 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots Log in
Log in












1
Complex Coding & Debugging
Claude Sonnet 4.6 remains king. It understands entire repositories better and makes fewer "confident but wrong" edits.

Benchmarks, real-world tests, pricing, use cases & expert verdict — everything you need to choose the right model.
February 2026 will be remembered as the month the AI frontier split in two. Google unleashed Gemini 3.1 Pro on February 19, while Anthropic dropped Claude Sonnet 4.6 just 48 hours earlier on February 17. Both models deliver near-Opus-level intelligence, yet they excel in completely different ways.
Gemini 3.1 Pro dominates raw intelligence benchmarks. Claude Sonnet 4.6 punches far above its weight in practical, production-ready tasks.
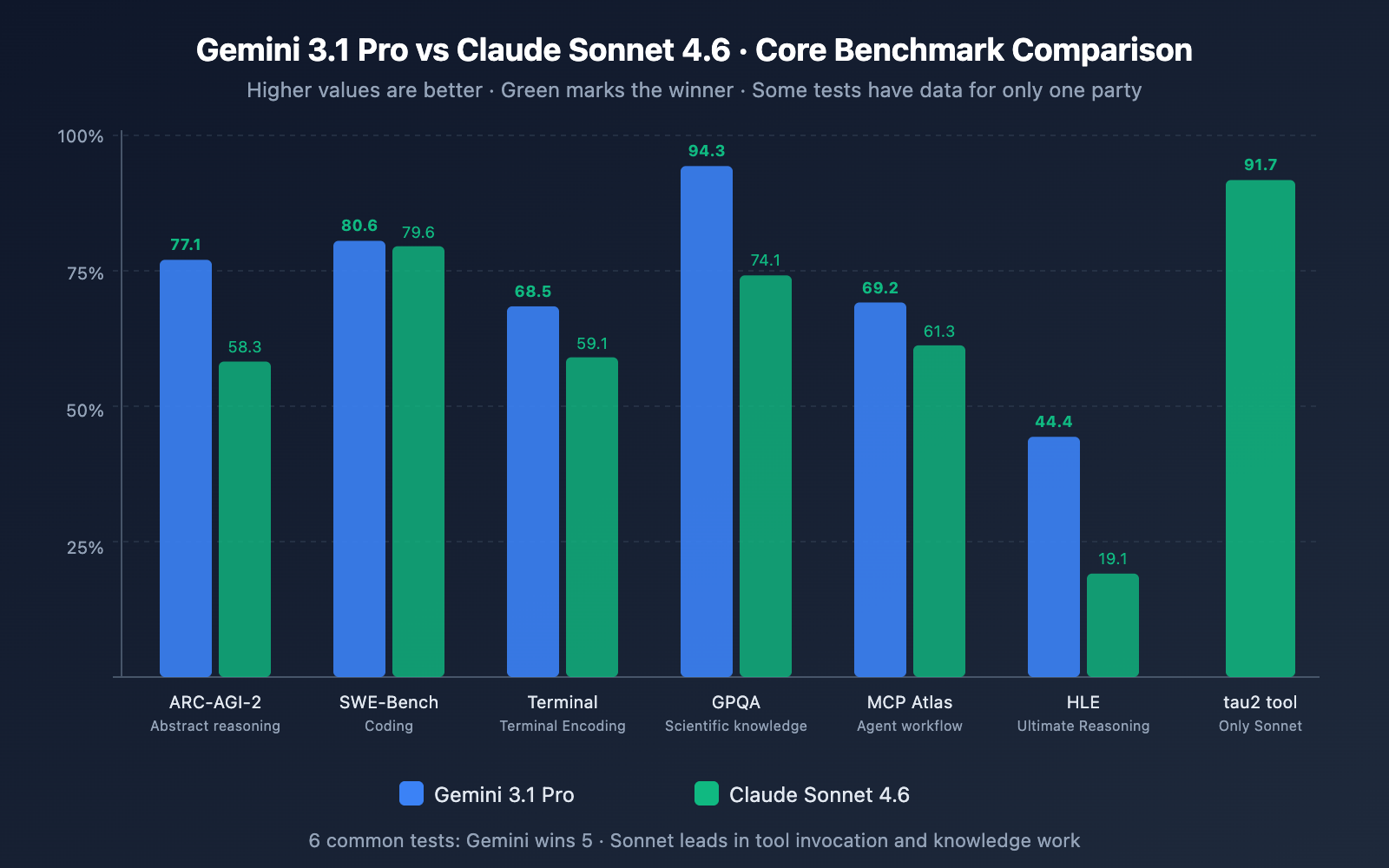
| Benchmark | Gemini 3.1 Pro | Claude Sonnet 4.6 | Winner | What It Tests |
|---|---|---|---|---|
| ARC-AGI-2 (Abstract Reasoning) | 77.1% | 58.3% | Gemini +18.8 pts | Novel puzzle-solving, generalization |
| GPQA Diamond (Graduate Science) | 94.3% | 74.1% | Gemini +20.2 pts | PhD-level physics, chemistry, biology |
| Humanity's Last Exam (HLE) | 44.4% | 19.1% | Gemini +25.3 pts | Frontier-level multi-step reasoning |
| SWE-Bench Verified (Coding) | 80.6% | 79.6% | Claude (near tie) | Real GitHub issue resolution |
| MCP Atlas (Multi-step Agent) | 69.2% | 61.3% | Gemini +7.9 pts | Agentic planning + execution |
| tau2 Tool Invocation | — | 91.7% | Claude | Reliable tool calling & computer use |

Claude Sonnet 4.6 remains king. It understands entire repositories better and makes fewer "confident but wrong" edits.

Gemini 3.1 Pro is untouchable — native video understanding up to 1 hour, audio transcription + reasoning in one pass.
Gemini edges out in breadth; Claude wins on reliability and fewer execution loops.
Research synthesis, creative long-form, data analysis, legal review, math proofs, UI automation, enterprise RAG — the pattern is clear: Gemini for intelligence breadth, Claude for execution reliability.
Reddit · X (Twitter) · Hacker News — Feb 20–27 2026
Gemini finally feels like GPT-5 level on reasoning
70%+ of developers still default to Claude Sonnet 4.6 for Copilot-style coding
We run Gemini for strategy decks, Claude for actual code deployment
The strategy top teams actually use in 2026
Unified API platforms let you switch with one line of code.

Expect Gemini 3.2 with even stronger video understanding and 2M context, and Claude Opus 4.7 or Sonnet 5.0 pushing coding benchmarks even further. The real winner in late 2026? Users who master multi-model orchestration.