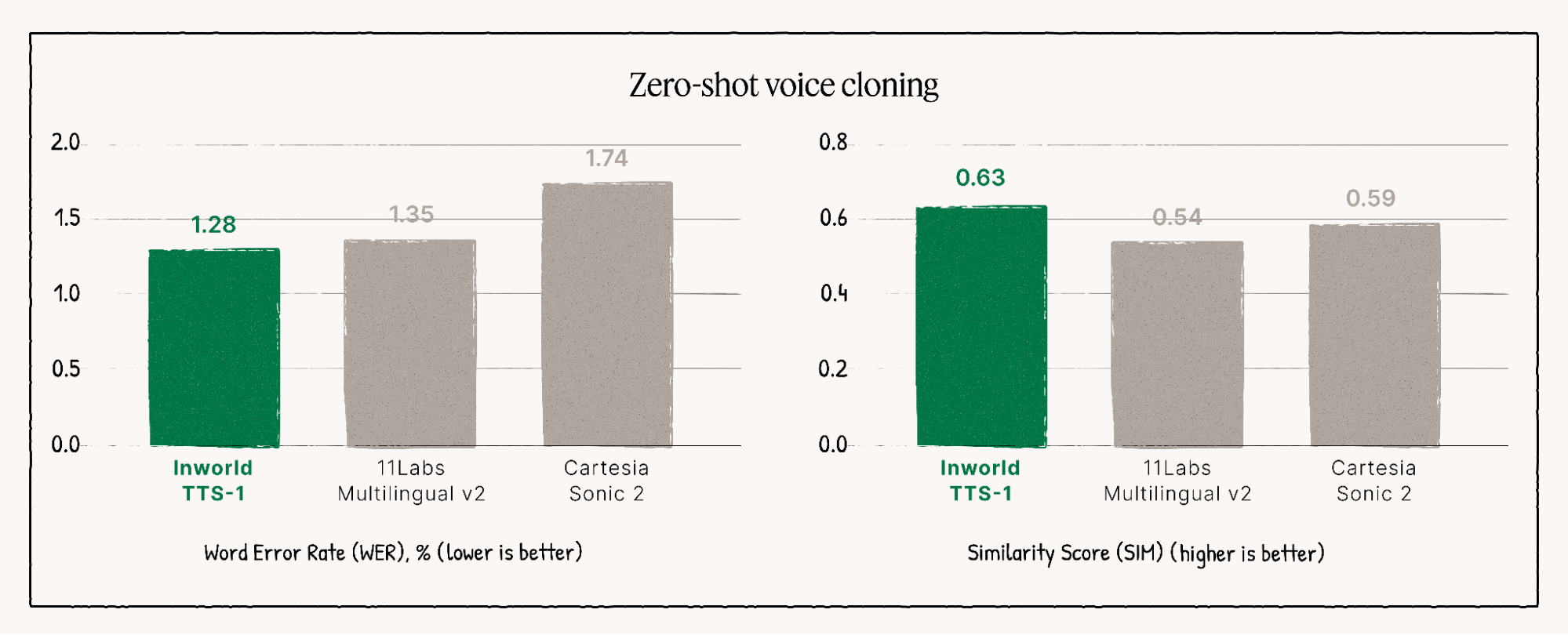
Hauptmerkmale für unübertroffene Sprachsynthese
- ✨ Überragende Natürlichkeit und Ausdruckskraft: Nutzt eine groß angelegte Parametrisierung für unglaublich natürliche und emotional reiche Sprachausgaben.
- 🗣️ Hochwertige mehrsprachige Synthese: Erzeugen Sie Sprache mit außergewöhnlicher Klarheit und Genauigkeit über 11 verschiedene Sprachen, ideal für globale Anwendungen.
- 🎭 Fortgeschrittene Emotionsmodulation: Verfeinern Sie Ihren Sprachstil mit leistungsstarken Funktionen zur emotionalen Modulation und verleihen Sie jeder Äußerung so eine tiefgründige Nuance und Bedeutung.
- 👂 Realistische nonverbale Geräusche und Lautäußerungen: Verbessert den Realismus der Sprache durch nahtlose Unterstützung verschiedener nonverbaler Signale und lässt KI-Stimmen dadurch lebensechter klingen.
- 👤 Reines kontextbezogenes Sprachklonen: Erreicht Stimmklonierung ohne die Notwendigkeit vorab aufgezeichneter Sprecherdaten und stützt sich ausschließlich auf ausgeklügeltes kontextbezogenes Lernen.
Transparente und wettbewerbsfähige API-Preisgestaltung
💰 Erleben Sie erstklassige Sprachsynthese mit unkomplizierter und transparenter Preisgestaltung:
- Kosten: Nur 10,5 $ pro 1 Million generierter Zeichen.
- Geschätzte Kosten pro Minute: Etwa 0,0105 USD pro Minute qualitativ hochwertiger, generierter Sprache.
Einfache Integration: Codebeispiel
Die Implementierung von Inworld TTS-1-Max in Ihre Anwendungen ist nahtlos. Nachfolgend finden Sie einen API-Ausschnitt für die schnelle Integration:
https://docs.ai.cc/api-references/speech-models/text-to-speech/inworld/tts-1-max " snippet data-name="voice.tts-openai" data-model="inworld/tts-1-max"> Für detaillierte Integrationsinformationen, erweiterte Parameter und weitere Codebeispiele konsultieren Sie bitte die offizielle Inworld TTS-1-Max API-DokumentationDie
Inworld TTS-1-Max: Wettbewerbsvorteil
Erfahren Sie, wie sich Inworld TTS-1-Max von anderen führenden Text-to-Speech-Modellen auf dem Markt abhebt und spezielle Vorteile für verschiedene Anwendungsfälle bietet.
🆚 vs. Inworld TTS-1
TTS-1-Max liefert überlegene Ausdruckskraft und Natürlichkeit Dank seiner deutlich größeren Parameterskala von 8,8 Milliarden (verglichen mit 1,6 Milliarden bei TTS-1) eignet es sich ideal für Premium-Inhalte wie Hörbücher. Im Gegensatz dazu priorisiert TTS-1 Echtzeitgeschwindigkeit (~153 Zeichen/Sekunde gegenüber ~69 Zeichen/Sekunde bei TTS-1-Max), wodurch es sich besser für hochgradig interaktive Anwendungen eignet.
🆚 vs. ElevenLabs Multilingual V2
In Qualitätstests erzielt TTS-1-Max einen 59,1 % Siegquote im direkten VergleichEs bietet eine feinere emotionale Differenzierung und robuste Unterstützung für nonverbale Geräusche durch Auszeichnungen. Während ElevenLabs eine starke mehrsprachige Klonung ermöglicht, ist TTS-1-Max führend in Rohaudioauflösung und die Reinheit seines kontextbezogenen Lernansatzes.
🆚 vs. MiniMax-Sprache
TTS-1-Max priorisiert Spitzen-Sprachqualität und zeichnet sich durch hohe Wiedergabetreue in allen elf unterstützten Sprachen aus und beweist damit seine Führungsrolle in Bezug auf Natürlichkeit und präzise Kontrolle der emotionalen Prosodie. MiniMax-Speech hingegen legt den Schwerpunkt auf umfassendere Zero-Shot-Klonfunktionen für 32 Sprachen und die schnelle One-Shot-Sprachreplikation.
Häufig gestellte Fragen (FAQ)
❓ Was ist Inworld TTS-1-Max?
Inworld TTS-1-Max ist eine hochmoderne, auf Transformer basierende autoregressive Text-to-Speech-API mit 8,8 Milliarden Parametern. Sie wurde für professionelle und kommerzielle Anwendungen entwickelt, die höchste Sprachqualität und Ausdrucksstärke erfordern.
❓ Was sind seine wichtigsten technischen Merkmale?
Es bietet eine autoregressive Transformer-Architektur, 8,8 Milliarden Parameter, 48 kHz hochauflösendes Audio, Unterstützung für 11 wichtige Sprachen und eine Inferenzgeschwindigkeit von etwa 8.000 Token/Sekunde pro GPU.
❓ Wie erreicht TTS-1-Max eine hohe Ausdruckskraft?
Seine außergewöhnliche Ausdruckskraft und Natürlichkeit beruhen auf seiner umfangreichen Parametrisierung mit 8,8 Milliarden Parametern, kombiniert mit Möglichkeiten zur emotionalen Modulation und der Unterstützung nonverbaler Geräusche, wodurch eine hochgradig nuancierte Sprache erzeugt wird.
❓ Wie sieht die Preisstruktur für die TTS-1-Max API aus?
Die API kostet 10,5 US-Dollar pro 1 Million Zeichen, was geschätzte Kosten von etwa 0,0105 US-Dollar pro Minute generierter Sprache ergibt.
❓ Was sind die idealen Anwendungsfälle für Inworld TTS-1-Max?
Es eignet sich perfekt für professionelle Voice-Overs, Synchronisationen, fortschrittliche Konversations-KI, die Produktion mehrsprachiger Medieninhalte, interaktive Sprachanwendungen, Hörbücher, Spiele und immersive virtuelle Umgebungen, in denen überragende Sprachqualität und Ausdruckskraft von größter Bedeutung sind.
KI-Spielplatz

