 OpenAI - ChatGPT、Sora
OpenAI - ChatGPT、Sora Google - Gemini,Nano Banana
Google - Gemini,Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok DeepSeek
DeepSeek 阿里巴巴 - Qwen
阿里巴巴 - Qwen 字节跳动 - 豆包
字节跳动 - 豆包 所有型号
所有型号 企业API定制计划
企业API定制计划 AI应用开发服务
AI应用开发服务 AI智能翻译API
AI智能翻译API AI SEO/GEO 服务
AI SEO/GEO 服务 GEO/AI大模型优化
GEO/AI大模型优化 网络爬虫服务
网络爬虫服务 OpenClaw
OpenClaw 顶级人工智能工具
顶级人工智能工具 顶级人工智能机器人
顶级人工智能机器人
 登录
登录

在
出去


Text to Speech
const main = async () => {
const response = await fetch('https://api.ai.cc/v2/generate/video/alibaba/generation', {
method: 'POST',
headers: {
Authorization: 'Bearer ',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'alibaba/wan2.2-t2v-plus',
prompt: 'A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background',
aspect_ratio: '16:9',
}),
}).then((res) => res.json());
console.log('Generation:', response);
};
main()
import requests
def main():
url = "https://api.ai.cc/v2/generate/video/alibaba/generation"
payload = {
"model": "alibaba/wan2.2-t2v-plus",
"prompt": "A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background",
"aspect_ratio": "16:9",
}
headers = {"Authorization": "Bearer ", "Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print("Generation:", response.json())
if __name__ == "__main__":
main()

.webp)
Wan 2.2 Plus 文字转视频
产品详情
阿里巴巴的 万2.2 是最先进的 人工智能模型 为先进技术精心设计 多模态理解它无缝集成了文本和视觉输入,为大型上下文处理提供了强大的功能,并在复杂的文本到视觉任务和复杂的推理挑战中提供了卓越的精度。
✨ 技术规格
性能基准
- ✅ VQA基准测试: 78.3%
- ✅ 多模态推理: 52.7%
- ✅ 跨模态检索: 81.9%
性能指标(WAN2.1)
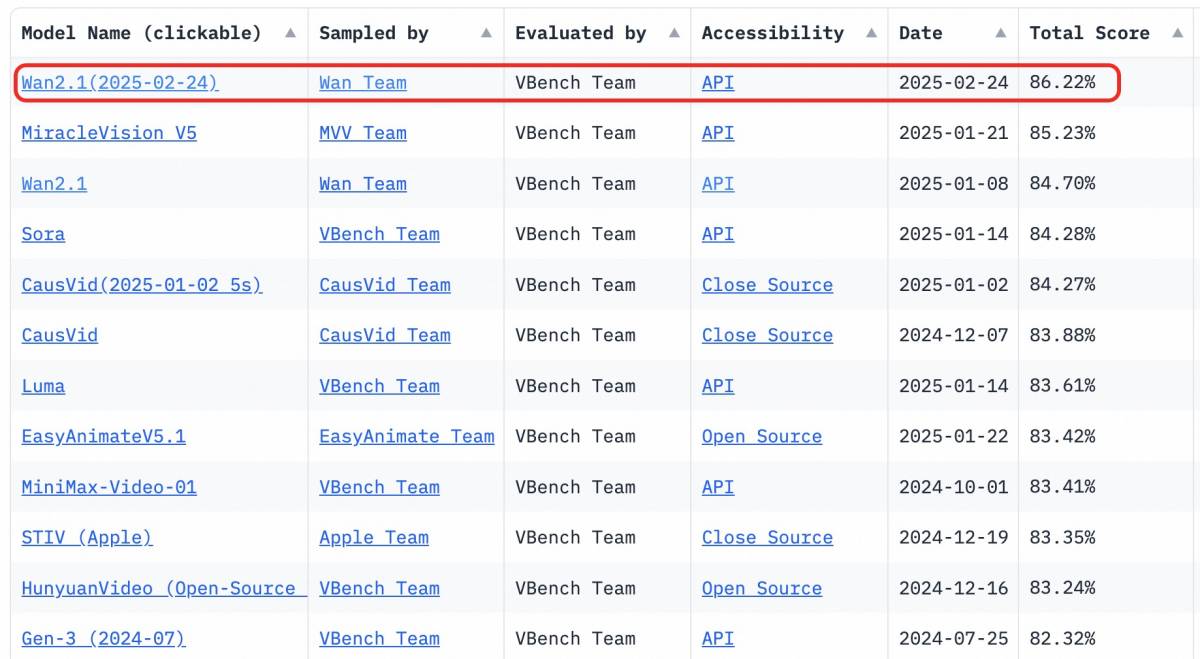
Wan2.1 以令人印象深刻的整体表现领先。 VBench 得分 86.22%该模型在动态运动、空间关系、色彩准确度和多对象交互方面均展现出卓越的性能。训练基础视频模型需要强大的计算能力和海量高质量数据集。开放获取此类先进模型可大幅降低门槛,使更多企业能够以经济高效的方式创建定制化的高质量视觉内容。
主要能力
- 💡 视觉语言融合: 擅长通过无缝结合图像和文本数据来解读和生成精确的响应。
- 💡 高级推理: 展现出强大的多步骤推理能力,能够运用多种方式进行深入分析和复杂理解。
💲 API 定价
- 🎥 480P: 每视频 0.105 美元
- 🎥 1080P: 每视频 0.525 美元
🚀 最佳使用场景
- ✅ 多模态分析: 通过图像和文本数据的巧妙结合,增强理解力。
- ✅ 可视化问答(VQA): 基于图像-文本融合输入,提供准确且具有上下文感知能力的答案。
- ✅ 跨模态检索: 实现跨视觉和语言领域的高效信息匹配和检索。
- ✅ 商业智能: 通过将视觉内容与文本分析相结合,促进复杂数据的解读,从而获得更深入的见解。
💻 代码示例
📊 与其他领先型号的比较
- 对比 双子座 2.5 闪光灯: 阿里巴巴WAN2.2提供更高的多模态准确率(78.3% 与 70.8% VQA 基准测试相比因此,它是视觉语言集成任务的更佳选择。
- 与 OpenAI GPT-4 Vision 的对比: Wan2.2 提供了一个明显更大的上下文窗口(65K 对比 32K Tokens文本),从而能够进行更广泛、更连贯的对话,并嵌入图像。
- 对阵 Qwen3-235B-A22B: 阿里巴巴WAN2.2展现出卓越的跨模态检索精度(81.9% 与约78%的估计值相比),并针对要求苛刻的大规模视觉语言工作流程进行优化。
⚠️ 限制
有时,生成的视频可能包含一些不必要的元素,例如文字痕迹或水印。虽然使用否定提示可以帮助减少这种情况的发生,但并不能完全消除它们。
🔗 API 集成
可通过以下方式轻松访问阿里巴巴WAN2.2: AI/ML API我们提供全面的文档资料,以帮助您顺利高效地完成集成过程。
❓ 常见问题解答 (FAQ)
问:阿里巴巴WAN2.2的主要设计用途是什么?
答:阿里巴巴 Wan2.2 是一款先进的 AI 模型,专为多模态理解而设计,尤其擅长整合文本和视觉输入,以进行复杂的推理和高精度的文本到视觉任务。
答:阿里巴巴 Wan2.2 是一款先进的 AI 模型,专为多模态理解而设计,尤其擅长整合文本和视觉输入,以进行复杂的推理和高精度的文本到视觉任务。
问:与 Gemini 2.5 Flash 等其他型号相比,Wan2.2 的性能如何?
答:Wan2.2 的多模态准确率(78.3% VQA-bench)高于 Gemini 2.5 Flash(70.8%),使其在视觉语言集成任务中特别有效。
答:Wan2.2 的多模态准确率(78.3% VQA-bench)高于 Gemini 2.5 Flash(70.8%),使其在视觉语言集成任务中特别有效。
问:阿里巴巴WAN2.2的主要功能有哪些?
答:其主要功能包括强大的视觉语言融合,用于解释和生成来自图像和文本组合数据的内容,以及跨模态的高级多步骤推理。
答:其主要功能包括强大的视觉语言融合,用于解释和生成来自图像和文本组合数据的内容,以及跨模态的高级多步骤推理。
问:使用 Wan2.2 时是否存在任何已知的限制?
答:有时,生成的视频可能包含一些不必要的元素,例如文字痕迹或水印。虽然负面提示可以减轻这些问题,但无法完全消除。
答:有时,生成的视频可能包含一些不必要的元素,例如文字痕迹或水印。虽然负面提示可以减轻这些问题,但无法完全消除。
问:企业如何将阿里巴巴WAN2.2集成到自己的系统中?
答:阿里巴巴WAN2.2可通过AI/ML API轻松访问,并提供全面的文档来指导集成过程。
答:阿里巴巴WAN2.2可通过AI/ML API轻松访问,并提供全面的文档来指导集成过程。

