 OpenAI - ChatGPT、Sora
OpenAI - ChatGPT、Sora Google - Gemini,Nano Banana
Google - Gemini,Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok DeepSeek
DeepSeek 阿里巴巴 - Qwen
阿里巴巴 - Qwen 字节跳动 - 豆包
字节跳动 - 豆包 所有型号
所有型号 企业API定制计划
企业API定制计划 AI应用开发服务
AI应用开发服务 AI智能翻译API
AI智能翻译API AI SEO/GEO 服务
AI SEO/GEO 服务 GEO/AI大模型优化
GEO/AI大模型优化 网络爬虫服务
网络爬虫服务 OpenClaw
OpenClaw 顶级人工智能工具
顶级人工智能工具 顶级人工智能机器人
顶级人工智能机器人
 登录
登录



const Anthropic = require('@anthropic-ai/sdk');
const api = new Anthropic({
baseURL: 'https://api.ai.cc/',
authToken: '',
});
const main = async () => {
const message = await api.messages.create({
model: 'anthropic/claude-sonnet-4.5',
max_tokens: 2048,
system: 'You are an AI assistant who knows everything.',
messages: [
{
role: 'user',
content: 'Tell me, why is the sky blue?',
},
],
});
console.log('Message:', message);
};
main();
import asyncio
from anthropic import Anthropic
client = Anthropic(
base_url="https://api.ai.cc/",
auth_token="",
)
def main():
message = client.messages.create(
model="anthropic/claude-sonnet-4.5",
max_tokens=2048,
system="You are an AI assistant who knows everything.",
messages=[
{
"role": "user",
"content": "Hello, Claude",
}
],
)
print("Message:", message.content)
if __name__ == "__main__":
main()


产品详情
🚀 使用 Claude 4.5 Sonnet API 提升您的项目
人种学派 Claude 4.5 十四行诗 它被誉为目前最先进的人工智能模型之一,专为追求卓越性能而设计。 软件编码执行 复杂代理任务并实现广泛的 自主计算机使用该模型非常擅长处理长时间的多步骤流程,展现出卓越的推理能力、深厚的领域知识以及与计算机系统的无缝交互。
Sonnet 4.5 专为关键任务环境而设计,可在严苛的实际应用中提供无与伦比的精度、可靠性和安全性,例如: 金融、网络安全、研究和高级开发工作流程。
⚙️ 技术规格
- 💻 主要优势: 专长领域包括软件工程、复杂代理和计算机自动化。
- 📜 SWE-bench 已验证: 取得了令人瞩目的成就 准确率 77.2% 开启扩展思维模式后,展现出顶尖的编程能力。
- 💬 OSWorld 基准测试: 得分 61.4% 针对实际计算机任务完成情况,突出其实用性。
- 🧠 扩展思维模式: 通过允许更深层次的认知处理,显著提高了复杂推理、多步骤编码和智能工作流程的性能,尽管在延迟和缓存效率方面略有不足。
- 📚 上下文管理: 它具有卓越的长期状态跟踪功能,通过先进的上下文窗口和对外部文件状态的感知,确保在长达数小时的会话中有效记忆并保持专注。
📊 性能基准测试
Sonnet 4.5 先进的长期上下文管理功能使其能够在长达数小时的会话中保持关键的感知和专注。这项功能对于要求苛刻的编码项目、复杂的智能体协调以及长时间的计算机交互至关重要。其增强的工具使用能力使该模型能够同时控制多个进程,从而提高自主工作流程的效率,例如复杂的软件调试、数据合成以及深入的金融或网络安全分析。其关键优势在于混合架构,既支持快速推理,也支持用于深度问题解决的专用扩展思维模式。
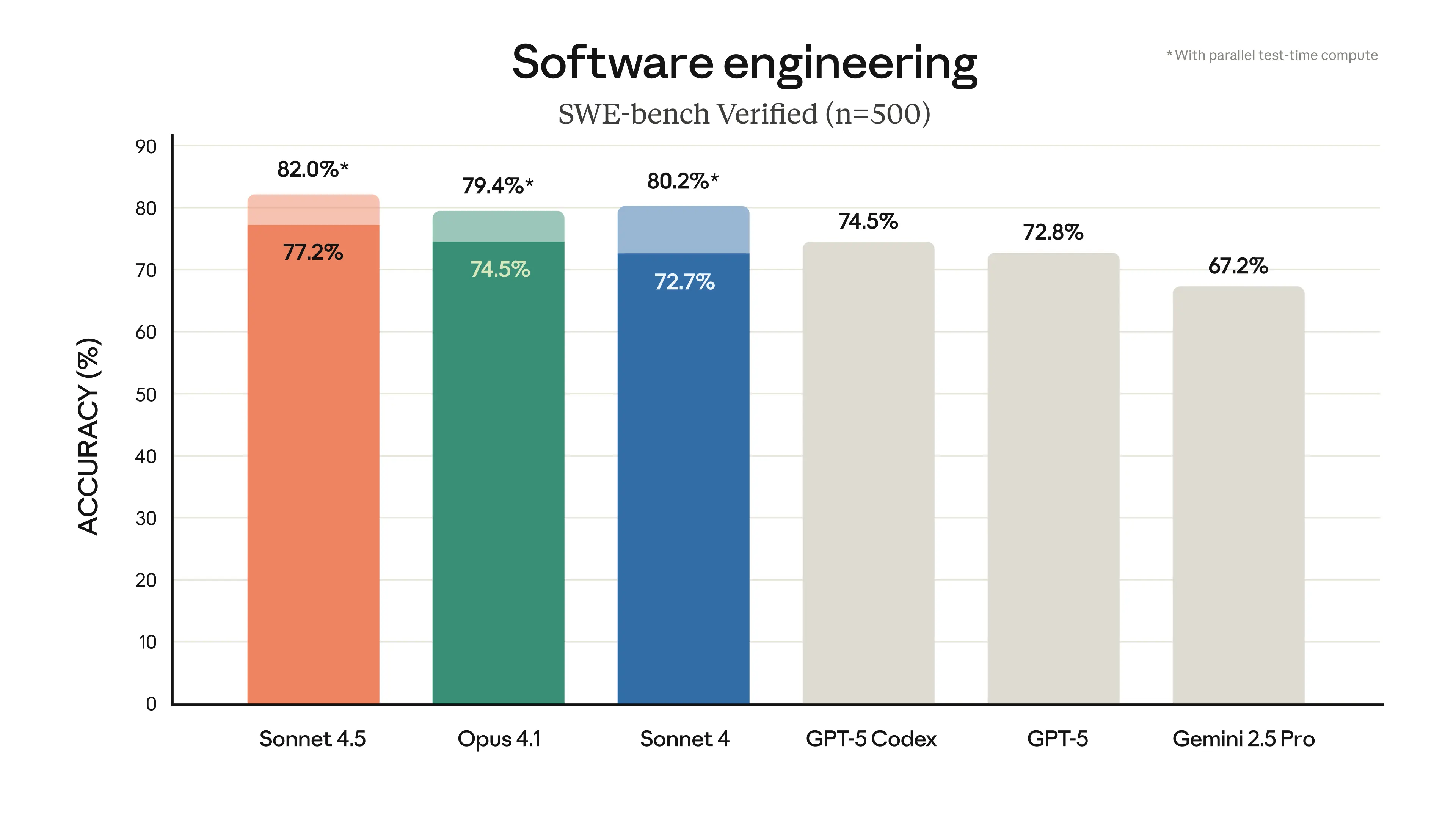
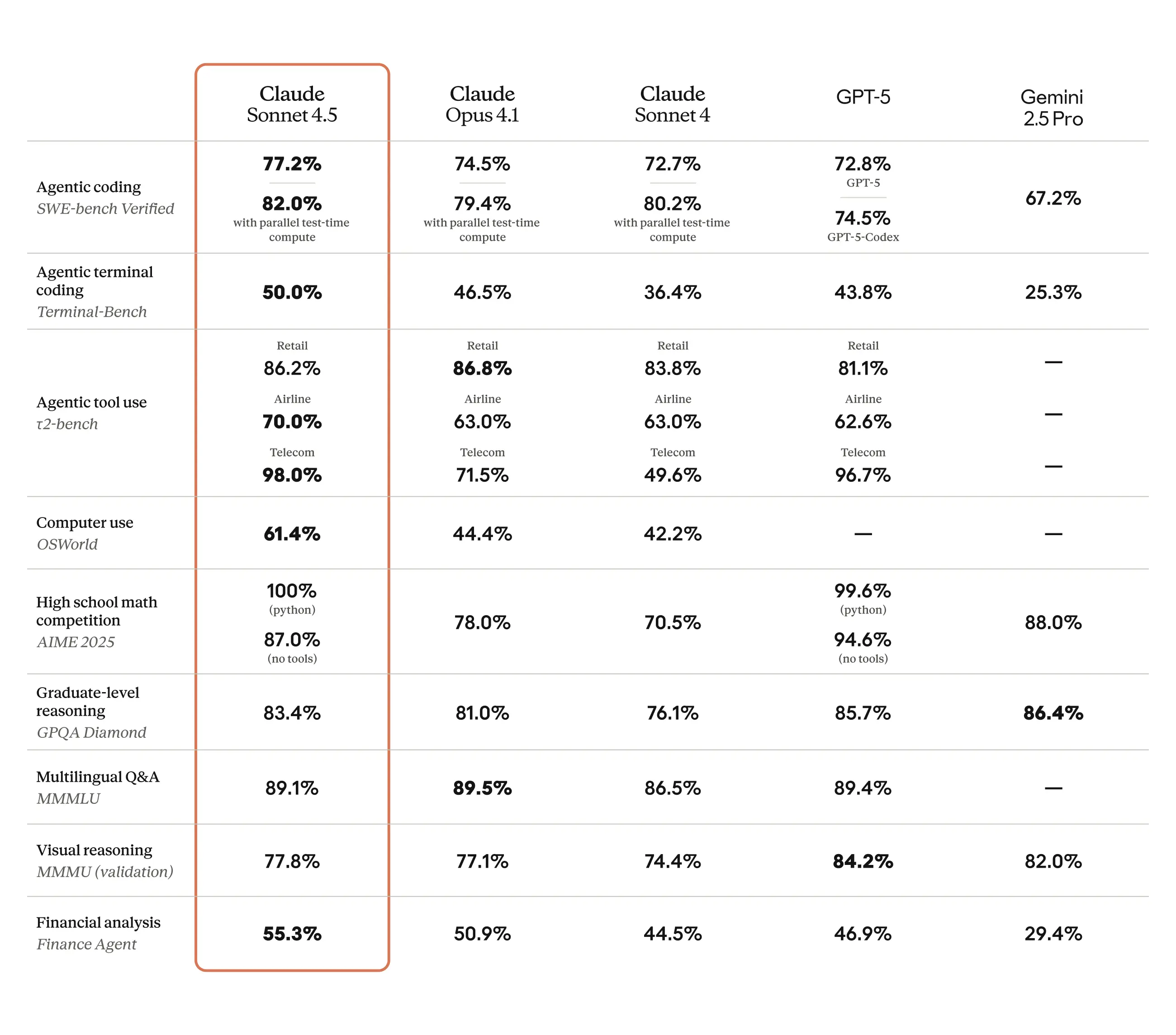
性能基准测试:可视化 Claude 4.5 Sonnet 的功能。
✨ 主要特点
- 💻 迄今为止最佳编码模型: 在 SWE-bench 验证中达到 77.2% 的准确率Sonnet 4.5 在编码基准测试方面树立了新的标杆。它在整个软件开发生命周期中都表现出色,从最初的规划和系统设计到复杂的调试。
- 🕑 扩展自主运行: 能够独立运行超过 30 小时,处理复杂的多步骤任务。它能保持思路清晰,并提供阶段性进度更新,从而确保长时间运行的关键工作流程的可靠性。
- 🧠 混合推理架构: 它集成了强大的扩展思维模式,可提高复杂编码和推理挑战的性能,并辅以标准的快速推理模式以提高效率。
- 🔒 提升安全保障: 它融合了强大的安全工程和先进的漏洞检测技术,显著降低了敏感代码和关键金融应用程序的风险。
- 📚 广泛的领域知识: 在特定领域推理方面展现出显著的进步 金融、网络安全、医学和STEM领域从而实现复杂的实际应用。
💲 Claude 4.5 Sonnet API 定价
| 定价指标 | 每百万Tokens成本 |
|---|---|
| 基础输入标记 | 3.15美元 |
| 5分钟缓存写入 | 3.9375美元 |
| 1小时缓存写入 | 6.30美元 |
| 缓存命中和刷新 | 0.315美元 |
| 输出标记 | 15.75美元 |
🎯 主要用例
- 💻 编程协助: 在较长时间内协助编写、调试和审查复杂的、多步骤代码。
- 🧠 自主代理: 管理协调多个软件工具和各种数据源的复杂工作流程。
- 💰 金融分析代理: 运用专业领域知识,熟练地解析和分析大型数据集。
- 🔒 网络安全自动化: 增强漏洞检测并实现威胁响应脚本自动化。
- 🔍 研究协助: 促进多智能体协调,以完成高级数据合成和摘要任务。
💻 代码示例
以下是如何与 Claude 4.5 Sonnet API 进行交互的示例:
import anthropic client = anthropic.Anthropic( # 默认为 os.environ.get("ANTHROPIC_API_KEY") api_key="my_api_key", ) message = client.messages.create( model="claude-sonnet-4.5", max_tokens=1024, messages=[ {"role": "user", "content": "用简单易懂的方式解释量子计算的优势。"} ] ) print(message.content) 🆚 与其他型号的比较
Claude·索内特 4.5 对 GPT-5
Claude Sonnet 4.5 在实际应用中被广泛认为是更优秀的编码模型,在实时编码测试和基准测试中经常超越 GPT-5 Codex。虽然 GPT-5 在某些高级抽象推理任务中可能略胜一筹,但 Sonnet 4.5 在复杂的多步骤编码方面表现出色,兼具速度和卓越的准确性。尽管价格更高,但 Sonnet 4.5 提供了强大的可靠性和增强的安全功能。
Claude·索内特 4.5 对 Qwen3-Next-80B
在实际编码和自主代理基准测试中,Sonnet 4.5 的性能优于 Qwen3-Next-80B,展现出更高的准确率和更强大的推理能力。Qwen3 虽然针对吞吐量效率进行了优化,但缺乏 Sonnet 4.5 所具备的高级多代理支持和专业领域知识。此外,Sonnet 4.5 还提供更完善的安全协议和更大的上下文窗口。
Claude·索内特 4.5 对 Gemini 2.5 Pro
Claude Sonnet 4.5 在编码基准测试中显著超越了 Gemini 2.5 Pro,取得了令人印象深刻的成绩。 在 SWE-bench 测试中,准确率达到 77.2%,而 Gemini 的准确率为 63.8%。它还支持更长时间的自主运行(超过 30 小时),并在智能体场景中提供卓越的多任务处理能力,使其成为复杂软件工程和高级 AI 智能体工作流程的首选。
Claude·索内特 4.5 对 作品4.1
十四行诗 4.5 标志着 Anthropic 之前的作品 4.1 有了显著的进步,展现出近乎…… 现实世界中人工智能计算机使用任务增加了 20%。 并提高了编码精度。新模型集成了先进的多智能体工具,并提供了更宽的上下文窗口,从而提高了准确性和任务的持续执行能力。

Claude 4.5 Sonnet 与其他领先的 AI 模型进行比较分析。
🔗 API 集成
Claude 4.5 Sonnet 可通过 AI/ML API 轻松访问。完整的文档如下: 此处提供指导您如何无缝集成到现有系统中。
❓ 常见问题解答 (FAQ)
是什么让 Claude 4.5 Sonnet 成为复杂软件开发的理想选择?
Claude 4.5 Sonnet 采用混合推理架构和先进的长期上下文管理技术,使其在多步骤编码、系统设计和调试方面表现出色。经 SWE-bench 验证,其准确率高达 77.2%,凸显了其在整个软件开发生命周期中的卓越性能,使其成为复杂项目的理想之选。
Claude 4.5 Sonnet 如何确保长期任务的一致性和专注性?
该模型通过先进的上下文窗口和外部文件状态感知功能,实现了卓越的长期状态跟踪。这使其能够在长达数小时甚至数天的会话中保持专注和连贯性,对于需要持续关注和逐步更新进度的复杂项目至关重要。
Claude 4.5 Sonnet 与其他领先的 AI 模型(如 GPT-5 或 Gemini 2.5 Pro)的主要区别是什么?
在实际编码基准测试和自主代理任务中,Claude 4.5 Sonnet 的性能通常优于 GPT-5 和 Gemini 2.5 Pro 等模型。例如,它在 SWE-bench 测试中达到了 77.2% 的准确率,而 Gemini 的准确率仅为 63.8%。此外,Claude 4.5 Sonnet 还拥有卓越的长期自主运行能力(超过 30 小时)和多代理协调能力。它注重可靠性和安全性,使其成为企业级应用的可靠选择。
Claude 4.5 Sonnet 能否用于金融和网络安全等高风险应用?
当然。Claude 4.5 Sonnet 专为严苛的实际环境而设计,集成了强大的安全工程、漏洞检测功能,并在金融和网络安全领域显著提升了特定领域的推理能力。其增强的准确性、可靠性和安全性使其非常适合对性能和道德标准有严格要求的敏感应用。
什么是“扩展思维模式”?它如何帮助解决问题?
扩展思维模式是 Claude 4.5 Sonnet 的一项独特功能,它能够进行更深层次的认知处理,以应对复杂的推理、多步骤编码和智能体工作流程。通过分配更多计算资源用于内省和深度思考,该模式显著提升了复杂任务的性能,确保更准确、更细致地解决问题,同时对延迟的影响也较小。

