 OpenAI - ChatGPT、Sora
OpenAI - ChatGPT、Sora Google - Gemini,Nano Banana
Google - Gemini,Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok DeepSeek
DeepSeek 阿里巴巴 - Qwen
阿里巴巴 - Qwen 字节跳动 - 豆包
字节跳动 - 豆包 所有型号
所有型号 企业API定制计划
企业API定制计划 AI应用开发服务
AI应用开发服务 AI智能翻译API
AI智能翻译API AI SEO/GEO 服务
AI SEO/GEO 服务 GEO/AI大模型优化
GEO/AI大模型优化 网络爬虫服务
网络爬虫服务 OpenClaw
OpenClaw 顶级人工智能工具
顶级人工智能工具 顶级人工智能机器人
顶级人工智能机器人
 登录
登录



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'alibaba/qwen3-vl-32b-instruct',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="alibaba/qwen3-vl-32b-instruct",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


产品详情
✨ 探索 Qwen3 VL 32B Instruct:您的高级视觉语言人工智能
这 Qwen3 VL 32B 指导 是一款尖端的大型视觉语言模型 (VL),专为在各种视觉任务中精准执行指令而设计。它最突出的特点是能够解读复杂的视觉输入,并生成高度连贯、上下文感知的文本输出。该模型经过精心优化,在图像描述、引人入胜的视觉对话和多样化的内容生成方面表现出色,使其成为多模态人工智能应用的强大工具。
如其详细所述 Qwen3 VL 32B 官方概述Qwen3 VL 32B Instruct 是一款“非思考型”版本,这意味着它针对直接、高效地执行视觉任务而非更广泛的一般推理进行了优化,从而确保在其专业领域内具有卓越的性能。
⚙️ 技术规格概览
- 型号: 视觉语言大型模型(VL)
- 参数数量: 320亿个参数
- 建筑学: 基于 Transformer 的多模态架构,集成了强大的视觉编码器和复杂的文本解码器。
- 输入方式: 支持图片+文字说明/提示的无缝集成。
- 输出方式: 专注于高质量文本生成(描述、对话、创意内容)。
- 训练数据: 基于庞大的大规模多模态数据集进行训练,该数据集包含精心标注的图像以及丰富的描述性和对话性文本。
- 推理能力: 提供强大的零次射击和少次射击指导,无需进行大量的再训练。
🚀 无与伦比的性能和基准
- 🎯 成就 最先进的精度 在领先的视觉描述数据集上,与 COCO Caption 和 VQA 任务进行了严格的基准测试。
- 📈 演示 卓越的指令遵循能力经人工评估验证,具有极高的相关性和连贯性。
- 💡 性能优于之前的 Qwen VL 版本 多模态内容生成质量和精确的指令对齐。
- 🔒展览 稳健的零样本性能 在复杂的视觉对话任务中,与基线模型相比,性能更优。
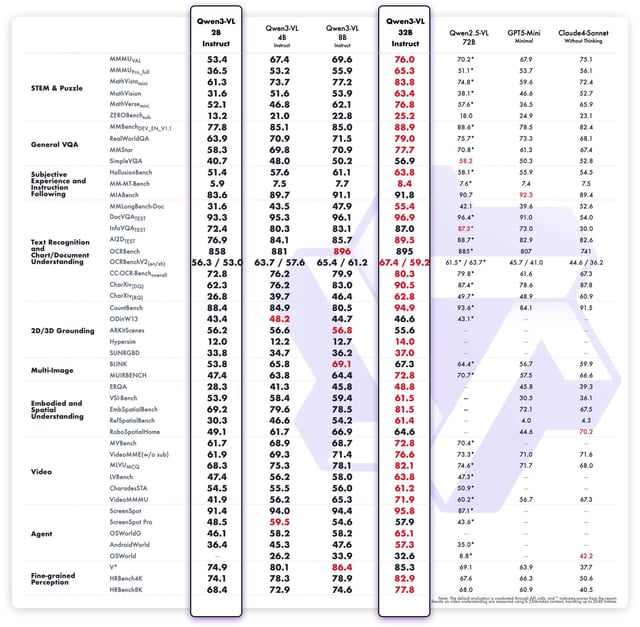
🌟 主要特点和优势
- ✨ 精确的图像描述: 针对用户指令进行了优化,可生成极其清晰准确的图像描述。
- 💬 引人入胜的视觉对话: 能够理解复杂的视觉环境并参与动态的视觉对话。
- 🎨 创意内容创作: 根据文本提示直接生成高度相关且富有创意的视觉内容。
- ✔️ 高教学一致性: 通过确保与用户说明高度一致,最大限度地减少无关或虚假内容。
- 🖼️ 高效的高分辨率处理: 能够高效处理大型高分辨率图像,并具备精细的视觉理解能力。
- 🌍 多语言输出: 支持多语言文本输出,展现出对多种语言的强大语言能力。
- 🔌 易于集成: 专为轻松集成到人工智能驱动的内容创作流程和交互式视觉助手而设计。
💰 Qwen3 VL 32B API 定价
- ➡️ 输入: 0.735 美元/百万Tokens
- ⬅️ 输出: 2.94 美元/百万Tokens
💡 多种应用场景
- 📸 自动图像描述: 非常适合用于数字资产管理系统,可提供即时、准确的描述。
- 🗣️ 视觉质量保证和客户支持: 增强客户服务机器人的交互式可视化问答功能。
- ✍️ 市场营销与内容创作: 利用图像为营销活动、社交媒体和创意故事讲述提供内容生成支持。
- 🚶♀️ 为视障人士提供的帮助: 对视觉场景的描述非常详尽,提供了宝贵的帮助。
- 🔍 增强型多媒体搜索: 通过先进的基于图像的上下文理解技术,提高搜索引擎的性能。
- 📚 教育应用: 支持交互式视觉讲解和教程,使学习更具吸引力。
💻 集成代码示例
下面是一个典型的代码片段,演示如何与 Qwen3 VL 32B 指令 API 进行交互。
import openai client = openai.OpenAI( api_key="YOUR_API_KEY", # 替换为您的实际 API 密钥 base_url="https://api.your-provider.com/v1" # 替换为您的 API 端点 ) response = client.chat.completions.create( model="alibaba/qwen3-vl-32b-instruct", messages=[ {"role": "system", "content": "您是一位可以描述图像的助手。"}, {"role": "user", "content": [ {"type": "text", "text": "这张图片里有什么?"}, {"type": "image_url", "image_url": {"url": "https://example.com/image.jpg"}} ]} ], max_tokens=500 ) print(response.choices[0].message.content) 🆚 Qwen3 VL 32B 教练机与其他主流机型对比
对阵 Qwen3 VL 32B 基地:
这 指导版 该模型经过精心调整,能够更好地遵循指令,从而产生更贴合语境且更准确的描述。相比之下,基础模型主要针对一般的多模态理解。
与 OpenAI GPT-4(具备视觉功能)相比:
Qwen3 VL 32B Instruct 专为特定指令执行和视觉内容生成而设计和优化,在处理视觉输入时表现出更少的错觉。虽然 GPT-4 提供更广泛的通用人工智能功能,但它在直接执行视觉指令方面可能不够专业。
vs. Claude 4.5 视觉效果:
Qwen3 VL 32B Instruct 提供更强大的图像描述和对话质量,并着重强调视觉指令。Claude 虽然在基于文本的推理和处理大型上下文方面表现出色,但在视觉方面的专业性通常略逊一筹。
与 DeepSeek V3.1 相比:
Qwen3 VL 32B Instruct 擅长生成详细的内容和复杂的图像可视化任务。而 DeepSeek 则更侧重于语义图像搜索和检索功能。
❓ 常见问题解答 (FAQ)
问:Qwen3 VL 32B Instruct 的主要设计用途是什么?
答:它是一种专门的视觉语言模型,针对指令遵循任务进行了优化,例如精确的图像描述、引人入胜的视觉对话以及基于视觉输入和文本提示的智能内容生成。
问:Qwen3 VL 32B Instruct 与其基础版本相比有何不同?
答:指导版经过专门调整,可增强教学执行力,从而产生更准确、更符合上下文的描述,这与提供一般多模态理解的基础模型不同。
问:使用 Qwen3 VL 32B Instruct 的主要优势是什么?
答:主要优势包括精确的图像描述、强大的视觉对话功能、具有高度指令对齐性的创意内容生成、高效的高分辨率图像处理以及多语言文本输出。
问:Qwen3 VL 32B Instruct 能否应用于实际应用中?
答:当然。它非常适合用于自动图像字幕生成、客户服务中的视觉问答、人工智能驱动的内容创作、辅助视障用户、增强多媒体搜索以及互动式教育工具。
问:Qwen3 VL 32B API 的定价结构是怎样的?
答:定价是分级的:投入成本为每百万个Tokens 0.735 美元,产出成本为每百万个Tokens 2.94 美元。

