 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banane
Google - Gemini, Nano Banane Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance – Das Beste von ByteDance
ByteDance – Das Beste von ByteDance Alle Modelle
Alle Modelle Unternehmenspläne
Unternehmenspläne KI-Anwendungsentwicklung
KI-Anwendungsentwicklung KI-Übersetzer-API
KI-Übersetzer-API KI-SEO/GEO-Dienst
KI-SEO/GEO-Dienst Geooptimierter PR-Service
Geooptimierter PR-Service Web-Scraping-Dienst
Web-Scraping-Dienst OpenClaw
OpenClaw Die besten KI-Tools
Die besten KI-Tools Top-KI-Roboter
Top-KI-Roboter
 Einloggen
Einloggen



const main = async () => {
const response = await fetch('https://api.ai.cc/v2/generate/video/alibaba/generation', {
method: 'POST',
headers: {
Authorization: 'Bearer ',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'alibaba/wan2.1-t2v-turbo',
prompt: 'A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background',
aspect_ratio: '16:9',
}),
}).then((res) => res.json());
console.log('Generation:', response);
};
main()
import requests
def main():
url = "https://api.ai.cc/v2/generate/video/alibaba/generation"
payload = {
"model": "alibaba/wan2.1-t2v-turbo",
"prompt": "A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background",
"aspect_ratio": "16:9",
}
headers = {"Authorization": "Bearer ", "Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print("Generation:", response.json())
if __name__ == "__main__":
main()

.webp)
Produktdetails
Alibabas Wan2.1 Turbo ist ein hochmodernes KI-Modell zur Text-zu-Video-Konvertierung, das speziell für effiziente Stromerzeugung Es vereint überragende Leistung und Geschwindigkeit. Es verarbeitet umfangreiche Kontextinformationen und zeichnet sich durch seine hervorragende Leistung aus. qualitativ hochwertige Videos, mit fließenden zeitlichen Dynamiken und präziser semantischer Übereinstimmung zwischen textuellen Beschreibungen und visuellen Ausgaben.
✨ Technische Spezifikationen
Leistungsbenchmarks
- ✅ VQA-Benchmark: Erreicht eine verbesserte Turboeffizienz, konkrete Zahlen auf Anfrage erhältlich.
- ✅ Multimodales Denken: Zeigt ausgeprägte Argumentationsfähigkeiten sowohl im Video- als auch im Textbereich.
- ✅ Crossmodale Suche: Gewährleistet eine hohe Abrufgenauigkeit, optimiert für umfangreiche Bild-Sprach-Aufgaben.
Leistungskennzahlen
WAN2.1 Turbo liefert hervorragende Videogenerierungsqualität gleichzeitig werden die Inferenzzeit und der Rechenaufwand im Vergleich zu größeren Modellen deutlich reduziert. Dadurch eignet es sich hervorragend für Echtzeit- oder kostensensitive AnwendungenDas Modell bewahrt Alibabas charakteristische Stärken in Bezug auf dynamische Bewegungen, räumliche Beziehungen und Kompositionsgenauigkeit.
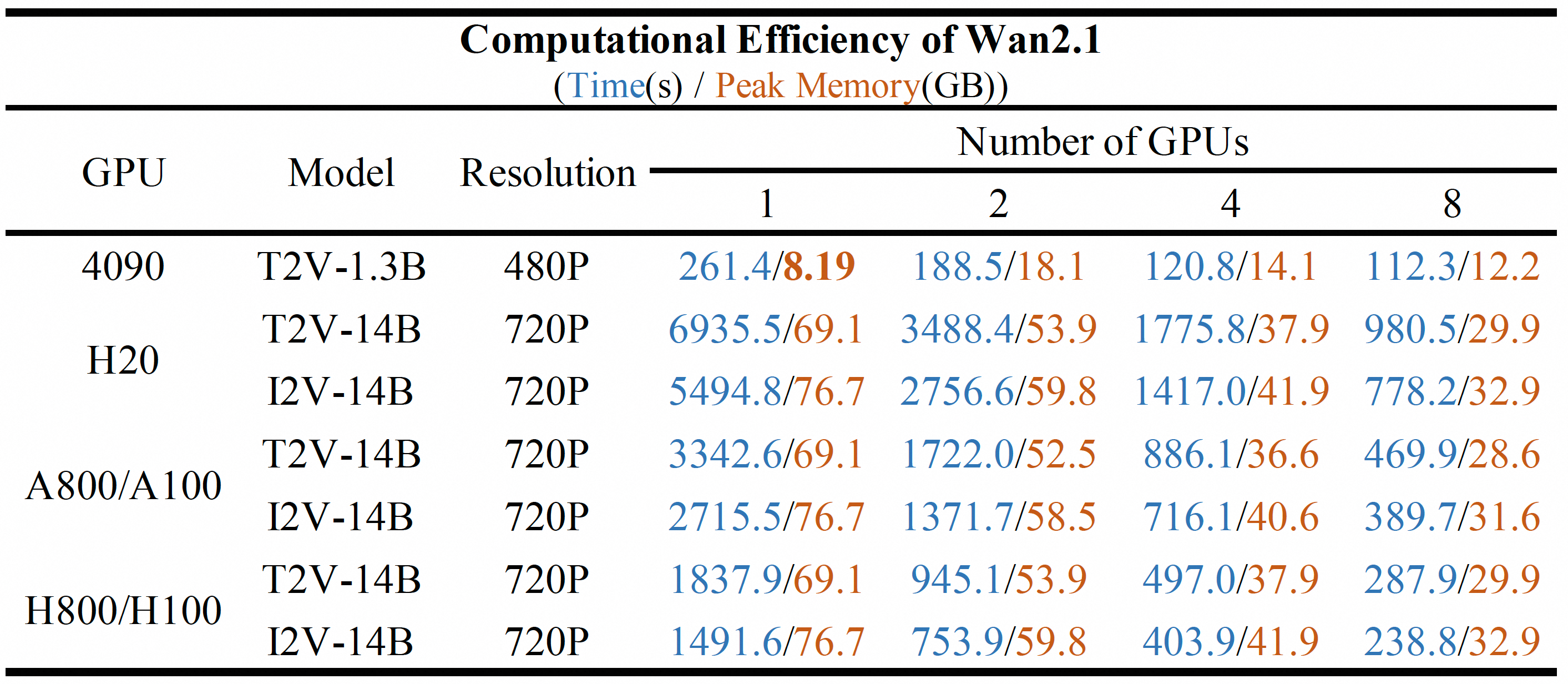
Hauptkompetenzen
- 💡 Vision-Sprach-Fusion: Integriert und generiert nahtlos Videoinhalte, die durch detaillierte Textbeschreibungen bedingt sind.
- 🚀 Echtzeitgenerierung: Bietet eine extrem hohe Inferenzgeschwindigkeit und ermöglicht so schnellere Videoausgabe ohne wesentliche Qualitätseinbußen.
- 🧠 Kontextuelles Verständnis: Gewährleistet eine robuste, mehrstufige Argumentation und eine konsistente Erzählweise in allen generierten Videos.
API-Preise
💰 Nur 0,189 $ pro Video
🎯 Optimale Anwendungsfälle
- 🎥 Text-zu-Video-Generation: Ideal für die schnelle und qualitativ hochwertige Videosynthese direkt aus Texteingaben.
- ⚡ Echtzeit-Inhaltserstellung: Perfekt geeignet für Anwendungen, die schnelle Videobearbeitung und dynamische Inhaltsbereitstellung erfordern.
- 🔗 Multimodale Arbeitsabläufe: Unterstützt Projekte, die Bild- und Sprachdaten für Business Intelligence, Unterhaltung und kreative Medienproduktion integrieren.
💻 Codebeispiel
📊 Vergleich mit anderen Modellen
Vs. Wan2.2-T2V: Wan2.1 Turbo bietet deutlich schnellere Inferenz und überlegene Kosteneffizienz, allerdings mit einer etwas geringeren maximalen Generationsauflösung und Modellgröße.
Vs. Gemini 2.5 Blitz: Bietet wettbewerbsfähige multimodale Genauigkeit und ist zudem optimal auf Geschwindigkeit ausgelegt.
Im Vergleich zu OpenAI GPT-4 Vision: Bietet ein kleineres Kontextfenster, erweist sich aber bei speziellen Videogenerierungsaufgaben als kostengünstiger.
Vs. Qwen3-235B-A22B: Der Fokus liegt auf der Turbo-Effizienz, während Wan2.1 Turbo in bestimmten Kontexten eine etwas bessere Abrufgenauigkeit bietet.
⚠️ Einschränkungen
Einige generierte Ausgaben können gelegentlich kleinere Artefakte enthalten oder im Vergleich zu den größten Wan2.2-Modellen weniger detaillierte Texturen aufweisen. Diese Probleme lassen sich jedoch oft wirksam minimieren durch prompte Entwicklung oder Nachbearbeitungstechniken.
❓ Häufig gestellte Fragen
F: Welche Rechenarchitektur ermöglicht die außergewöhnliche Inferenzgeschwindigkeit von Wan2.1 Turbo?
A: Wan2.1 Turbo nutzt eine revolutionäre Hybridarchitektur, die spärliche Expertennetzwerke mit dynamischen Berechnungspfaden kombiniert. Dadurch kann das Modell nur relevante Parameter-Teilmengen aktivieren und den Rechenaufwand im Vergleich zu dichten Modellen um 67 % reduzieren. Es integriert außerdem fortschrittliche Quantisierungs- und speichereffiziente Aufmerksamkeitsmechanismen sowie einen neuartigen Token-Skipping-Mechanismus zur Echtzeitverarbeitung semantisch kritischer Token.
F: Wie gelingt es Wan2.1 Turbo, die Qualität trotz aggressiver Optimierung aufrechtzuerhalten?
A: Das Modell gewährleistet durch ausgefeilte Wissensdestillation aus größeren WAN-Architekturen eine außergewöhnliche Qualität und bewahrt dabei wichtige Denkmuster. Es integriert mehrstufige Verfeinerungsprozesse, die die Verarbeitungstiefe dynamisch an die Aufgabenkomplexität anpassen und so schnelle Antworten auf einfache Anfragen sowie tiefergehende Analysen für komplexe Anfragen ermöglichen. Die kontinuierliche Überwachung des latenten Raums erkennt und korrigiert zudem potenzielle Qualitätsbeeinträchtigungen in Echtzeit.
F: Welche Echtzeitanwendungen profitieren am meisten von den Latenzoptimierungen von Wan2.1 Turbo?
A: Wan2.1 Turbo zeichnet sich durch seine Leistungsfähigkeit in latenzempfindlichen Bereichen aus, wie z. B. der Analyse des Hochfrequenzhandels (Anforderungen unter 10 ms), interaktiven Bildungsplattformen, die Tausende von gleichzeitigen Benutzern unterstützen, Echtzeit-Mehrsprachigkeitsübersetzung in Live-Gesprächen, Entscheidungssystemen für autonome Fahrzeuge, die eine sofortige Umgebungsinterpretation erfordern, und groß angelegten Kundendienstoperationen, bei denen die Konsistenz und Geschwindigkeit der Reaktion sich direkt auf die Kundenzufriedenheit und die betriebliche Effizienz auswirken.
F: Wie schneidet das Modell im Vergleich zu herkömmlichen Architekturen hinsichtlich seiner Energieeffizienz ab?
A: Wan2.1 Turbo erzielt eine beispiellose Energieeffizienz durch kontextsensitive Leistungssteuerung, adaptive Präzisionsarithmetik und eine ausgefeilte Optimierung der Cache-Hierarchie. Benchmark-Ergebnisse zeigen eine Reduzierung des Energieverbrauchs pro Inferenz um 58 % bei gleichzeitiger Beibehaltung von 94 % der Qualitätsmetriken unveränderter Modelle. Dadurch eignet es sich hervorragend für Edge-Einsätze und umweltbewusste Computing-Initiativen.
F: Welche Flexibilität beim Einsatz bietet Wan2.1 Turbo auf verschiedenen Hardwareplattformen?
A: Das Modell bietet dank seiner modularen Architektur eine außergewöhnliche Hardwareanpassungsfähigkeit und unterstützt die dynamische Rekonfiguration verschiedener Verarbeitungseinheiten. Es zeichnet sich durch spezielle Optimierungen für GPU-Cluster mit effizientem Tensorparallelismus, CPU-Bereitstellung mit erweiterter Befehlssatznutzung und Kompatibilität mit neuer neuromorpher Hardware aus. Das Bereitstellungsframework umfasst die automatische Hardwareerkennung und -konfiguration und ermöglicht so nahtlose Übergänge zwischen Cloud-Infrastruktur, Edge-Geräten und mobilen Plattformen bei gleichbleibender Leistungsfähigkeit.
KI-Spielplatz

