 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banane
Google - Gemini, Nano Banane Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance – Das Beste von ByteDance
ByteDance – Das Beste von ByteDance Alle Modelle
Alle Modelle Unternehmenspläne
Unternehmenspläne KI-Anwendungsentwicklung
KI-Anwendungsentwicklung KI-Übersetzer-API
KI-Übersetzer-API KI-SEO/GEO-Dienst
KI-SEO/GEO-Dienst Geooptimierter PR-Service
Geooptimierter PR-Service Web-Scraping-Dienst
Web-Scraping-Dienst OpenClaw
OpenClaw Die besten KI-Tools
Die besten KI-Tools Top-KI-Roboter
Top-KI-Roboter
 Einloggen
Einloggen



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'alibaba/qwen3-vl-32b-instruct',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="alibaba/qwen3-vl-32b-instruct",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Produktdetails
✨ Entdecken Sie Qwen3 VL 32B Instruct: Ihre fortschrittliche KI für Bild- und Spracherkennung
Der Qwen3 VL 32B Anleitung ist ein hochmodernes, großformatiges Bildverarbeitungsmodell (Vision-Language-Large-Modell, VL), das speziell für die präzise Befolgung von Anweisungen in einem breiten Spektrum visueller Aufgaben entwickelt wurde. Es zeichnet sich durch seine Fähigkeit aus, komplexe visuelle Eingaben zu interpretieren und hochgradig kohärente, kontextsensitive Textausgaben zu generieren. Dieses Modell ist sorgfältig optimiert, um in der Bildbeschreibung, der Gestaltung ansprechender visueller Dialoge und der vielseitigen Inhaltsgenerierung hervorragende Ergebnisse zu erzielen und ist somit ein leistungsstarkes Werkzeug für multimodale KI-Anwendungen.
Wie in seiner detaillierten Beschreibung dargelegt Offizielle Qwen3 VL 32B ÜbersichtDer Qwen3 VL 32B Instruct ist eine „nur denkende“ Version, was bedeutet, dass er für die direkte und effiziente Ausführung visueller Aufgaben optimiert ist und nicht für allgemeines Denken, wodurch eine überlegene Leistung in seinem spezialisierten Bereich gewährleistet wird.
⚙️ Technische Daten auf einen Blick
- Modelltyp: Vision-Language Large Model (VL)
- Anzahl der Parameter: 32 Milliarden Parameter
- Architektur: Transformatorbasierte multimodale Architektur, die einen robusten visuellen Encoder mit einem hochentwickelten Textdecoder integriert.
- Eingabemodalitäten: Unterstützt die nahtlose Integration von Bildern und Textanweisungen/Hinweisen.
- Ausgabemodalitäten: Spezialisiert auf die Generierung hochwertiger Texte (Beschreibungen, Dialoge, kreative Inhalte).
- Trainingsdaten: Trainiert mit einem umfangreichen, multimodalen Datensatz, der sorgfältig annotierte Bilder in Verbindung mit ausführlichen beschreibenden und dialogischen Texten umfasst.
- Inferenzfähigkeiten: Bietet eine solide Grundlage für das Training mit wenigen oder gar keinen Schüssen, wodurch ein umfangreiches Nachtraining überflüssig wird.
🚀 Unübertroffene Leistung & Maßstäbe
- 🎯 Erreicht modernste Genauigkeit auf führenden Datensätzen für visuelle Beschreibungen, streng verglichen mit COCO Caption und VQA.
- 📈 Demonstriert überragende Fähigkeit, Anweisungen zu befolgen, bestätigt durch menschliche Bewertungen hinsichtlich außergewöhnlicher Relevanz und Kohärenz.
- 💡 Übertrifft die bisherigen Qwen VL-Versionen. in multimodaler Inhaltsgenerierung, Qualität und präziser Anweisungsausrichtung.
- 🔒 Ausstellungen robuste Zero-Shot-Performance bei komplexen visuellen Dialogaufgaben im Vergleich zu Basismodellen.
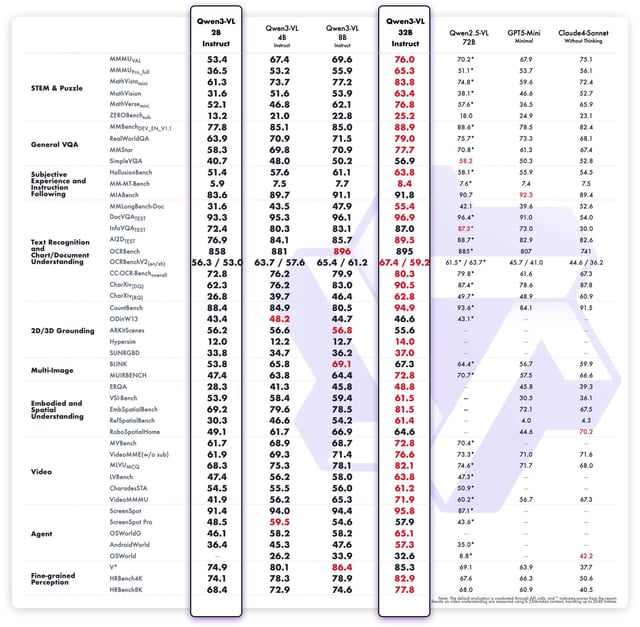
🌟 Hauptmerkmale und Vorteile
- ✨ Präzise Bildbeschreibungen: Optimiert für die Generierung besonders klarer und präziser Bildbeschreibungen auf Basis von Benutzeranweisungen.
- 💬 Anregende visuelle Dialoge: Fähigkeit, komplexe visuelle Kontexte zu verstehen und an dynamischen visuellen Dialogen teilzunehmen.
- 🎨 Kreative Inhaltserstellung: Erzeugt direkt aus textlichen Vorgaben hochrelevante und innovative visuelle Inhalte.
- ✔️ Hohe Ausrichtung auf die Anweisungen: Minimiert irrelevante oder halluzinatorische Inhalte durch eine enge Abstimmung mit den Benutzeranweisungen.
- 🖼️ Effiziente Verarbeitung hochauflösender Daten: Verarbeitet große, hochauflösende Bilder effizient mit fein abgestuftem visuellem Verständnis.
- 🌍 Mehrsprachige Ausgabe: Unterstützt mehrsprachige Textausgabe und demonstriert damit eine hohe Sprachkompetenz in verschiedenen Sprachen.
- 🔌 Einfache Integration: Konzipiert für die unkomplizierte Integration in KI-gesteuerte Content-Erstellungs-Pipelines und interaktive visuelle Assistenten.
💰 Qwen3 VL 32B API-Preise
- ➡️ Eingang: 0,735 $ / 1 Million Token
- ⬅️ Ausgabe: 2,94 $ / 1 Million Token
💡 Vielseitige Anwendungsfälle
- 📸 Automatische Bildbeschreibung: Ideal für Digital Asset Management Systeme, da es sofortige und präzise Beschreibungen liefert.
- 🗣️ Visuelle Qualitätssicherung & Kundensupport: Erweitert Kundenservice-Bots um interaktive visuelle Fragebeantwortungsfunktionen.
- ✍️ Marketing & Content-Erstellung: Unterstützt die Content-Erstellung für Marketingkampagnen, soziale Medien und kreatives Storytelling mithilfe von Bildern.
- 🚶♀️ Hilfe für Sehbehinderte: Beschreibt visuelle Szenen in vielen Details und bietet damit unschätzbare Unterstützung.
- 🔍 Erweiterte Multimedia-Suche: Verbessert die Suchmaschinenleistung durch ein fortschrittliches, bildbasiertes Kontextverständnis.
- 📚 Anwendungen im Bildungsbereich: Unterstützt interaktive visuelle Erklärungen und Tutorials und gestaltet das Lernen dadurch ansprechender.
💻 Codebeispiel für die Integration
Nachfolgend finden Sie einen typischen Codeausschnitt, der die Interaktion mit der Qwen3 VL 32B Instruct API veranschaulicht.
import openai client = openai.OpenAI( api_key="YOUR_API_KEY", # Ersetzen Sie dies durch Ihren tatsächlichen API-Schlüssel base_url="https://api.your-provider.com/v1" # Ersetzen Sie dies durch Ihren API-Endpunkt ) response = client.chat.completions.create( model="alibaba/qwen3-vl-32b-instruct", messages=[ {"role": "system", "content": "Sie sind ein hilfreicher Assistent, der Bilder beschreiben kann."}, {"role": "user", "content": [ {"type": "text", "text": "Was ist auf diesem Bild?"}, {"type": "image_url", "image_url": {"url": "https://example.com/image.jpg"}} ]} ], max_tokens=500 ) print(response.choices[0].message.content) 🆚 Qwen3 VL 32B Instruct im Vergleich zu anderen führenden Modellen
vs. Qwen3 VL 32B Base:
Der Anleitungsversion ist sorgfältig auf optimale Befolgung von Anweisungen abgestimmt und liefert kontextrelevantere und präzisere Beschreibungen. Im Gegensatz dazu zielt das Basismodell primär auf ein allgemeines multimodales Verständnis ab.
vs. OpenAI GPT-4 (mit Sehvermögen):
Qwen3 VL 32B Instruct wurde speziell für die Ausführung von Anweisungen und die Generierung visueller Inhalte entwickelt und optimiert und zeigt weniger Halluzinationen bei visuellen Eingaben. GPT-4 bietet zwar breitere allgemeine KI-Fähigkeiten, ist aber weniger spezialisiert auf die direkte Befolgung visueller Anweisungen.
vs. Claude 4.5 Visuell:
Qwen3 VL 32B Instruct bietet eine verbesserte Bildbeschreibung und Dialogqualität mit einem besonderen Fokus auf visuelle Anweisungen. Claude hingegen ist zwar hervorragend für textbasiertes Denken und die Verarbeitung komplexerer Kontexte geeignet, bietet aber in der Regel etwas weniger visuelle Spezialisierung.
vs. DeepSeek V3.1:
Qwen3 VL 32B Instruct zeichnet sich durch detaillierte Inhaltsgenerierung und anspruchsvolle Visualisierungsaufgaben aus. DeepSeek hingegen ist stärker auf semantische Bildsuch- und Abruffunktionen ausgerichtet.
❓ Häufig gestellte Fragen (FAQ)
F: Wofür ist Qwen3 VL 32B Instruct primär konzipiert?
A: Es handelt sich um ein spezialisiertes Bild-Sprach-Modell, das für die Befolgung von Anweisungen bei Aufgaben wie der präzisen Bildbeschreibung, dem ansprechenden visuellen Dialog und der intelligenten Inhaltsgenerierung auf der Grundlage visueller Eingaben und textueller Vorgaben optimiert ist.
F: Wie unterscheidet sich Qwen3 VL 32B Instruct von der Basisversion?
A: Die Instruct-Version ist speziell auf eine verbesserte Befolgung der Anweisungen abgestimmt, was zu genaueren und kontextbezogeneren Beschreibungen führt, im Gegensatz zum Base-Modell, das ein allgemeines multimodales Verständnis bietet.
F: Was sind die wichtigsten Vorteile der Verwendung von Qwen3 VL 32B Instruct?
A: Zu den wichtigsten Vorteilen gehören eine präzise Bildbeschreibung, robuste visuelle Dialogfunktionen, kreative Inhaltsgenerierung mit hoher Ausrichtung auf Anweisungen, effiziente Verarbeitung hochauflösender Bilder und mehrsprachige Textausgabe.
F: Kann Qwen3 VL 32B Instruct in realen Anwendungen eingesetzt werden?
A: Absolut. Es eignet sich ideal für die automatisierte Bildbeschreibung, visuelle Frage-Antwort-Systeme im Kundenservice, KI-gestützte Inhaltserstellung, die Unterstützung sehbehinderter Nutzer, die Verbesserung der Multimedia-Suche und interaktive Lernwerkzeuge.
F: Wie sieht die Preisstruktur für die Qwen3 VL 32B API aus?
A: Die Preisgestaltung ist gestaffelt: Input kostet 0,735 US-Dollar pro 1 Million Token, Output kostet 2,94 US-Dollar pro 1 Million Token.
KI-Spielplatz

