 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in













2026 AI API Comparison: OpenAI vs Anthropic Claude vs Google Gemini vs Grok

2026 AI API Comparison:
OpenAI vs Claude
vs Gemini vs Grok
In March 2026, the AI API landscape has never been more competitive — or more confusing. With Grok 4.1 Fast shattering price records, Gemini 3.1 Pro dominating long-context reasoning, and Claude Opus 4.6 leading on coding and writing, choosing the right LLM API can make or break your project budget. This guide breaks down pricing, benchmarks, strengths, and integration code for all four leaders.
%252520Top%252520Large%252520Language%252520Models_%252520A%252520Comparative%252520Analysis.png)
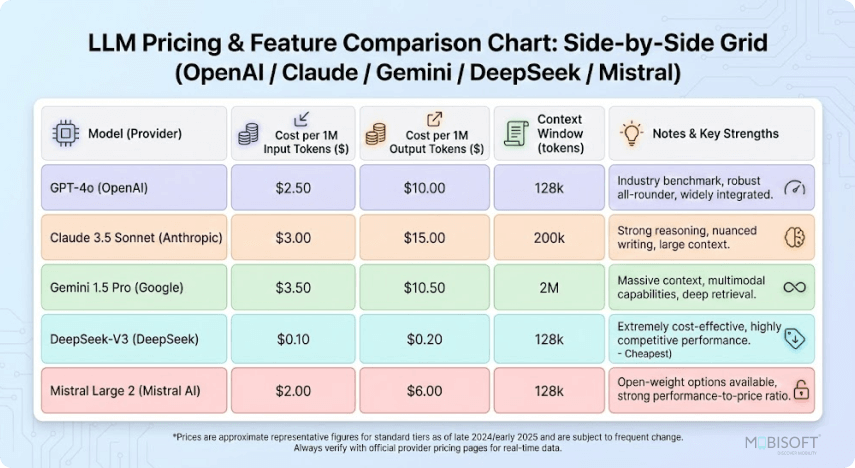
// Modern LLM API pricing and feature comparison — visual overview of cost structures across major providers (2026)
2026 AI API Pricing (Per 1M Tokens)
Pricing has converged dramatically, but huge gaps remain — especially at scale. Latest data, March 2026:
| Provider | Model | Input ($/1M) | Output ($/1M) | Context Window | Best For | Cached Discount |
|---|---|---|---|---|---|---|
| OpenAI | GPT-5.4 (flagship) | $2.50 | $15.00 | 400K+ | Balanced enterprise | Up to 90% |
| OpenAI | GPT-5.4-mini | $0.75 | $4.50 | 400K | Coding & agents | Up to 90% |
| Anthropic | Claude Opus 4.6 | $5.00 | $25.00 | 200K (1M beta) | Deep reasoning & writing | Strong caching |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 200K (1M beta) | Most popular sweet spot | Strong caching |
| Gemini 3.1 Pro | $2.00 | $12.00 | 2M | Multimodal & long context | Excellent | |
| Gemini 3 Flash | $0.50 | $3.00 | 1M+ | High-volume speed | Excellent | |
| xAI Grok | Grok 4.1 Fast | $0.20 | $0.50 | 2M | Cost-sensitive & coding | Competitive |
| xAI Grok | Grok 4 | $3.00 | $15.00 | 256K–2M | Real-time & uncensored | Competitive |
Key takeaway: Grok 4.1 Fast is the undisputed cheapest high-context option in 2026. Claude Opus 4.6 remains premium-priced but delivers unmatched depth. Gemini offers the best price-to-context ratio for multimodal work.

// Gemini vs GPT vs Claude vs Grok — AI model capability comparison (2026)
Performance Benchmarks — March 2026
No single model wins everything. Here's how they stack up on leading independent benchmarks:
| Benchmark | Gemini 3.1 Pro | Claude Opus 4.6 | GPT-5.4 | Grok 4.1 Fast | Winner |
|---|---|---|---|---|---|
| GPQA Diamond (PhD-level) | 94.3% | 91.3% | 92.8% | ~88% | Gemini |
| ARC-AGI-2 (novel reasoning) | 77.1% | 68.8% | ~70% | ~16% | Gemini |
| SWE-Bench (coding) | 80.6% | 80.8% | 74.9% | ~75% | Claude |
| LiveCodeBench (coding) | Strong | Leader | Strong | Strong | Claude |
| Multimodal (vision/video) | Native leader | Good | Strong | Text-first | Gemini |
| Real-time / Uncensored | Good | Conservative | Good | Leader | Grok |
& writing
massive context
production
coding/agents
Pros, Cons & Best Use Cases


Integration Code Examples — Python 2026
Minimal, production-ready examples using official SDKs. All can be swapped in under 5 minutes on a unified platform.
from openai import OpenAI client = OpenAI(api_key="your-openai-key") response = client.chat.completions.create( model="gpt-5.4", messages=[{"role": "user", "content": "Explain quantum computing in one paragraph"}], temperature=0.7 ) print(response.choices[0].message.content) 
// AI coding dashboard showing LLM-assisted development workflow
from anthropic import Anthropic client = Anthropic(api_key="your-anthropic-key") response = client.messages.create( model="claude-4.6-sonnet", max_tokens=1024, messages=[{"role": "user", "content": "Write a professional email..."}] ) print(response.content[0].text) import google.generativeai as genai genai.configure(api_key="your-gemini-key") model = genai.GenerativeModel("gemini-3.1-pro") response = model.generate_content("Analyze this image and summarize trends", stream=False) print(response.text) from xai import Grok # Official SDK client = Grok(api_key="your-grok-key") response = client.chat.completions.create( model="grok-4.1-fast", messages=[{"role": "user", "content": "Latest X trends on AI agents"}], temperature=0.8 ) print(response.choices[0].message.content) Pro tip: Use LangChain or LlamaIndex to abstract these away completely — then switch models with one line of code.
Cost Optimization Tips for 2026
- Use caching — all four providers now support it heavily, with up to 90% savings on repeated context.
- Route simple tasks to cheaper models: Grok 4.1 Fast or Gemini Flash for high-volume requests.
- Use Batch API where available — 50%+ savings on non-realtime workloads.
- Monitor token usage in real time — small prompt engineering changes can cut costs 30–70%.

// Felix — multi-backend AI development dashboard for monitoring spend and routing across LLM providers
Stop Juggling APIs.
Start Building Faster.
Managing four different SDKs, keys, rate limits, and billing dashboards is painful. Smart teams consolidate on one platform with one key, one dashboard, and instant access to every major model.