 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banane
Google - Gemini, Nano Banane Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance – Das Beste von ByteDance
ByteDance – Das Beste von ByteDance Alle Modelle
Alle Modelle Unternehmenspläne
Unternehmenspläne KI-Anwendungsentwicklung
KI-Anwendungsentwicklung KI-Übersetzer-API
KI-Übersetzer-API KI-SEO/GEO-Dienst
KI-SEO/GEO-Dienst Geooptimierter PR-Service
Geooptimierter PR-Service Web-Scraping-Dienst
Web-Scraping-Dienst OpenClaw
OpenClaw Die besten KI-Tools
Die besten KI-Tools Top-KI-Roboter
Top-KI-Roboter
 Einloggen
Einloggen



const axios = require('axios').default;
const api = axios.create({
baseURL: 'https://api.ai.cc/v1',
headers: { Authorization: 'Bearer ' },
});
const main = async () => {
const response = await api.post('/tts', {
model: 'hume/octave-2',
text: 'OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.',
voice: 'coral',
});
console.log('Audio URL:', response.data.audio.url);
console.log('Characters:', response.data.usage.characters);
};
main();
import requests
def main():
url = "https://api.ai.cc/v1/tts"
headers = {
"Authorization": "Bearer ",
}
payload = {
"model": "hume/octave-2",
"text": "OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.",
"voice": "coral"
}
response = requests.post(url, headers=headers, json=payload)
data = response.json()
print("Audio URL:", data["audio"]["url"])
print("Characters:", data["usage"]["characters"])
main()

.png)
Produktdetails
🚀 Octave 2: Text-to-Speech der nächsten Generation mit LLM-Technologie
Octave 2 stellt einen bedeutenden Fortschritt in der Text-to-Speech-Technologie (TTS) dar. Dank fortschrittlicher großer Sprachmodelle (LLMs) geht es über die einfache Textkonvertierung hinaus und versteht den Text tiefgehend. emotionale und semantische Nuancen Diese Intelligenz ermöglicht es Octave 2, ausdrucksstarke, menschenähnliche Sprache in Echtzeit zu generieren und setzt damit einen neuen Standard für Sprachqualität und Reaktionsfähigkeit in verschiedenen Anwendungen.
Octave 2 wurde für Vielseitigkeit entwickelt und liefert branchenführende Audioqualität mit extrem niedrige Latenz und umfassende Mehrsprachigkeitsunterstützung, wodurch es sich ideal für alles von dynamischer Konversations-KI bis hin zu immersiven Hörbüchern eignet.
⚙️ Technische Spezifikationen
- ✓ Unterstützte Sprachen: Englisch, Japanisch, Koreanisch, Spanisch, Französisch, Portugiesisch, Italienisch, Deutsch, Russisch, Hindi, Arabisch
- ✓ Latenz: Beeindruckend niedrig mit ~100 ms
- ✓ Stimmenklonen: Unterstützt wird dies bereits mit nur etwa 15 Sekunden Audioeingang.
- ✓ Audioformate: MP3, WAV, PCM
📈 Leistungsbenchmarks
- 📈 Octave 2 liefert 40 % schnellere Audioerzeugung Im Vergleich zum Vorgängermodell Octave 1 werden durchgehend Latenzen unter 200 Millisekunden erreicht.
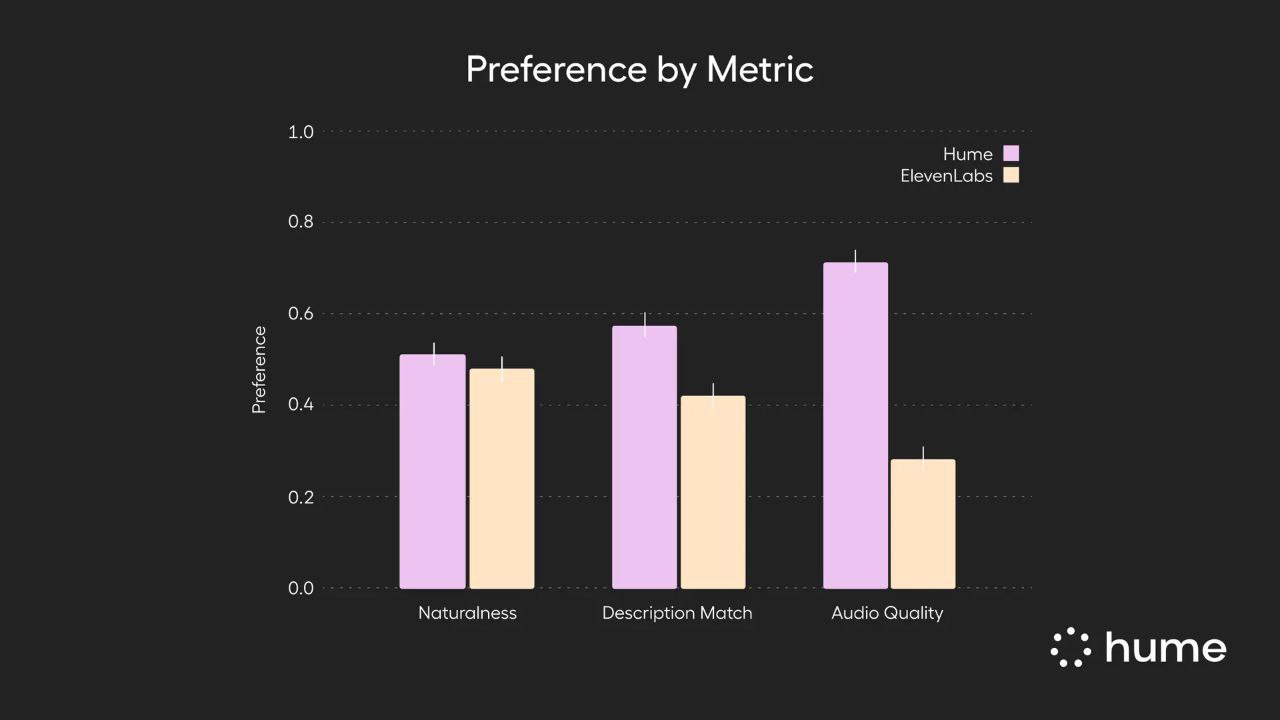
- 🎉 In Blindtests mit 180 menschlichen Testpersonen wurde Octave 2 gegenüber ElevenLabs Voice Design bevorzugt. Audioqualität (71,6 %), Natürlichkeit (51,7 %)und passende Sprachbeschreibungen (57,7%).
- 💬 Das Modell zeichnet sich durch seine Fähigkeit aus, komplexe Sprachmuster und subtile emotionale Veränderungen präzise wiederzugeben, wodurch die Natürlichkeit und Ausdruckskraft insgesamt deutlich gesteigert werden.
✨ Hauptmerkmale von Octave 2
- 💡 LLM-gestütztes emotionales Verständnis: Im Gegensatz zu herkömmlichen TTS-Systemen interpretiert Octave 2 die Bedeutung und die emotionale Absicht und passt Tonhöhe, Tempo und Betonung präzise an den Kontext an.
- 📣 Extrem niedrige Latenz: Erleben Sie Echtzeit-Sprachsynthese mit einer Modelllatenz von nur etwa 100 Millisekunden – perfekt für interaktive und dialogbasierte Anwendungen.
- 🌐 Mehrsprachige Unterstützung: Fließende und natürliche Sprachsynthese in 11 Schlüsselsprachen, darunter Englisch, Japanisch, Koreanisch, Spanisch, Französisch, Portugiesisch, Italienisch, Deutsch, Russisch, Hindi und Arabisch.
- 📚 Vielseitigkeit im Langformat: Gewährleistet einen gleichbleibenden emotionalen Ton und authentische Charakterstimmen in längeren Inhalten wie Hörbüchern und Podcasts und passt sich nahtlos an Szenenwechsel an.
- ⚙ Erweiterte Funktionen: Beinhaltet Sprachkonvertierung, direkte Phonembearbeitung und zuverlässige Aussprache für ungewöhnliche Wörter, Zahlen und Symbole.
💰 Octave 2 API-Preise
Einfache und transparente Preisgestaltung: 0,063 US-Dollar pro 1000 ZeichenDie
🎯 Vielfältige Anwendungsfälle
- 👤 Konversationelle KI & Interaktive Agenten: Echtzeit-Sprachausgabe mit emotionaler Sensibilität für Chatbots, virtuelle Assistenten und Kundenservice.
- 🎧 Hörbücher & Podcasts: Hochwertige, ausführliche Erzählung mit einheitlichem emotionalem Tonfall und angepasster Charakterstimme.
- 🎨 Stimmenklonen & Benutzerdefinierte Stimmen: Personalisierte Spracherstellung für Branding, Medienproduktion und Barrierefreiheitslösungen.
- 🎮 Gaming & Animation: Dynamische Charakterdialoge mit nuanciertem emotionalem Ausdruck erwecken virtuelle Welten zum Leben.
- 📞 Telefonie- und IVR-Systeme: Schnelle, natürlich klingende Ansagen und Antworten für automatisierte Telefonsysteme, die das Benutzererlebnis verbessern.
- 💪 Hilfsmittel zur Barrierefreiheit: Verbesserte Bildschirmleseprogramme und Sprachhilfen mit emotionalem und kontextbezogenem Sprachverständnis für eine breitere Inklusion.
🆚 Octave 2 im Vergleich zu führenden TTS-Modellen
Verstehen Sie, wie sich Octave 2 von anderen prominenten Text-to-Speech-Lösungen abhebt:
vs. ElevenLabs: Octave 2 nutzt die Intelligenz von LLM für ein tieferes emotionales und semantisches Verständnis und erzeugt so nuanciertere Sprache mit Echtzeit-Latenz (~100 ms). ElevenLabs bietet zwar natürliche und ausdrucksstarke Stimmen, verfügt aber in der Regel nicht über das fortschrittliche semantische Verständnis und die umfassendere Mehrsprachigkeitsunterstützung von Octave 2.
vs. OpenAI TTS: OpenAIs TTS zeichnet sich durch Klarheit, präzise Prosodiekontrolle und flexible Sprechstile dank Sprachausgabe aus. Octave 2 erweitert diese Funktionalität durch die Integration von Emotionserkennung auf semantischer Ebene, was zu einer deutlich natürlicheren Ausdruckskraft und mehr Kontexttiefe führt.
vs. Mozilla TTS: Mozilla TTS ist für Forschungszwecke und die Erstellung individueller Stimmen hochgradig anpassbar. Octave 2 hingegen, ein professionelles, LLM-basiertes System, bietet eine überlegene Sprachqualität direkt nach der Installation, eine schnellere Synthese sowie eine natürlichere emotionale Modulation und Echtzeit-Reaktionsfähigkeit.
vs. Schwätzer: Chatterbox ist für Dialoge mit geringer Latenz und konfigurierbare Ausdrucksfähigkeit mit effizienter Stimmklonierung in kleinerem Maßstab optimiert. Octave 2 übertrifft Chatterbox in semantischem Verständnis, emotionaler Tiefe, Konsistenz längerer Texte und umfassenden mehrsprachigen Funktionen und bietet so ein reichhaltigeres Echtzeit-Spracherlebnis.
❓ Häufig gestellte Fragen (FAQ)
F: Was unterscheidet Octave 2 von anderen Text-to-Speech-Systemen?
A: Octave 2 wird in einzigartiger Weise durch große Sprachmodelle (LLMs) unterstützt, die es ihm ermöglichen, den emotionalen und semantischen Kontext von Texten zu verstehen und so in Echtzeit ausdrucksstärkere und menschenähnlichere Sprache zu erzeugen, im Gegensatz zu herkömmlichen TTS-Modellen.
F: Wie gering ist die Latenz bei der Sprachgenerierung mit Octave 2?
A: Octave 2 zeichnet sich durch extrem niedrige Latenz aus und erreicht eine Echtzeit-Sprachsynthese mit einer Modelllatenz von nur etwa 100 Millisekunden, wodurch es sich ideal für interaktive Anwendungen eignet.
F: Unterstützt Octave 2 mehrere Sprachen?
A: Ja, Octave 2 bietet flüssige Sprachsynthese in 11 Sprachen, darunter Englisch, Japanisch, Koreanisch, Spanisch, Französisch, Portugiesisch, Italienisch, Deutsch, Russisch, Hindi und Arabisch.
F: Ist Octave 2 für längere Inhalte wie Hörbücher geeignet?
A: Absolut. Octave 2 ist auf Vielseitigkeit bei längeren Formaten ausgelegt und gewährleistet emotionale Konsistenz über längere Inhalte wie Hörbücher und Podcasts hinweg. Zudem passt es sich nahtlos an Charakter- und Szenenwechsel an.
F: Wie sieht die Preisstruktur für die Octave 2 API aus?
A: Die Octave 2 API ist zu einem wettbewerbsfähigen Preis von 0,063 US-Dollar pro 1000 generierten Zeichen erhältlich.
KI-Spielplatz

