 OpenAI - ChatGPT、Sora
OpenAI - ChatGPT、Sora Google - Gemini,Nano Banana
Google - Gemini,Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok DeepSeek
DeepSeek 阿里巴巴 - Qwen
阿里巴巴 - Qwen 字节跳动 - 豆包
字节跳动 - 豆包 所有型号
所有型号 企业API定制计划
企业API定制计划 AI应用开发服务
AI应用开发服务 AI智能翻译API
AI智能翻译API AI SEO/GEO 服务
AI SEO/GEO 服务 GEO/AI大模型优化
GEO/AI大模型优化 网络爬虫服务
网络爬虫服务 OpenClaw
OpenClaw 顶级人工智能工具
顶级人工智能工具 顶级人工智能机器人
顶级人工智能机器人
 登录
登录



const axios = require('axios').default;
const api = axios.create({
baseURL: 'https://api.ai.cc/v1',
headers: { Authorization: 'Bearer ' },
});
const main = async () => {
const response = await api.post('/tts', {
model: 'inworld/tts-1-max',
text: 'OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.',
voice: 'coral',
});
console.log('Audio URL:', response.data.audio.url);
console.log('Characters:', response.data.usage.characters);
};
main();
import requests
def main():
url = "https://api.ai.cc/v1/tts"
headers = {
"Authorization": "Bearer ",
}
payload = {
"model": "inworld/tts-1-max",
"text": "OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.",
"voice": "coral"
}
response = requests.post(url, headers=headers, json=payload)
data = response.json()
print("Audio URL:", data["audio"]["url"])
print("Characters:", data["usage"]["characters"])
main()


产品详情
Inworld TTS-1-Max:革新文本转语音技术
探索 Inworld TTS-1-Max API这是一款基于Transformer的先进自回归文本转语音(TTS)模型。它旨在提供无与伦比的语音质量和表现力,是需要高分辨率、细致入微的语音合成的专业和商业应用的首选。
令人印象深刻 88亿个参数TTS-1-Max 突破了自然语言生成的界限,生成的声音几乎与人类语音无法区分。
技术规格及性能
- ⚙️ 建筑学: 基于Transformer的高级自回归模型
- 🔢 参数: 巨大的 88亿 (Inworld TTS-1 系列中最大的型号)
- 🔊 音频输出: 清晰、高分辨率 48 kHz 演讲
- 🌐 支持的语言: 全面支持 11种主要语言
- ⚡ 推理速度: 在 32 个 H100 显卡配置下,每个 GPU 每秒可处理约 8,000 个令牌,确保了效率。
在质量排行榜上名列前茅
TTS-1-Max 型号始终名列前茅 表现最佳者 在独立质量排行榜上,它在各种评价中都展现了其卓越的品质和自然的口感。
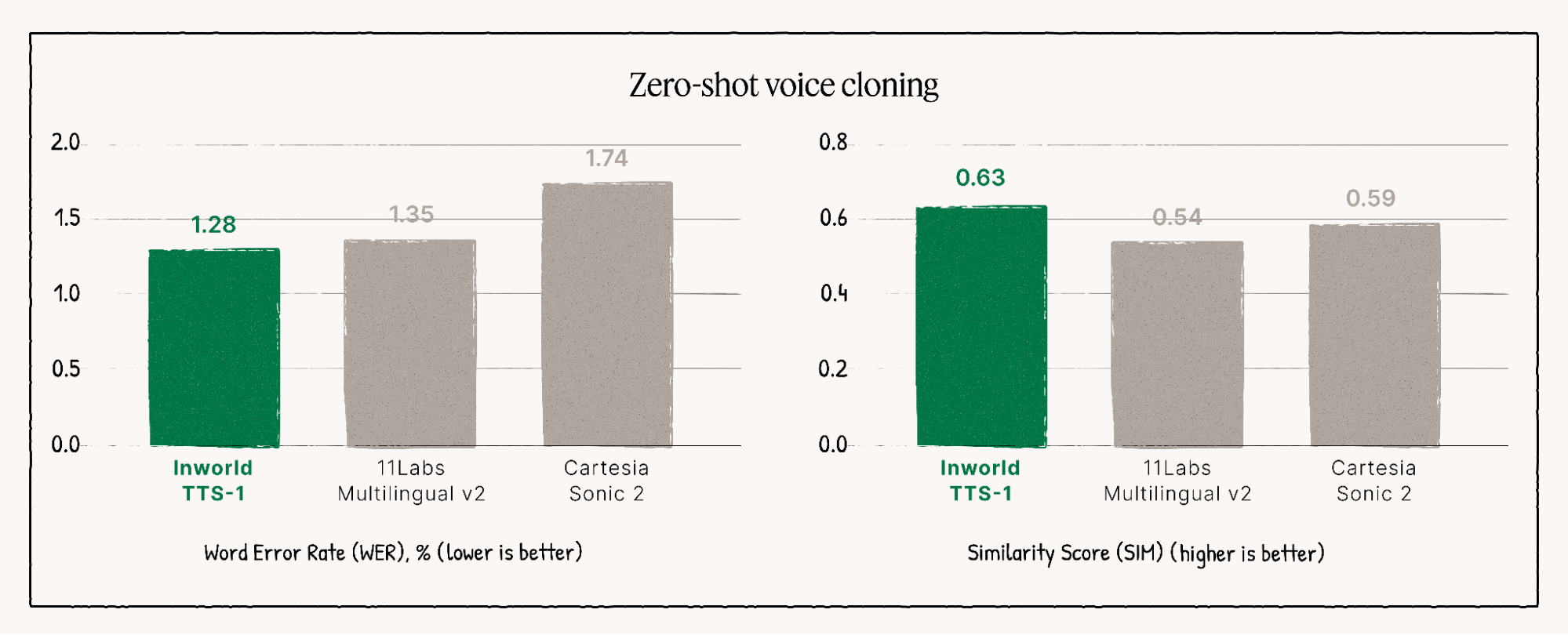
无与伦比的语音合成的关键特性
- ✨ 卓越的自然度和表现力: 利用大规模参数化技术,实现极其自然且情感丰富的语音输出。
- 🗣️ 高保真多语言合成: 生成清晰准确、极具感染力的语音 11种不同的语言非常适合全球应用。
- 🎭 高级情绪调节: 利用强大的情感调节功能微调语音风格,为每一句话增添深刻的细微差别和内涵。
- 👂 逼真的非语言声音和发声: 通过无缝支持各种非语言线索,增强语音真实感,使人工智能语音更加逼真。
- 👤 纯粹的上下文语音克隆: 无需任何预先录制的说话人数据,完全依靠复杂的上下文学习,即可实现语音克隆。
透明且具有竞争力的 API 定价
💰 体验优质语音合成技术,价格简单透明:
- 成本: 仅有的 10.5美元 每生成100万个字符。
- 预计每分钟费用: 大约 0.0105美元 每分钟生成高质量语音。
轻松集成:代码示例
将 Inworld TTS-1-Max 集成到您的应用程序中非常便捷。以下是 API 代码片段,方便您快速集成:
https://docs.ai.cc/api-references/speech-models/text-to-speech/inworld/tts-1-max " snippet data-name="voice.tts-openai" data-model="inworld/tts-1-max"> 有关完整的集成细节、高级参数和更多代码示例,请参阅 Inworld TTS-1-Max API 官方文档。
Inworld TTS-1-Max:竞争优势
了解 Inworld TTS-1-Max 如何从市场上其他领先的文本转语音模型中脱颖而出,为各种使用场景提供专门的优势。
🆚 与 Inworld TTS-1 的对比
TTS-1-Max 提供 卓越的表现力和自然感 由于其参数规模远大于TTS-1(88亿参数,而TTS-1为16亿参数),因此非常适合有声读物等优质内容。相比之下,TTS-1则更注重…… 实时速度 (~153 个字符/秒,而 TTS-1-Max 为 ~69 个字符/秒),因此更适合高度交互式的应用。
🆚 与 ElevenLabs 多语言版 V2 相比
在质量测试中,TTS-1-Max 达到了 59.1% 的直接对战胜率它提供更精细的情感表达,并通过标记对非语言声音提供强大的支持。虽然 ElevenLabs 提供了强大的多语言克隆功能,但 TTS-1-Max 更胜一筹。 原始音频分辨率 以及其情境学习方法的纯粹性。
🆚 与 MiniMax-Speech 相比
TTS-1-Max 优先 最佳语音质量 MiniMax-Speech 在其支持的 11 种语言中均展现出卓越的保真度,在自然度和情感韵律控制方面树立了行业标杆。相比之下,MiniMax-Speech 则更侧重于更广泛的 32 种语言零样本克隆功能和快速的单次语音复制。
常见问题解答 (FAQ)
❓ Inworld TTS-1-Max是什么?
Inworld TTS-1-Max 是一款基于 Transformer 的尖端自回归文本转语音 API,拥有 88 亿个参数。它专为对语音质量和表现力有较高要求的专业和商业应用而设计。
❓ 它的主要技术特点是什么?
它提供自回归 Transformer 架构、88 亿参数、48 kHz 高分辨率音频、支持 11 种主要语言,以及每个 GPU 每秒约 8,000 个标记的推理速度。
❓ TTS-1-Max是如何实现高表现力的?
它卓越的表现力和自然度源于其大规模的 88 亿参数化,再加上情感调节能力和对非语言声音的支持,从而创造出高度细致入微的语音。
❓ TTS-1-Max API 的定价结构是怎样的?
该 API 的定价为每百万个字符 10.5 美元,换算成生成语音每分钟的估计成本约为 0.0105 美元。
❓ Inworld TTS-1-Max 的理想使用场景有哪些?
它非常适合专业配音、配音、高级对话式人工智能、多语言媒体内容制作、交互式语音应用程序、有声读物、游戏和沉浸式虚拟环境,在这些领域,卓越的语音质量和表现力至关重要。

