 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in



const Anthropic = require('@anthropic-ai/sdk');
const api = new Anthropic({
baseURL: 'https://api.ai.cc/',
authToken: '',
});
const main = async () => {
const message = await api.messages.create({
model: 'anthropic/claude-sonnet-4.5',
max_tokens: 2048,
system: 'You are an AI assistant who knows everything.',
messages: [
{
role: 'user',
content: 'Tell me, why is the sky blue?',
},
],
});
console.log('Message:', message);
};
main();
import asyncio
from anthropic import Anthropic
client = Anthropic(
base_url="https://api.ai.cc/",
auth_token="",
)
def main():
message = client.messages.create(
model="anthropic/claude-sonnet-4.5",
max_tokens=2048,
system="You are an AI assistant who knows everything.",
messages=[
{
"role": "user",
"content": "Hello, Claude",
}
],
)
print("Message:", message.content)
if __name__ == "__main__":
main()


Product Detail
🚀 Elevate Your Projects with Claude 4.5 Sonnet API
Anthropic's Claude 4.5 Sonnet stands out as one of the most sophisticated AI models available, specifically engineered for excellence in software coding, executing complex agent tasks, and enabling extensive autonomous computer usage. This model is exceptionally adept at handling multi-step processes over long durations, demonstrating superior reasoning, deep domain knowledge, and seamless interaction with computer systems.
Designed for mission-critical environments, Sonnet 4.5 delivers unparalleled accuracy, reliability, and safety across demanding real-world applications such as finance, cybersecurity, research, and advanced development workflows.
⚙️ Technical Specifications
- 💻 Primary Strengths: Specializes in software engineering, complex agents, and automating computer usage.
- 📜 SWE-bench Verified: Achieves an impressive 77.2% accuracy with its extended thinking mode enabled, demonstrating top-tier coding proficiency.
- 💬 OSWorld Benchmark: Scores 61.4% for real-world computer task completion, highlighting its practical utility.
- 🧠 Extended Thinking Mode: Significantly enhances performance on intricate reasoning, multi-step coding, and agentic workflows by allowing for deeper cognitive processing, albeit with a slight trade-off in latency and caching efficiency.
- 📚 Context Management: Features exceptional long-term state tracking through an advanced context window and awareness of external file states, ensuring effective memory and sustained focus over sessions spanning many hours.
📊 Performance Benchmarks
Sonnet 4.5's advanced long-term context management allows it to maintain critical awareness and focus throughout sessions lasting hours. This capability is vital for demanding coding projects, sophisticated multi-agent coordination, and prolonged computer interactions. Its enhanced tool usage enables the model to control multiple processes concurrently, boosting efficiency in autonomous workflows like complex software debugging, data synthesis, and in-depth financial or cybersecurity analysis. A key differentiator is its hybrid architecture, supporting both rapid reasoning and a specialized extended thinking mode for profound problem-solving.
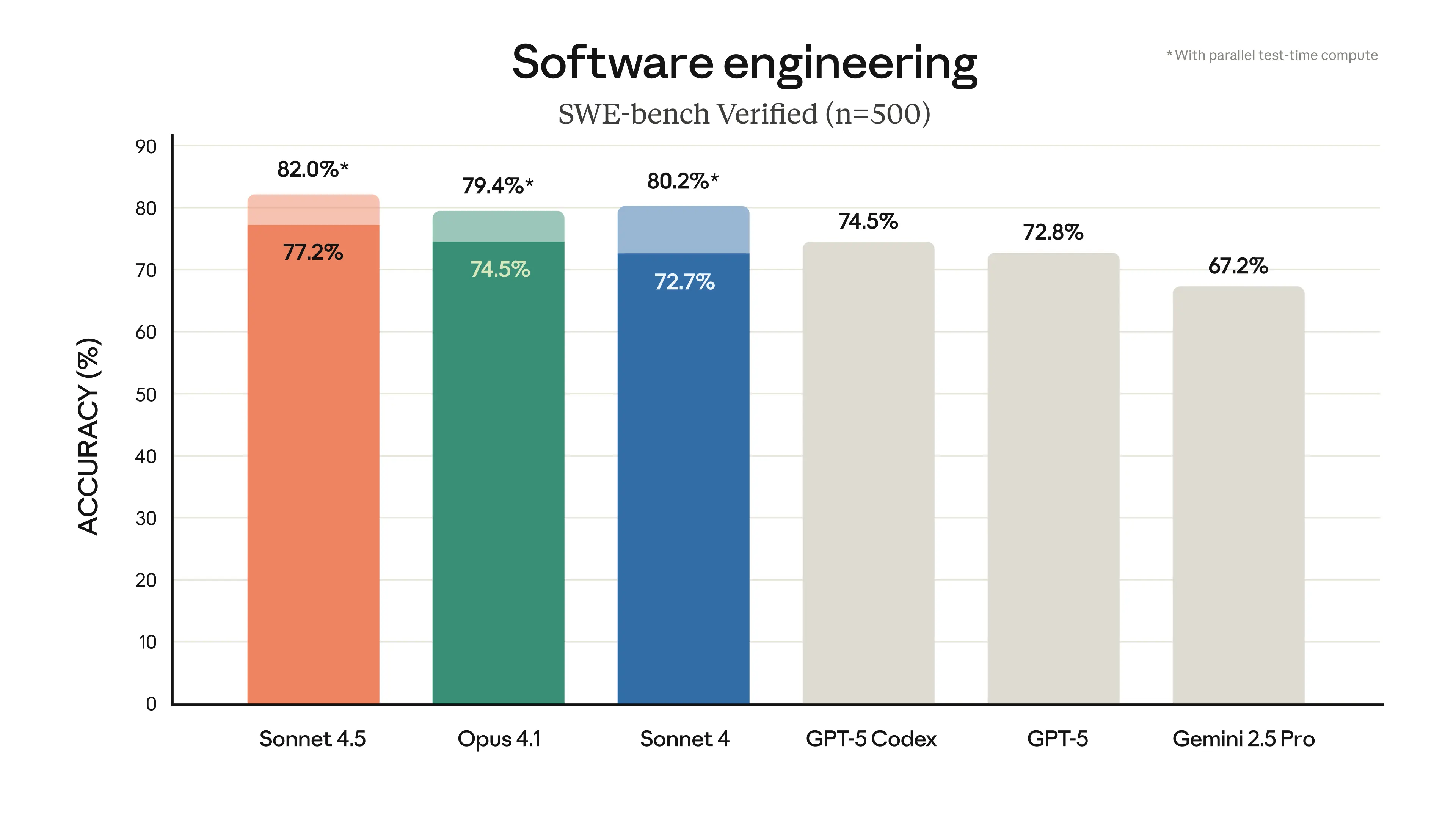
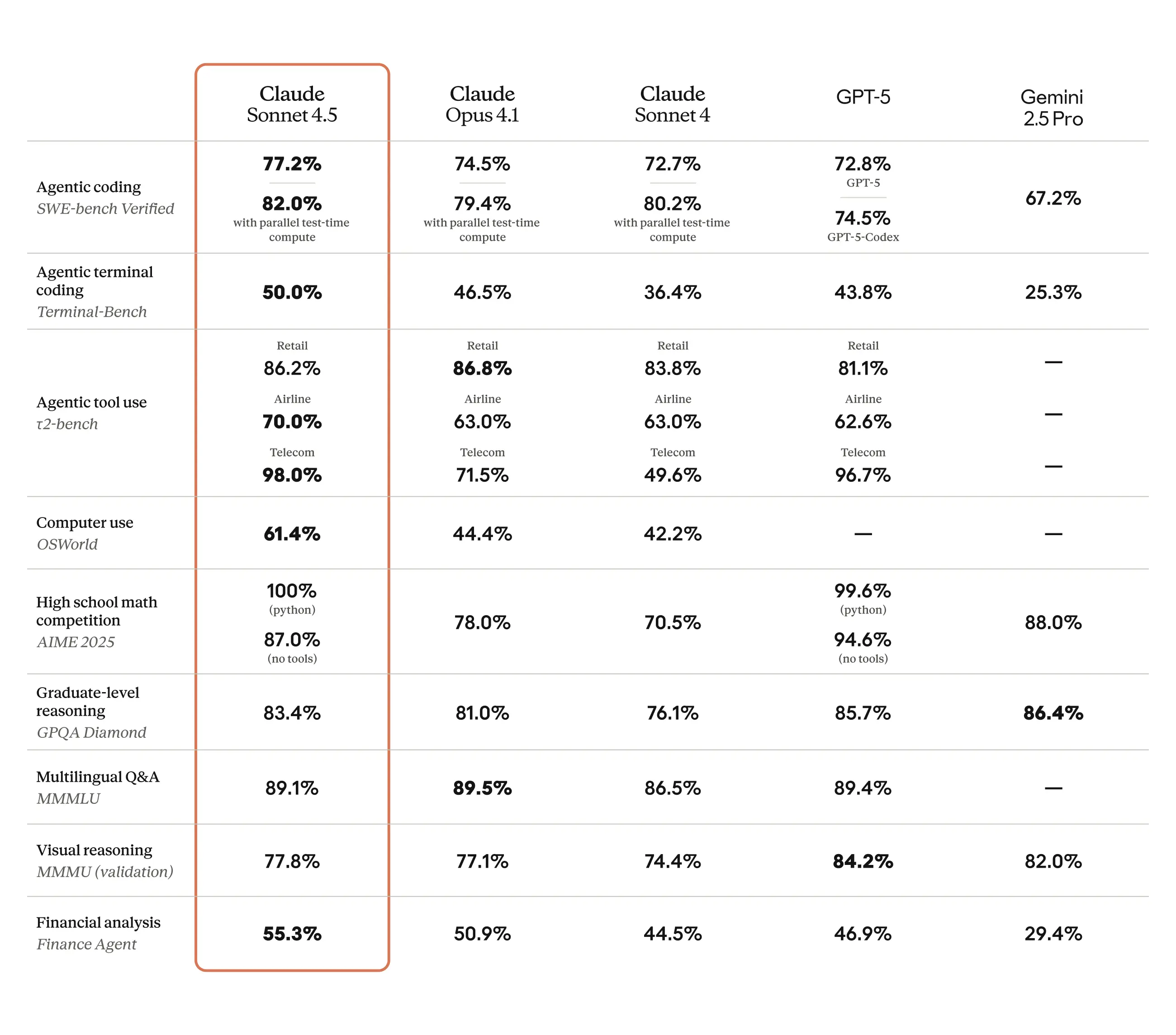
Performance Benchmarks: Visualizing Claude 4.5 Sonnet's capabilities.
✨ Key Features
- 💻 Best Coding Model to Date: Achieving 77.2% accuracy on SWE-bench Verified, Sonnet 4.5 sets a new standard in coding benchmarks. It excels across the entire software development lifecycle, from initial planning and system design to intricate debugging.
- 🕑 Extended Autonomous Operation: Capable of working independently for over 30 hours on complex, multi-step tasks. It maintains clarity and provides incremental progress updates, ensuring reliability for long-running, critical workflows.
- 🧠 Hybrid Reasoning Architecture: Integrates a powerful extended thinking mode to boost performance on complex coding and reasoning challenges, complemented by a standard fast reasoning mode for efficiency.
- 🔒 Improved Safety & Security: Incorporates robust security engineering and advanced vulnerability detection. This significantly reduces risks in sensitive coding and critical financial applications.
- 📚 Broad Domain Knowledge: Demonstrates substantial improvements in domain-specific reasoning across finance, cybersecurity, medicine, and STEM fields, enabling sophisticated real-world applications.
💲 Claude 4.5 Sonnet API Pricing
| Pricing Metric | Cost per Million Tokens |
|---|---|
| Base Input Tokens | $3.15 |
| 5m Cache Writes | $3.9375 |
| 1h Cache Writes | $6.30 |
| Cache Hits & Refreshes | $0.315 |
| Output Tokens | $15.75 |
🎯 Key Use Cases
- 💻 Programming Assistance: Aiding in writing, debugging, and reviewing complex, multi-step code over extended sessions.
- 🧠 Autonomous Agents: Managing sophisticated workflows that coordinate multiple software tools and diverse data sources.
- 💰 Financial Analysis Agents: Expertly parsing and analyzing large datasets with specialized domain knowledge.
- 🔒 Cybersecurity Automation: Enhancing vulnerability detection and automating threat response scripting.
- 🔍 Research Assistance: Facilitating multi-agent coordination for advanced data synthesis and summarization tasks.
💻 Code Sample
Below is an example of how to interact with the Claude 4.5 Sonnet API:
import anthropic client = anthropic.Anthropic( # defaults to os.environ.get("ANTHROPIC_API_KEY") api_key="my_api_key", ) message = client.messages.create( model="claude-sonnet-4.5", max_tokens=1024, messages=[ {"role": "user", "content": "Explain the benefits of quantum computing in simple terms."} ] ) print(message.content) 🆚 Comparison to Other Models
Claude Sonnet 4.5 vs. GPT-5
Claude Sonnet 4.5 is widely recognized as the superior coding model in practical applications, frequently surpassing GPT-5 Codex in live coding tests and benchmarks. While GPT-5 may hold a slight edge in some high-level abstract reasoning tasks, Sonnet 4.5 excels in complex, multi-step coding, balancing speed with remarkable accuracy. Although priced higher, Sonnet 4.5 offers strong reliability and enhanced safety features.
Claude Sonnet 4.5 vs. Qwen3-Next-80B
Sonnet 4.5 outperforms Qwen3-Next-80B in real-world coding and autonomous agent benchmarks, offering superior accuracy and deeper reasoning capabilities. While Qwen3 is optimized for throughput efficiency, it lacks Sonnet 4.5's advanced multi-agent support and specialized domain expertise. Furthermore, Sonnet 4.5 provides superior safety protocols and a larger context window.
Claude Sonnet 4.5 vs. Gemini 2.5 Pro
Claude Sonnet 4.5 significantly surpasses Gemini 2.5 Pro in coding benchmarks, achieving an impressive 77.2% accuracy on SWE-bench compared to Gemini's 63.8%. It also supports longer autonomous operation (over 30 hours) and offers superior multitasking in agentic scenarios, making it the preferred choice for complex software engineering and advanced AI agent workflows.
Claude Sonnet 4.5 vs. Opus 4.1
Sonnet 4.5 marks substantial advancements over Anthropic's previous Opus 4.1, demonstrating nearly a 20% increase in real-world AI computer use tasks and improved coding precision. The newer model integrates advanced multi-agent tool usage and provides extended context windows, enhancing both accuracy and sustained task execution.

A comparative view of Claude 4.5 Sonnet against other leading AI models.
🔗 API Integration
Claude 4.5 Sonnet is readily accessible via AI/ML API. Comprehensive documentation is available here, guiding you through seamless integration into your existing systems.
❓ Frequently Asked Questions (FAQs)
What makes Claude 4.5 Sonnet ideal for complex software development?
Claude 4.5 Sonnet is engineered with a hybrid reasoning architecture and advanced long-term context management, enabling it to excel in multi-step coding, system design, and debugging. Its SWE-bench verified accuracy of 77.2% highlights its superior performance across the entire software development lifecycle, making it the top choice for intricate projects.
How does Claude 4.5 Sonnet ensure long-term task consistency and focus?
The model features exceptional long-term state tracking through an advanced context window and external file state awareness. This allows it to maintain focus and coherency over sessions spanning hours or even days, crucial for complex projects requiring sustained attention and incremental progress updates.
What are the key differences between Claude 4.5 Sonnet and other leading AI models like GPT-5 or Gemini 2.5 Pro?
Claude 4.5 Sonnet generally outperforms models like GPT-5 and Gemini 2.5 Pro in practical coding benchmarks and autonomous agent tasks. For instance, it achieves 77.2% accuracy on SWE-bench compared to Gemini's 63.8%, and offers superior long-term autonomous operation (30+ hours) and multi-agent coordination capabilities. It emphasizes reliability and safety, making it a robust choice for enterprise-level applications.
Can Claude 4.5 Sonnet be used for high-stakes applications such as finance and cybersecurity?
Absolutely. Claude 4.5 Sonnet is designed for demanding real-world environments, integrating robust security engineering, vulnerability detection, and significant improvements in domain-specific reasoning across finance and cybersecurity. Its enhanced accuracy, reliability, and safety features make it highly suitable for sensitive applications requiring stringent performance and ethical standards.
What is "Extended Thinking Mode" and how does it benefit problem-solving?
Extended Thinking Mode is a unique feature of Claude 4.5 Sonnet that enables deeper cognitive processing for complex reasoning, multi-step coding, and agentic workflows. By allocating more computational resources for introspection and deeper thought, it significantly boosts performance on challenging tasks, ensuring more accurate and nuanced problem-solving, albeit with a minor impact on latency.
AI Playground

