 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banane
Google - Gemini, Nano Banane Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance – Das Beste von ByteDance
ByteDance – Das Beste von ByteDance Alle Modelle
Alle Modelle Unternehmenspläne
Unternehmenspläne KI-Anwendungsentwicklung
KI-Anwendungsentwicklung KI-Übersetzer-API
KI-Übersetzer-API KI-SEO/GEO-Dienst
KI-SEO/GEO-Dienst Geooptimierter PR-Service
Geooptimierter PR-Service Web-Scraping-Dienst
Web-Scraping-Dienst OpenClaw
OpenClaw Die besten KI-Tools
Die besten KI-Tools Top-KI-Roboter
Top-KI-Roboter
 Einloggen
Einloggen













AI-API-Vergleich 2026: OpenAI vs. Anthropic Claude vs. Google Gemini vs. Grok

KI-API-Vergleich 2026:
OpenAI gegen Claude
vs Gemini vs Grok
Im März 2026 war der Markt für KI-APIs noch nie so wettbewerbsintensiv – und gleichzeitig so unübersichtlich. Grok 4.1 – Preisrekorde brechen im Nu, Gemini 3.1 Pro dominiert das Denken im Langzeitkontext, Und Claude Opus 4.6 führt in die Bereiche Codierung und Schreiben ein.Die Wahl der richtigen LLM-API kann über den Erfolg oder Misserfolg Ihres Projektbudgets entscheiden. Dieser Leitfaden bietet einen Überblick über Preise, Benchmarks, Stärken und Integrationscode für alle vier führenden Anbieter.
%252520Top%252520Large%252520Language%252520Models_%252520A%252520Comparative%252520Analysis.png)
// Moderner Vergleich von Preisen und Funktionen der LLM-API – visuelle Übersicht der Kostenstrukturen der wichtigsten Anbieter (2026)
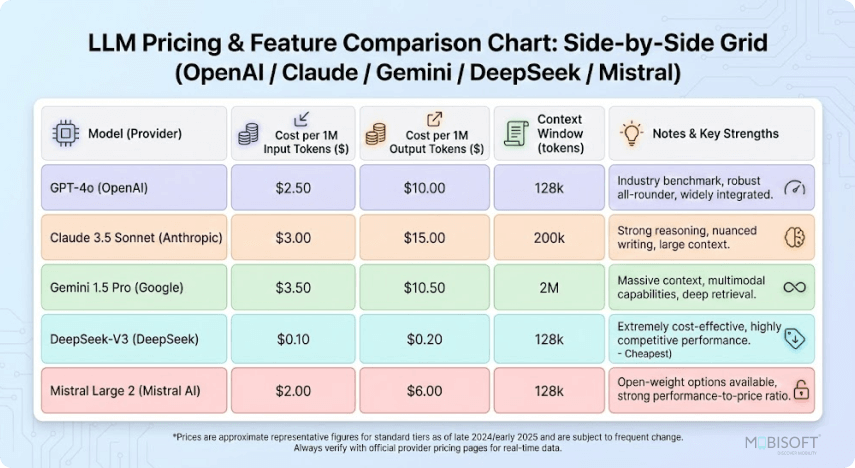
Preisgestaltung der KI-API 2026 (pro 1 Million Token)
Die Preise haben sich zwar deutlich angeglichen, aber es bestehen weiterhin große Unterschiede – insbesondere bei großen Projekten. Neueste Daten, März 2026:
| Anbieter | Modell | Eingabe ($/1M) | Output ($/1M) | Kontextfenster | Am besten geeignet für | Zwischengespeicherter Rabatt |
|---|---|---|---|---|---|---|
| OpenAI | GPT-5.4 (Flaggschiff) | 2,50 € | 15,00 € | Mehr als 400.000 | Ausgewogenes Unternehmen | Bis zu 90 % |
| OpenAI | GPT-5.4-mini | 0,75 $ | 4,50 € | 400.000 | Codierung & Agenten | Bis zu 90 % |
| Anthropisch | Claude Opus 4.6 | 5,00 € | 25,00 € | 200.000 (1 Mio. Beta) | Tiefgründiges Denken und Schreiben | Starkes Caching |
| Anthropisch | Claude Sonett 4.6 | 3,00 € | 15,00 € | 200.000 (1 Mio. Beta) | Beliebtester Sweetspot | Starkes Caching |
| Gemini 3.1 Pro | 2,00 € | 12,00 € | 2 Millionen | Multimodal und langer Kontext | Exzellent | |
| Gemini 3 Blitz | 0,50 € | 3,00 € | Über 1 Million | Hohe Durchsatzgeschwindigkeit | Exzellent | |
| xAI Grok | Grok 4.1 Fast | 0,20 € | 0,50 € | 2 Millionen | Kostensensibel & Codierung | Wettbewerbsfähig |
| xAI Grok | Grok 4 | 3,00 € | 15,00 € | 256K–2M | Echtzeit & unzensiert | Wettbewerbsfähig |
Wichtigste Erkenntnis: Grok 4.1 Fast ist 2026 die unbestritten günstigste High-Context-Lösung. Claude Opus 4.6 bleibt im Premiumsegment angesiedelt, bietet aber eine unübertroffene Bildtiefe. Gemini bietet das beste Preis-Leistungs-Verhältnis für multimodale Anwendungen.

// Gemini vs GPT vs Claude vs Grok — Vergleich der Leistungsfähigkeit von KI-Modellen (2026)
Leistungsbenchmarks – März 2026
Kein einzelnes Modell ist in allen Belangen überlegen. Hier ist ihr Abschneiden in führenden unabhängigen Vergleichstests:
| Benchmark | Gemini 3.1 Pro | Claude Opus 4.6 | GPT-5.4 | Grok 4.1 Fast | Gewinner |
|---|---|---|---|---|---|
| GPQA Diamond (Doktorandenniveau) | 94,3 % | 91,3 % | 92,8 % | ~88% | Zwillinge |
| ARC-AGI-2 (neuartiges Schließen) | 77,1 % | 68,8 % | ~70% | ~16% | Zwillinge |
| SWE-Bench (Programmierung) | 80,6 % | 80,8 % | 74,9 % | ~75% | Claude |
| LiveCodeBench (Programmierung) | Stark | Führer | Stark | Stark | Claude |
| Multimodal (Bild/Video) | Einheimischer Anführer | Gut | Stark | Text zuerst | Zwillinge |
| Echtzeit / Unzensiert | Gut | Konservativ | Gut | Führer | Grok |
& Schreiben
massiver Kontext
Produktion
Codierung/Agenten
Vorteile, Nachteile und beste Anwendungsfälle


Integrationscodebeispiele — Python 2026
Minimale, produktionsreife Beispiele unter Verwendung offizieller SDKs. Alle können in weniger als 5 Minuten auf einer einheitlichen Plattform ausgetauscht werden.
from openai import OpenAI client = OpenAI(api_key="your-openai-key") response = client.chat.completions.create( model="gpt-5.4", messages=[{"role": "user", "content": "Erkläre Quantencomputing in einem Absatz"}], temperature=0.7 ) print(response.choices[0].message.content) 
// KI-Codierungs-Dashboard zur Darstellung des LLM-gestützten Entwicklungs-Workflows
from anthropic import Anthropic client = Anthropic(api_key="your-anthropic-key") response = client.messages.create( model="claude-4.6-sonnet", max_tokens=1024, messages=[{"role": "user", "content": "Write a professional email..."}] ) print(response.content[0].text) import google.generativeai as genai genai.configure(api_key="your-gemini-key") model = genai.GenerativeModel("gemini-3.1-pro") response = model.generate_content("Analyze this image and summarize trends", stream=False) print(response.text) from xai import Grok # Offizielles SDK client = Grok(api_key="your-grok-key") response = client.chat.completions.create( model="grok-4.1-fast", messages=[{"role": "user", "content": "Neueste X-Trends bei KI-Agenten"}], temperature=0.8 ) print(response.choices[0].message.content) Als Tipp: Verwenden Sie LangChain oder LlamaIndex, um diese vollständig zu abstrahieren – und wechseln Sie dann mit einer einzigen Codezeile zwischen den Modellen.
Tipps zur Kostenoptimierung für 2026
- Verwenden Caching — alle vier Anbieter unterstützen es mittlerweile intensiv, mit Einsparungen von bis zu 90 % bei wiederholter Kontextualisierung.
- Einfache Aufgaben an günstigere Modelle weiterleiten: Grok 4.1 Fast oder Gemini Blitz für Anfragen mit hohem Volumen.
- Verwenden Batch-API Wo verfügbar – Einsparungen von über 50 % bei nicht-Echtzeit-Workloads.
- Die Tokennutzung in Echtzeit überwachen – kleine, zeitnahe technische Änderungen können die Kosten um 30–70 % senken.

// Felix – Multi-Backend-KI-Entwicklungs-Dashboard zur Überwachung von Ausgaben und Routing bei LLM-Anbietern
Hört auf, mit APIs zu jonglieren.
Bauen Sie schneller.
Die Verwaltung von vier verschiedenen SDKs, Schlüsseln, Ratenbegrenzungen und Abrechnungs-Dashboards ist mühsam. Intelligente Teams konsolidieren ihre Daten auf einer einzigen Plattform mit einem Schlüssel, einem Dashboard und direktem Zugriff auf alle wichtigen Modelle.