 OpenAI - ChatGPT、Sora
OpenAI - ChatGPT、Sora Google - Gemini,Nano Banana
Google - Gemini,Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok DeepSeek
DeepSeek 阿里巴巴 - Qwen
阿里巴巴 - Qwen 字节跳动 - 豆包
字节跳动 - 豆包 所有型号
所有型号 企业API定制计划
企业API定制计划 AI应用开发服务
AI应用开发服务 AI智能翻译API
AI智能翻译API AI SEO/GEO 服务
AI SEO/GEO 服务 GEO/AI大模型优化
GEO/AI大模型优化 网络爬虫服务
网络爬虫服务 OpenClaw
OpenClaw 顶级人工智能工具
顶级人工智能工具 顶级人工智能机器人
顶级人工智能机器人
 登录
登录















Deepseek R1 与 GPT o1 对比预览
2025-12-13

随着人工智能领域的发展,人工智能格局正在迅速演变。 DeepSeek R1一个强调精确性和成本效益的模型,以及 GPT o1-预览OpenAI 的多功能强大模型。这份全面的对比报告探讨了它们的规格、基准测试和实际性能,以帮助您确定哪款模型最符合您的开发需求。
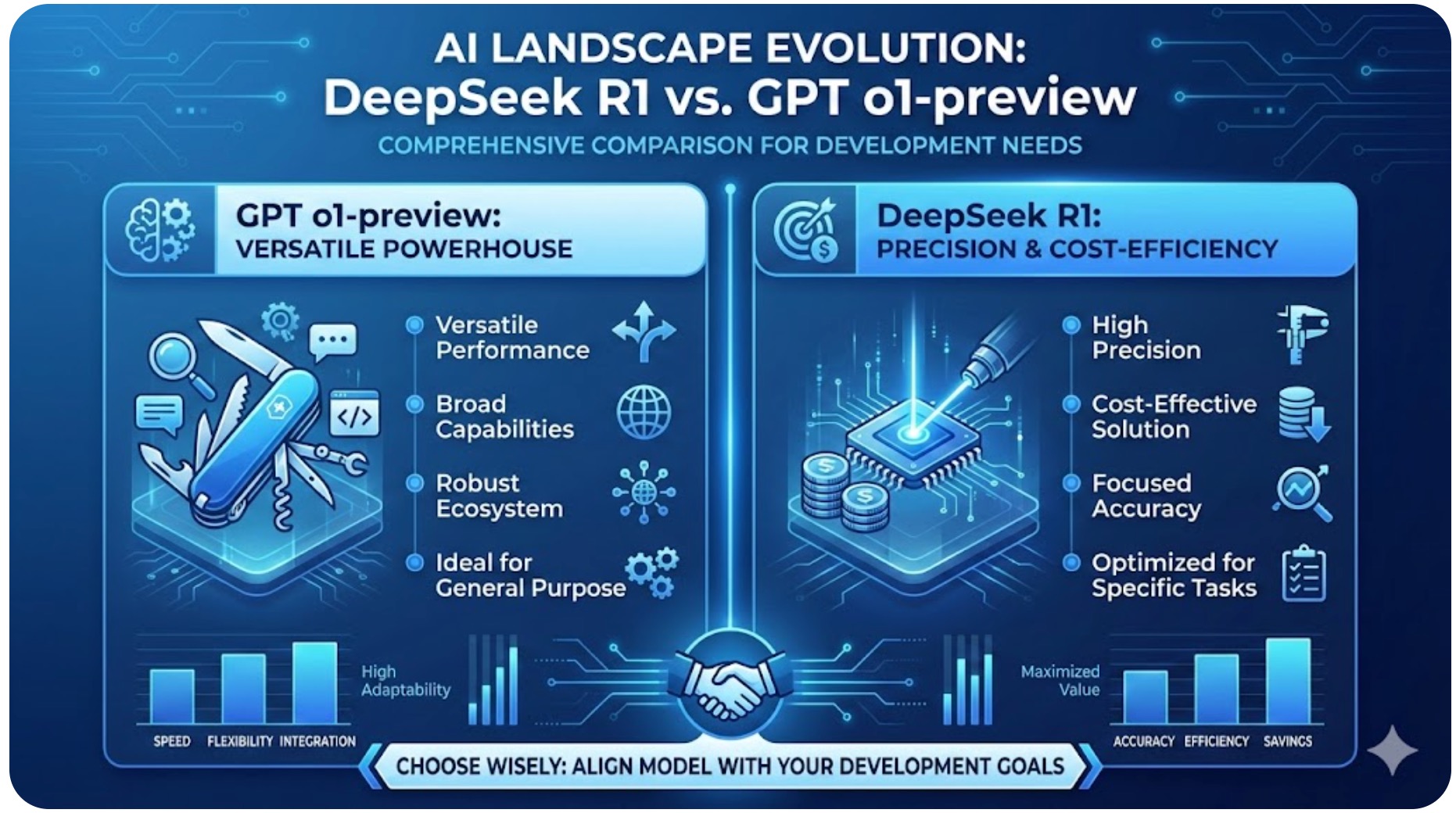
1. 技术规格对比
虽然两种模型都支持大规模 128K 输入上下文窗口它们在产量和处理速度方面存在显著差异。
| 规格 | GPT o1-预览 | DeepSeek R1 |
|---|---|---|
| 输入上下文 | 128K | 128K |
| 最大输出令牌 | 65K | 8K |
| 参数 | 未公开 | 671B |
| 速度(Tokens/秒) | 144 | 37.2 |
| 知识门槛 | 2023年10月 | 未指定(较新) |
要点总结: GPT o1-preview 在需要生成大量文本(65K 个词元)和追求速度的任务中表现更佳。然而,对于输出长度要求不高、精度要求高的任务,DeepSeek R1 则是一个强有力的竞争者。
2. 性能基准
结合官方发布说明和公开基准测试结果,以下是它们在各个专业领域的对比情况:
| 类别 | 基准 | GPT o1-预览 | DeepSeek R1 |
|---|---|---|---|
| 数学 | MATH-500 | 92 | 97.3 |
| 推理 | GPQA | 67 | 71.5 |
| 编码 | 人类评估 | 96 | 96.3 |
| 网络安全 | CTF | 43.0 | - |
3. 真实世界实践测试
基准测试固然有用,但只有真实世界的测试才能真正揭示人工智能的“个性”和可靠性。我们从五个关键领域对这两个模型进行了测试。
4. 定价:成本效益差距
最令人震惊的差异之一在于成本结构。DeepSeek 为大批量任务提供了一种价格更实惠的解决方案。
| 价格(每1000个Tokens) | GPT o1-预览 | DeepSeek R1 |
|---|---|---|
| 投入价格 | 0.01575美元 | 0.00061美元 |
| 产出价格 | 0.06300美元 | 0.00241美元 |
最终结果
🏆 何时选择 GPT o1-preview
- 创意写作: 能够创作丰富、详尽的内容和故事。
- 网站开发: 更可靠地生成无错误的HTML/CSS布局。
- 网络安全: 在CTF挑战赛中表现更佳。
🏆 何时选择 DeepSeek R1
- 数学与逻辑: 在复杂的推理和计算任务中优于 GPT。
- 成本效益: 价格大幅降低,使其成为扩展应用的理想选择。
- 内存效率: 生成高度优化的后端逻辑代码。
常见问题解答 (FAQ)
问:DeepSeek R1 和 GPT o1 哪个 AI 模型更适合编程?
两者都很优秀。GPT o1-preview 通常能为初学者生成更简洁的代码,并带来更出色的 Web 前端设计。DeepSeek R1 则在后端逻辑和内存优化方面表现卓越。
问:DeepSeek R1 可以免费使用吗?
DeepSeek R1 并非免费,但比 OpenAI 的模型便宜得多。它的输入成本比 GPT o1-preview 低约 96%。
问:为什么 DeepSeek R1 在数学方面表现更好?
基准测试显示,DeepSeek R1 在 MATH-500 上的得分为 97.3,而 GPT 的得分为 92。它的架构似乎更适合逐步逻辑验证,从而减少计算中的幻觉。