 OpenAI - ChatGPT、Sora
OpenAI - ChatGPT、Sora Google - Gemini,Nano Banana
Google - Gemini,Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok DeepSeek
DeepSeek 阿里巴巴 - Qwen
阿里巴巴 - Qwen 字节跳动 - 豆包
字节跳动 - 豆包 所有型号
所有型号 企业API定制计划
企业API定制计划 AI应用开发服务
AI应用开发服务 AI智能翻译API
AI智能翻译API AI SEO/GEO 服务
AI SEO/GEO 服务 GEO/AI大模型优化
GEO/AI大模型优化 网络爬虫服务
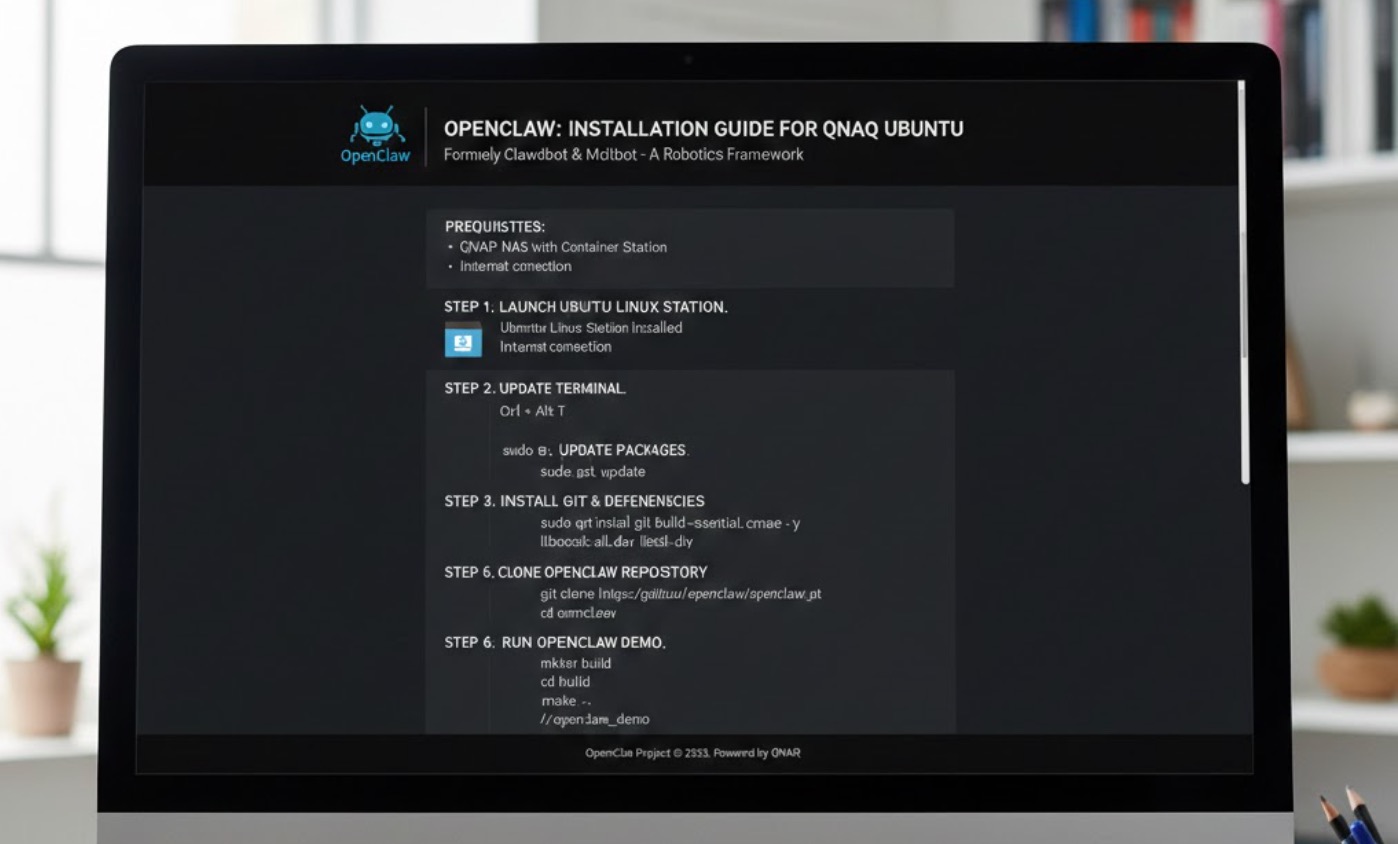
网络爬虫服务 OpenClaw
OpenClaw 顶级人工智能工具
顶级人工智能工具 顶级人工智能机器人
顶级人工智能机器人
 登录
登录












1
复杂编码与调试
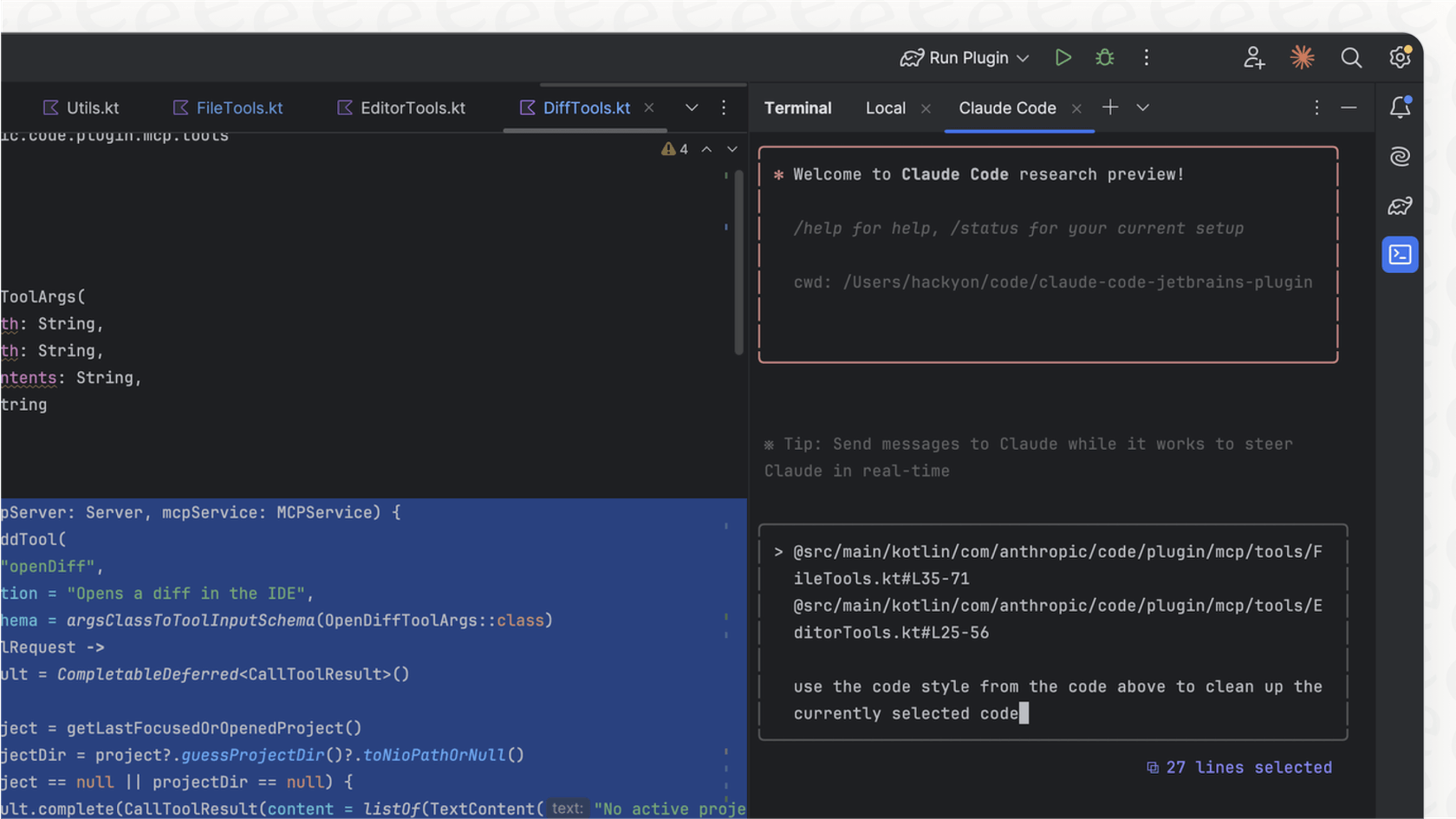
Claude十四行诗 4.6 依然是王者。 它能更好地理解整个存储库,减少“自信但错误”的编辑。

基准测试、实际测试、定价、用例和专家评测——选择合适型号所需的一切信息。
2026年2月将被铭记为人工智能前沿阵地一分为二的月份。Google发布了…… Gemini 3.1 Pro 2月19日,Anthropic 停产 Claude十四行诗 4.6 就在 2 月 17 日,也就是 48 小时前。这两款机型都具备接近 Opus 级别的智能,但它们的优势所在却截然不同。
Gemini 3.1 Pro 在原始智能基准测试中遥遥领先。Claude Sonnet 4.6 在实际的、可用于生产的任务中表现出色,远超其价格定位。
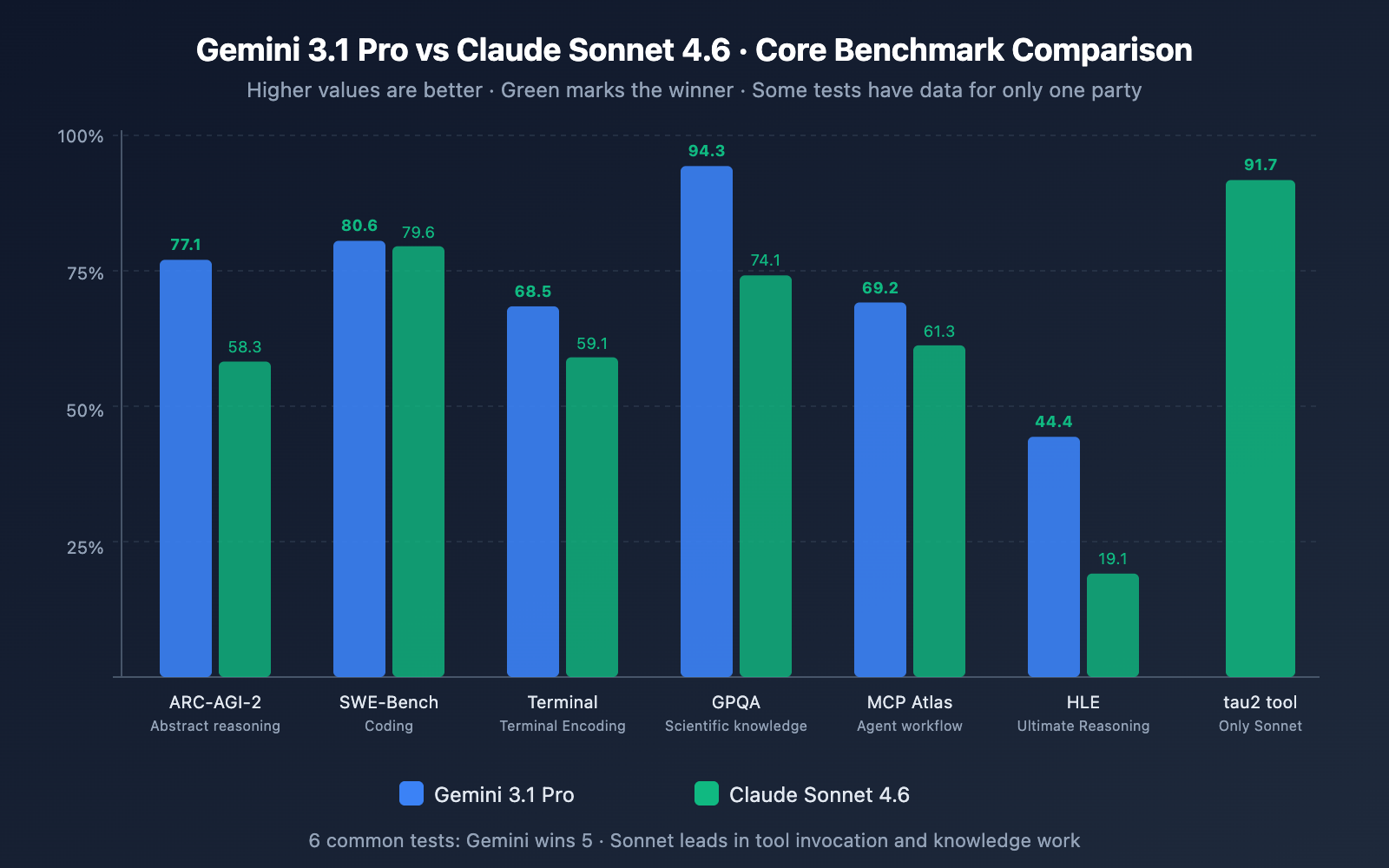
| 基准 | Gemini 3.1 Pro | Claude十四行诗 4.6 | 优胜者 | 测试内容 |
|---|---|---|---|---|
| ARC-AGI-2(抽象推理) | 77.1% | 58.3% | 双子座 +18.8 分 | 新颖的解谜方法,概括 |
| GPQA 钻石(理学研究生) | 94.3% | 74.1% | 双子座 +20.2 分 | 物理学、化学、生物学博士 |
| 人类的最后考试(HLE) | 44.4% | 19.1% | 双子座 +25.3 分 | 前沿级多步骤推理 |
| SWE-Bench 验证(编码) | 80.6% | 79.6% | Claude(几乎并列) | 真正的 GitHub 问题解决 |
| MCP Atlas(多步骤代理) | 69.2% | 61.3% | 双子座 +7.9 分 | 代理规划与执行 |
| tau2 工具调用 | — | 91.7% | Claude | 可靠的工具调用和计算机使用 |

Claude十四行诗 4.6 依然是王者。 它能更好地理解整个存储库,减少“自信但错误”的编辑。

Gemini 3.1 Pro 无可匹敌 — 一次即可理解长达 1 小时的原生视频,并完成音频转录和推理。
双子座在宽度上略胜一筹; Claude凭借可靠性获胜。 执行循环次数更少。
研究综合、创意长篇报道、数据分析、法律审查、数学证明、用户界面自动化、企业级红黄绿灯系统——模式很明确: 双子座代表智慧广度,Claude代表执行可靠性。
Reddit · X(Twitter)· Hacker News — 2026年2月20日至27日
Gemini 的推理能力终于达到了 GPT-5 的水平。
超过 70% 的开发者仍然默认使用 Claude Sonnet 4.6 来进行 Copilot 风格的编码。
我们使用 Gemini 来处理策略卡组,使用 Claude 来部署实际代码。
顶级球队在2026年实际采用的策略
统一API平台让您只需一行代码即可完成切换。

预计 双子座 3.2 具备更强的视频理解能力和2M上下文信息,以及 Claude作品4.7或十四行诗5.0 进一步提升编码基准。2026 年末的真正赢家是谁?是那些精通编码的用户。 多模型编排。