 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banane
Google - Gemini, Nano Banane Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance – Das Beste von ByteDance
ByteDance – Das Beste von ByteDance Alle Modelle
Alle Modelle Unternehmenspläne
Unternehmenspläne KI-Anwendungsentwicklung
KI-Anwendungsentwicklung KI-Übersetzer-API
KI-Übersetzer-API KI-SEO/GEO-Dienst
KI-SEO/GEO-Dienst Geooptimierter PR-Service
Geooptimierter PR-Service Web-Scraping-Dienst
Web-Scraping-Dienst OpenClaw
OpenClaw Die besten KI-Tools
Die besten KI-Tools Top-KI-Roboter
Top-KI-Roboter
 Einloggen
Einloggen



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'alibaba/qwen3-next-80b-a3b-instruct',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="alibaba/qwen3-next-80b-a3b-instruct",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")

-p-130x130q80-p-130x130q80.png)
Produktdetails
Qwen3-Next-80B-A3B Anleitung ist ein hochentwickeltes, auf Anweisungen optimiertes großes Sprachmodell, das für außergewöhnliche Geschwindigkeit, Stabilität und die Verarbeitung extrem langer Kontexte bei hohem Durchsatz entwickelt wurde. Es erzielt signifikante Verbesserungen in Geschwindigkeit und Kosteneffizienz, indem nur ein kleiner Teil seiner 80 Milliarden Parameter aktiviert wird, ohne die Leistung in kritischen Bereichen wie komplexem Schließen und Codegenerierung zu beeinträchtigen.
⚙️ Technische Spezifikationen
Qwen3-Next-80B-A3B Instruct optimiert seine Abläufe durch Während der Inferenz werden nur etwa 3 Milliarden von 80 Milliarden Parametern aktiviert.Dieser sparsame Aktivierungsmechanismus bietet erhebliche Vorteile:
- Geschwindigkeit und Kosteneffizienz: Arbeitet etwa 10 Mal schneller und kostengünstiger als das Vorgängermodell Qwen3-32B.
- Durchsatz: Bietet einen über 10-mal höheren Durchsatz bei der Verarbeitung langer Kontexte von 32.000 Token oder mehr.
- Flexible Bereitstellung: Bietet vielseitige Bereitstellungsoptionen, darunter Serverless Hosting, On-Demand Dedicated Hosting und monatlich reserviertes Hosting.
- Bereitstellungskompatibilität: Kompatibel mit SGLang und vLLM für effiziente und skalierbare Nutzung, mit fortschrittlichen Multi-Token-Vorhersagefunktionen.
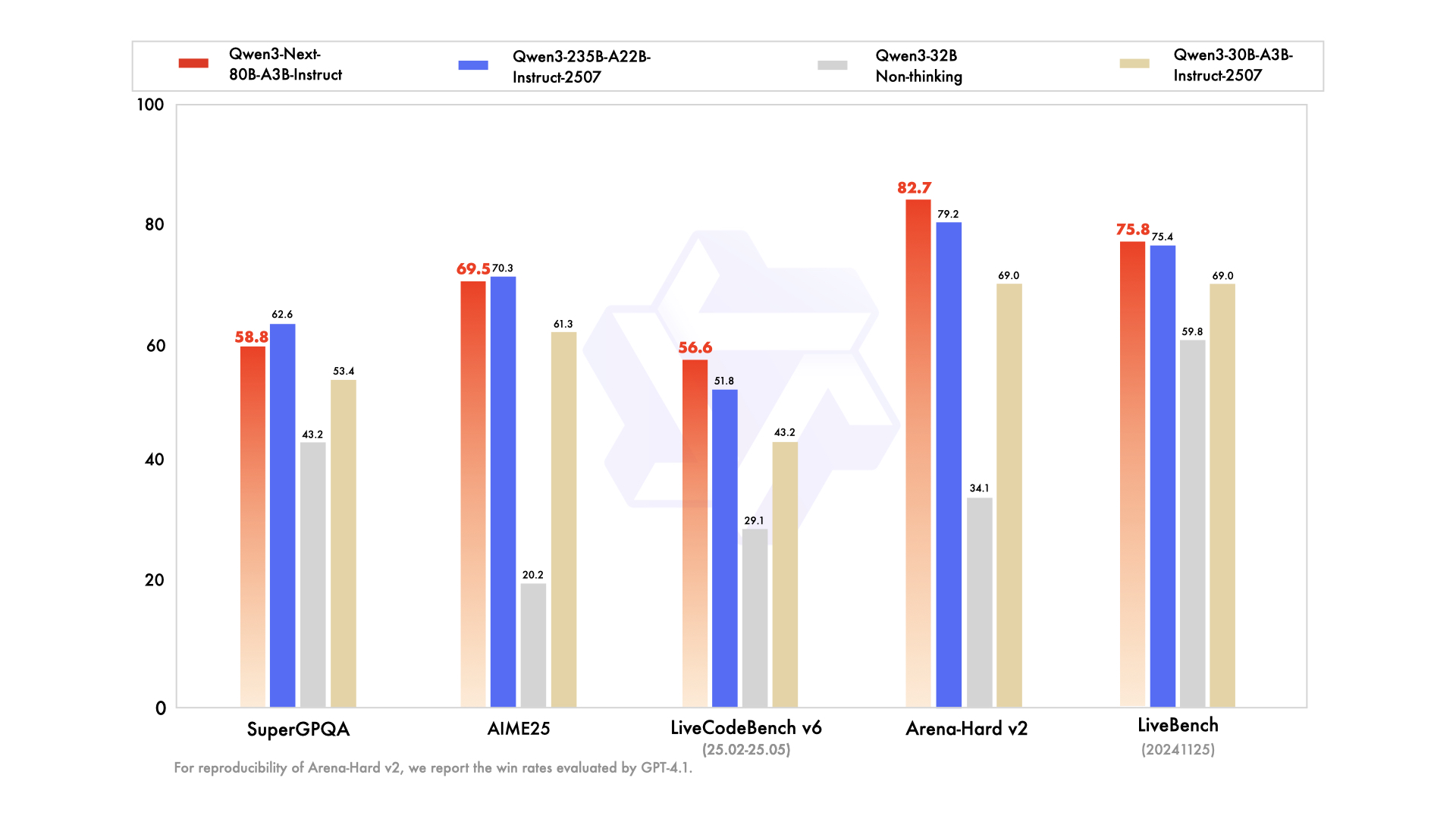
📊 Leistungsbenchmarks
- ✅ Spitzenleistung: Erreicht oder kommt der Leistung des Flaggschiffmodells Qwen3-235B bei verschiedenen Aufgaben in den Bereichen logisches Denken, Codevervollständigung und Befolgung von Anweisungen sehr nahe.
- ✅ Unerschütterliche Langzeitkontextverarbeitung: Liefert stets stabile und deterministische Ergebnisse und zeichnet sich insbesondere bei Aufgaben aus, die ein umfassendes Kontextverständnis erfordern.
- ✅ Ressourceneffizient: Übertrifft frühere mittelgroße, auf Anweisungen abgestimmte Modelle hinsichtlich der Effizienz und erzielt eine hohe Leistung mit weniger Rechenressourcen.
- ✅ Vielseitige Integration: Hervorragend geeignet für die Integration von Werkzeugen, Retrieval-Augmented Generation (RAG) und anspruchsvolle agentenbasierte Arbeitsabläufe, die konsistente Ergebnisse in Form von Gedankenketten erfordern.
💰 API-Preise
Eingang: 0,1575 USD
Ausgabe: 1,6 $
✨ Hauptkompetenzen
- 🚀 Hocheffiziente Inferenz: Verwendet eine spärliche Mixture-of-Experts (MoE)-Architektur, bei der dynamisch nur 3 Milliarden von 80 Milliarden Parametern aktiviert werden, um eine deutlich schnellere und kostengünstigere Inferenz zu ermöglichen.
- 🧠 Außergewöhnliche Aufgabenleistung: Ausgezeichnete Fähigkeiten in einer Vielzahl komplexer Aufgaben, darunter fortgeschrittenes logisches Denken, robuste Codegenerierung, präzise Beantwortung von Wissensfragen und vielseitige mehrsprachige Anwendungen.
- ⚡️ Stabile und schnelle Reaktionszeiten: Optimiert für den Instruktionsmodus, gewährleistet schnelle und konsistente Reaktionen ohne zwischenzeitliche Denkprozesse.
- 📖 Verarbeitung extrem langer Kontexte: Verfügt über eine native Kontextlänge von 262.000 Token, die mithilfe fortschrittlicher Skalierungstechnologie auf beeindruckende 1 Million Token erweitert werden kann.
- 📈 Hoher Durchsatz: Erreicht eine 10-fache Verbesserung des Durchsatzes bei der Verarbeitung umfangreicher langer Kontexte im Vergleich zu Vorgängermodellen.
- 💬 Kontinuierlicher Dialog & Antworten: Ideal für mehrstufige Dialoge und Aufgaben, die deterministische, konsistente Endergebnisse erfordern.
- 🛠️ Erweiterte Agenten-Workflows: Starke Leistungsfähigkeit für den Aufruf von Tools, die Ausführung mehrstufiger Aufgaben und anspruchsvolle agentenbasierte Arbeitsabläufe mit nahtlos integrierten Tools.
💡 Anwendungsfälle
- Codegenerierung: Beschleunigen Sie die Softwareentwicklung durch intelligente Codevorschläge und die Generierung vollständiger Codeblöcke.
- Inhaltserstellung und -bearbeitung: Erstellen Sie vielfältige Inhalte, von Artikeln bis hin zu Marketingtexten, und führen Sie anspruchsvolle Bearbeitungen anhand detaillierter Anweisungen durch.
- Datenanalyse: Erleichtert die Interpretation komplexer Daten, statistische Analysen und die Erstellung umfassender Berichte.
- Automatisierung des Kundenservice: Steigern Sie die Effizienz Ihres Kundensupports durch präzise Aufgabenbearbeitung und automatisierte Antworten.
- Technische Dokumentation: Optimieren Sie die Erstellung von technischen Dokumenten, Handbüchern und formatspezifischen Ausgaben.
- Prozessautomatisierung: Führe mehrstufige Aufgaben aus und integriere Tool-Aufrufe, um verschiedene Arbeitsabläufe zu automatisieren und zu optimieren.
- Längere Gespräche & Dokumentenbearbeitung: Effizientes Verwalten von ausführlichen Dialogen, Zusammenfassen großer Dokumente und Extrahieren wichtiger Informationen aus umfangreichen Texten.
💻 Codebeispiel
import openai client = openai.OpenAI( base_url="https://api.perplexity.ai", # Beispiel-Basis-URL, ersetzen Sie dies durch den tatsächlichen Endpunkt api_key="YOUR_API_KEY", # Ersetzen Sie dies durch Ihren tatsächlichen API-Schlüssel ) messages = [ { "role": "system", "content": "Sie sind Qwen3-Next-80B-A3B Instruct, ein hilfreicher KI-Assistent." }, { "role": "user", "content": "Erklären Sie das Konzept der Quantenverschränkung in einfachen Worten für einen Oberstufenschüler." }, ] response = client.chat.completions.create( model="alibaba/qwen3-next-80b-a3b-instruct", messages=messages, max_tokens=500, temperature=0.7, top_p=0.9, frequency_penalty=0, presence_penalty=0, ) print(response.choices[0].message.content) Hinweis: Die Werte für `base_url` und `api_key` im obigen Beispiel sind Platzhalter. Spezifische Integrationsdetails finden Sie in der offiziellen API-Dokumentation.
🆚 Vergleich mit anderen Modellen
Das 80B A3B-Modell bietet eine Leistung, die der des Flaggschiffmodells 235B bei Reasoning- und Codierungsaufgaben entspricht oder ihr sehr nahe kommt, ist aber deutlich effizienter, da weniger Parameter für eine schnellere und kostengünstigere Inferenz aktiviert werden.
Qwen3-Next bietet vergleichbare Fähigkeiten zur Befehlsverfolgung und zum Langzeitkontext, zeichnet sich jedoch durch einen höheren Durchsatz und eine größere Token-Fenstergröße aus und eignet sich daher besonders gut für umfangreiche Aufgaben zum Dokumentenverständnis.
Qwen3-Next zeigt überlegene Leistung bei mehrstufigen Dialogen und agentenbasierten Arbeitsabläufen und liefert im Vergleich zu Claudes Stärken in der Konversation deterministischere Ergebnisse bei sehr langen Kontexten.
Qwen3-Next zeigt eine bessere Skalierbarkeit bei der Verarbeitung extrem langer Kontexte und eine überlegene Effizienz bei der Vorhersage mehrerer Token, was ihm einen deutlichen Vorteil bei der Verarbeitung komplexer, mehrstufiger Schlussfolgerungsaufgaben verschafft.
❓ Häufig gestellte Fragen
Frage 1: Was macht Qwen3-Next-80B-A3B Instruct so außergewöhnlich effizient?
Das Modell nutzt eine sparsame Mixture-of-Experts-Architektur (MoE), die während der Inferenz nur etwa 3 Milliarden der 80 Milliarden Parameter aktiviert. Dieser innovative Ansatz führt zu einer deutlich schnelleren Verarbeitung und geringeren Betriebskosten und erzielt eine bis zu zehnmal höhere Effizienz als frühere Modelle.
Frage 2: Wie verhält es sich bei extrem langen Kontexten?
Qwen3-Next-80B-A3B Instruct unterstützt eine native Kontextlänge von 262.000 Tokens, die dank fortschrittlicher Skalierungstechnologie auf beeindruckende 1 Million Tokens erweitert werden kann. Diese Fähigkeit macht es ideal für Aufgaben, die ein tiefes Verständnis umfangreicher Dokumente und langer Konversationen erfordern.
Frage 3: Wie schneidet es im Vergleich zu anderen führenden Sprachmodellen ab?
Qwen3-Next-80B-A3B Instruct ist zwar hocheffizient, erreicht aber in komplexen Logik- und Codegenerierungsaufgaben die Leistung von Flaggschiffmodellen wie Qwen3-235B oder kommt ihr sehr nahe. Im Vergleich zu Modellen wie GPT-4.1, Claude 4.1 Opus und Gemini 2.5 Flash bietet es zudem vergleichbare oder sogar überlegene Fähigkeiten hinsichtlich Durchsatz, Verarbeitung langer Kontexte und deterministischer Ausgaben.
Frage 4: Was sind die Hauptanwendungsfälle für Qwen3-Next-80B-A3B Instruct?
Dieses Modell eignet sich hervorragend für Anwendungen, die hohen Durchsatz, präzise Befehlsausführung und umfassende Kontextverarbeitung erfordern. Zu den wichtigsten Anwendungsfällen gehören fortgeschrittene Codegenerierung, anspruchsvolle Inhaltserstellung, detaillierte Datenanalyse, automatisierter Kundenservice, technische Dokumentation und komplexe agentenbasierte Arbeitsabläufe.
Frage 5: Ist die Qwen3-Next-80B-A3B-Anweisung mit bestehenden Bereitstellungsinfrastrukturen kompatibel?
Ja, das Modell ist für die nahtlose Integration mit bestehenden Bereitstellungstools wie SGLang und vLLM konzipiert und unterstützt fortschrittliche Multi-Token-Vorhersagefunktionen. Es bietet zudem flexible Bereitstellungsoptionen, darunter serverloses Hosting, On-Demand-Hosting und monatlich reserviertes Hosting, um verschiedenen betrieblichen Anforderungen gerecht zu werden.
KI-Spielplatz

