 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banane
Google - Gemini, Nano Banane Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance – Das Beste von ByteDance
ByteDance – Das Beste von ByteDance Alle Modelle
Alle Modelle Unternehmenspläne
Unternehmenspläne KI-Anwendungsentwicklung
KI-Anwendungsentwicklung KI-Übersetzer-API
KI-Übersetzer-API KI-SEO/GEO-Dienst
KI-SEO/GEO-Dienst Geooptimierter PR-Service
Geooptimierter PR-Service Web-Scraping-Dienst
Web-Scraping-Dienst OpenClaw
OpenClaw Die besten KI-Tools
Die besten KI-Tools Top-KI-Roboter
Top-KI-Roboter
 Einloggen
Einloggen



const main = async () => {
const response = await fetch('https://api.ai.cc/v2/generate/video/alibaba/generation', {
method: 'POST',
headers: {
Authorization: 'Bearer ',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'alibaba/wan2.2-t2v-plus',
prompt: 'A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background',
aspect_ratio: '16:9',
}),
}).then((res) => res.json());
console.log('Generation:', response);
};
main()
import requests
def main():
url = "https://api.ai.cc/v2/generate/video/alibaba/generation"
payload = {
"model": "alibaba/wan2.2-t2v-plus",
"prompt": "A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background",
"aspect_ratio": "16:9",
}
headers = {"Authorization": "Bearer ", "Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print("Generation:", response.json())
if __name__ == "__main__":
main()

.webp)
Produktdetails
Alibabas WAN2.2 ist ein hochmodernes KI-Modell sorgfältig konstruiert für höchste Ansprüche multimodales VerständnisEs integriert nahtlos sowohl Text- als auch Bildeingaben und bietet robuste Funktionen für die Verarbeitung großer Kontexte sowie eine überragende Präzision bei komplexen Text-zu-Bild-Aufgaben und anspruchsvollen Schlussfolgerungsaufgaben.
✨ Technische Spezifikationen
Leistungsbenchmarks
- ✅ VQA-Benchmark: 78,3 %
- ✅ Multimodales Denken: 52,7 %
- ✅ Crossmodale Suche: 81,9 %
Leistungskennzahlen (WAN 2.1)
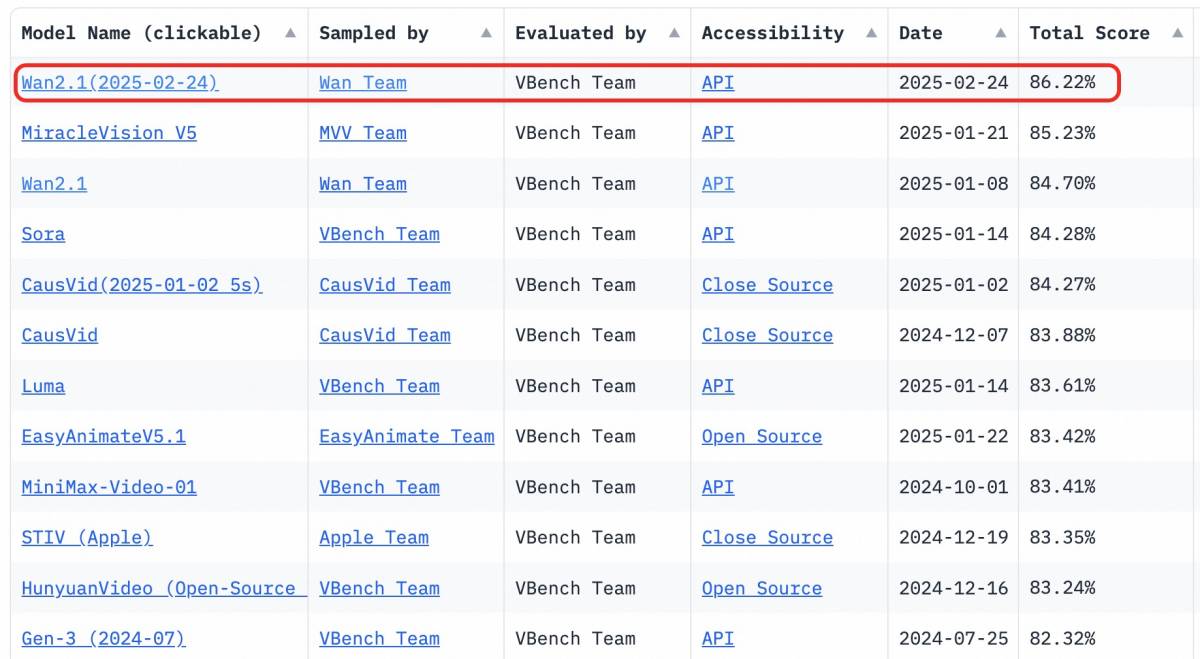
Wan2.1 führt mit einer beeindruckenden Gesamtleistung VBench-Wert von 86,22 %Sie demonstrieren herausragende Leistung in Bezug auf dynamische Bewegungen, räumliche Beziehungen, Farbgenauigkeit und die Interaktion mehrerer Objekte. Das Training grundlegender Videomodelle erfordert erhebliche Rechenleistung und den Zugriff auf umfangreiche, qualitativ hochwertige Datensätze. Der offene Zugang zu solchen fortschrittlichen Modellen senkt die Hürden drastisch und ermöglicht es mehr Unternehmen, maßgeschneiderte, hochwertige visuelle Inhalte kosteneffizient zu erstellen.
Hauptkompetenzen
- 💡 Vision-Sprach-Fusion: Ausgezeichnet in der Interpretation und Generierung präziser Antworten durch die nahtlose Kombination von Bild- und Textdaten.
- 💡 Fortgeschrittenes logisches Denken: Zeigt ausgeprägte Fähigkeiten zum mehrstufigen logischen Denken über verschiedene Modalitäten hinweg, um tiefgreifende Analysen und ein umfassendes Verständnis komplexer Sachverhalte zu ermöglichen.
💲 API-Preise
- 🎥 480p: 0,105 $/Video
- 🎥 1080p: 0,525 $/Video
🚀 Optimale Anwendungsfälle
- ✅ Multimodale Analyse: Verbesserung des Verständnisses durch die gekonnte Kombination von Bild- und Textdaten.
- ✅ Visuelles Frage-Antwort-System (VQA): Bereitstellung präziser und kontextbezogener Antworten auf Basis integrierter Bild-Text-Eingaben.
- ✅ Crossmodale Suche: Ermöglichung eines effizienten Abgleichs und Abrufs von Informationen sowohl im visuellen als auch im sprachlichen Bereich.
- ✅ Business Intelligence: Die Interpretation komplexer Daten wird erleichtert, indem visuelle Inhalte mit Textanalysen integriert werden, um tiefergehende Erkenntnisse zu gewinnen.
💻 Codebeispiel
📊 Vergleich mit anderen führenden Modellen
- Vs. Gemini 2.5 Blitz: Alibaba Wan2.2 bietet eine höhere multimodale Genauigkeit (78,3 % im Vergleich zu 70,8 % VQA-Benchmark) und ist daher eine überlegene Wahl für integrierte Bild-Sprach-Aufgaben.
- Im Vergleich zu OpenAI GPT-4 Vision: Wan2.2 bietet ein deutlich größeres Kontextfenster (65.000 vs. 32.000 Token Text), wodurch ausführlichere und kohärentere Gespräche mit eingebetteten Bildern ermöglicht werden.
- Vs. Qwen3-235B-A22B: Alibaba Wan2.2 weist eine überlegene multimodale Abrufgenauigkeit auf (81,9 % gegenüber geschätzten ~78 %), und zwar optimiert für anspruchsvolle, groß angelegte Bildverarbeitungs- und Sprachverarbeitungs-Workflows.
⚠️ Einschränkungen
Gelegentlich können generierte Videos unerwünschte Elemente wie Textartefakte oder Wasserzeichen enthalten. Die Verwendung negativer Eingabeaufforderungen kann zwar dazu beitragen, diese Vorkommnisse zu verringern, sie aber nicht vollständig zu beseitigen.
🔗 API-Integration
Alibaba WAN 2.2 ist über die KI/ML-APIEine umfassende Dokumentation steht zur Verfügung, um einen reibungslosen und effizienten Integrationsprozess zu gewährleisten.
❓ Häufig gestellte Fragen (FAQ)
A: Alibaba Wan2.2 ist ein fortschrittliches KI-Modell, das für multimodales Verständnis entwickelt wurde und insbesondere Text- und Bildeingaben für komplexe Schlussfolgerungen und hochpräzise Text-zu-Bild-Aufgaben integriert.
A: Wan2.2 weist eine höhere multimodale Genauigkeit (78,3 % VQA-Benchmark) im Vergleich zu Gemini 2.5 Flash (70,8 %) auf und eignet sich daher besonders gut für integrierte Bild-Sprach-Aufgaben.
A: Zu ihren Hauptfähigkeiten gehören eine robuste Bild-Sprach-Fusion zur Interpretation und Generierung von Inhalten aus kombinierten Bild- und Textdaten sowie ein fortschrittliches mehrstufiges Schließen über verschiedene Modalitäten hinweg.
A: Gelegentlich können generierte Videos unerwünschte Elemente wie Textartefakte oder Wasserzeichen enthalten. Negative Eingabeaufforderungen können diese zwar abschwächen, aber nicht vollständig beseitigen.
A: Alibaba Wan2.2 ist über die AI/ML-API leicht zugänglich. Eine umfassende Dokumentation wird bereitgestellt, um den Integrationsprozess zu unterstützen.
KI-Spielplatz

