 OpenAI - ChatGPT、Sora
OpenAI - ChatGPT、Sora Google - Gemini,Nano Banana
Google - Gemini,Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok DeepSeek
DeepSeek 阿里巴巴 - Qwen
阿里巴巴 - Qwen 字节跳动 - 豆包
字节跳动 - 豆包 所有型号
所有型号 企业API定制计划
企业API定制计划 AI应用开发服务
AI应用开发服务 AI智能翻译API
AI智能翻译API AI SEO/GEO 服务
AI SEO/GEO 服务 GEO/AI大模型优化
GEO/AI大模型优化 网络爬虫服务
网络爬虫服务 OpenClaw
OpenClaw 顶级人工智能工具
顶级人工智能工具 顶级人工智能机器人
顶级人工智能机器人
 登录
登录



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'deepseek/deepseek-v3.2-speciale',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2-speciale",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


产品详情
DeepSeek V3.2 特别版 是一个先进的、以推理为中心的大型语言模型 (LLM),旨在出色地完成多步骤逻辑问题求解和广泛的上下文处理。它拥有高达 1000 个上下文窗口的强大功能。 128K Tokens它专为复杂的分析任务而设计。一项突破性的功能是: “仅思考”模式这使得模型能够在生成任何输出之前进行内部静默推理。这种创新方法显著提高了准确性、事实一致性和逐步推理能力,尤其适用于复杂的查询。
该模型遵循 DeepSeek 的聊天前缀/FIM 代码补全规范,并提供强大的工具调用功能。它可通过 Speciale 端点在有限时间内访问,弥合了前沿研究与实际 AI 推理应用之间的差距,确保在代码生成、数学计算和科学探索等不同领域实现分析的一致性。
✨ 技术规格 ✨
- ✅ 建筑: 文本推理法学硕士
- ✅ 上下文长度: 128K Tokens
- ✅ 功能: 聊天、高级推理、工具使用、FIM完成
- ✅ 训练数据: 推理优化数据集,人工反馈对齐
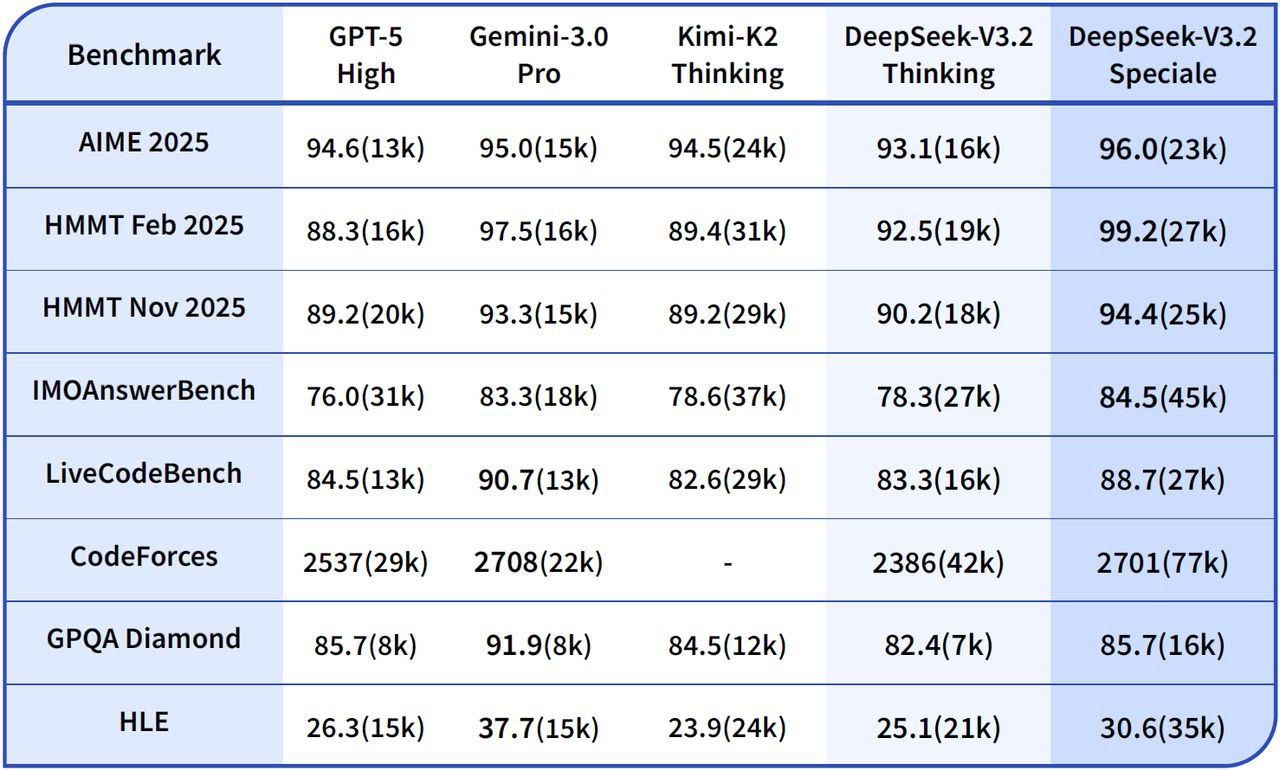
🧠 性能基准测试 🧠
- 📈复杂推理: 在多步骤链上表现出更高的稳定性,包括数学和符号任务。
- 💻 代码合成/调试: 提供更好的跟踪可解释性,有助于开发和调试过程。
💡 输出质量与推理性能 💡
🌟 质量改进
- ✔️ 逻辑推理: 一致的推理线程在超过 10 万个标记中保持连贯性。
- ✔️增强型错误恢复: 通过自适应注意力控制提高长链错误恢复能力。
- ✔️卓越的符号精确度: 在多变量逻辑和代码推理方面优于早期的 DeepSeek 模型。
- ✔️ 平衡的分析语气: 提供精准的解释,同时减少过拟合或语义漂移。
⚠️ 限制
- 正式语气: 在非正式场合中,这种说法可能显得过于正式或生硬。
- 延迟增加: “仅思考”模式会略微增加高度复杂链的延迟。
- 有限的创意变化: 与以故事叙述为导向的法学硕士相比,其创作基调变化较小。
🚀 新功能及技术升级 🚀
DeepSeek-V3.2-Speciale 引入了开创性的推理框架和内部优化层,旨在实现卓越的稳定性、可解释性和长上下文准确性。
主要升级
- 🧠 仅思考模式: 在用户可见的输出之前,增加了一个静默的认知过程,从而显著降低了矛盾率和幻觉,以获得更可靠的响应。
- 📏 扩展上下文窗口 (128K): 支持跨多个来源的全面长文档合成、持续对话记忆和数据驱动推理。
- 🔍内部链审计: 提供增强的推理过程可视性,对于验证多步骤推理和确保透明度的研究人员来说非常宝贵。
- ✏️ FIM(中间填空)完成: 无需重新提交整个程序即可进行上下文级别的插入和结构化代码修补,从而提高开发人员的效率。
实际影响
这些重大升级显著提升了DeepSeek V3.2 Speciale在数学、科学逻辑和长时间分析任务中的解读深度。因此,它非常适合复杂的自动化流程和高级认知研究实验。
💰 API 定价 💰
- 输入: 每百万个Tokens0.2977美元
- 输出: 每百万个Tokens0.4538美元
💻 代码示例 💻
# DeepSeek V3.2 Speciale API 调用示例 Python 代码 import openai client = openai.OpenAI( base_url="https://api.deepseek.com/v1", api_key="YOUR_API_KEY") response = client.chat.completions.create( model="deepseek/deepseek-v3.2-speciale", messages=[ {"role": "user", "content": "以逻辑方式逐步解释量子纠缠的概念。"}, {"role": "assistant", "content": "(仅思考模式已激活:解构查询、识别关键概念、规划逻辑步骤、回忆相关物理原理、将解释结构化为离散步骤。)"} ], # “仅思考”模式是一种内部机制。 # API 调用本身保持不变,但模型的内部处理方式会发生变化。 temperature=0.7, max_tokens=500 ) print(response.choices[0].message.content) 🆚 与其他型号的比较 🆚
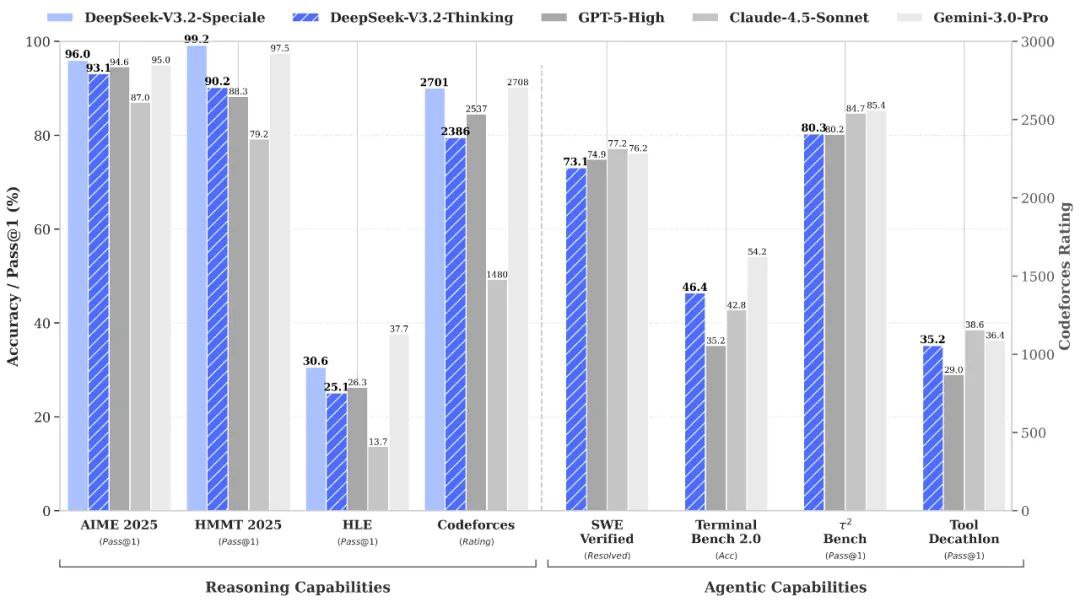
DeepSeek V3.2 特别版 vs. Gemini-3.0-Pro: 基准测试表明,DeepSeek-V3.2-Speciale 的整体性能与 Gemini-3.0-Pro 相当。然而,DeepSeek 更注重透明的、逐步推理,这使其在智能体人工智能应用中具有显著优势。
DeepSeek V3.2 特别版 vs. GPT-5: 评估报告显示,DeepSeek-V3.2-Speciale 在高难度推理工作负载方面优于 GPT-5,尤其是在数学密集型和竞赛型基准测试中。它在编码和工具使用可靠性方面也保持着很高的竞争力,为复杂任务提供了一个极具吸引力的替代方案。
DeepSeek V3.2 特别版 vs. DeepSeek-R1: Speciale 专为更极端的推理场景而设计,具有 128K 的上下文窗口和高计算能力的“思考模式”。这使其特别适合高级智能体框架和基准测试级别的实验,从而区别于专为更休闲的交互式使用而设计的 DeepSeek-R1。
💬 社区反馈 💬
用户对类似平台的反馈 Reddit DeepSeek V3.2 Speciale 一直被誉为高风险推理任务的杰出代表。开发者们尤其称赞其在基准测试中的统治地位和令人印象深刻的性价比,并指出它在数学、代码和逻辑基准测试中通常优于 GPT-5。 成本降低15倍许多用户称赞它在智能工作流程和复杂问题解决方面“表现出色”。用户还赞扬它在长链任务中展现出的惊人连贯性、显著降低的错误率以及“类人”的深度,尤其是在与之前的DeepSeek版本相比时。
❓常见问题解答❓
Q1:DeepSeek V3.2 Speciale 的主要关注点是什么?
A1:它主要侧重于高级推理和多步骤逻辑问题解决,专为代码、数学和科学领域的复杂分析任务而设计。
Q2:仅思考模式是如何运作的?
A2:此模式允许模型在生成任何可见输出之前进行内部静默推理。这种内部认知过程显著提高了准确性、事实一致性和响应的逻辑流畅性,尤其适用于复杂查询。
Q3:DeepSeek V3.2 Speciale 的最大上下文长度是多少?
A3:DeepSeek V3.2 Speciale 支持高达 128K 个标记的扩展上下文窗口,使其能够处理非常长的文档,保持持续的对话记忆,并跨多个来源执行数据驱动的推理。
第四季度:与其他型号相比,它的定价如何?
A4:社区反馈表明,DeepSeek V3.2 Speciale 提供了极具竞争力的价格,开发者报告称,对于类似的复杂任务,它的成本比 GPT-5 等一些竞争对手低 15 倍。
Q5:DeepSeek V3.2 Speciale 适合创意写作任务吗?
A5:虽然其分析推理能力很强,但与注重故事叙述的语言文学硕士相比,其“局限性”在于创造性表达方式较为单一。对于轻松随意或极具创造性的任务而言,其表达方式可能显得过于正式或僵硬。

