 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banane
Google - Gemini, Nano Banane Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance – Das Beste von ByteDance
ByteDance – Das Beste von ByteDance Alle Modelle
Alle Modelle Unternehmenspläne
Unternehmenspläne KI-Anwendungsentwicklung
KI-Anwendungsentwicklung KI-Übersetzer-API
KI-Übersetzer-API KI-SEO/GEO-Dienst
KI-SEO/GEO-Dienst Geooptimierter PR-Service
Geooptimierter PR-Service Web-Scraping-Dienst
Web-Scraping-Dienst OpenClaw
OpenClaw Die besten KI-Tools
Die besten KI-Tools Top-KI-Roboter
Top-KI-Roboter
 Einloggen
Einloggen



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'deepseek/deepseek-non-reasoner-v3.1-terminus',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="deepseek/deepseek-non-reasoner-v3.1-terminus",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Produktdetails
✨ DeepSeek V3.1 Terminus (Nicht-logisches Denken): Hochgeschwindigkeits-KI mit hoher Effizienz für direkte Aufgaben
Der DeepSeek V3.1 Terminus Modell, insbesondere in seinem Nicht-logisches DenkenDeepSeek ist ein hochentwickeltes, umfangreiches Sprachmodell, das speziell für die schnelle, effiziente und ressourcenschonende Generierung von Inhalten entwickelt wurde. Es eignet sich besonders für Anwendungen, bei denen keine tiefgreifenden analytischen Schlussfolgerungen erforderlich sind, und ist daher ideal für die einfache Inhaltsgenerierung. Als Teil der DeepSeek V3.1-Serie bietet es deutliche Verbesserungen in puncto Stabilität, mehrsprachiger Konsistenz und Zuverlässigkeit der Tools und ist somit die optimale Wahl für Agenten-Workflows, die Geschwindigkeit und geringen Ressourcenverbrauch erfordern.
⚙️ Technische Spezifikationen
- • Modellfamilie: DeepSeek V3.1 Terminus (Nicht-logisches Denken)
- • Parameter: Insgesamt 671 Milliarden, 37 Milliarden aktive in der Schlussfolgerung
- • Architektur: Hybrides LLM mit dualer Inferenz (denkend & nicht-denkend)
- • Kontextfenster: Unterstützt bis zu 128.000 Token Langzeitkontexttraining
- • Präzision und Effizienz: Nutzt FP8-Mikroskalierung für Speicher- und Inferenzeffizienz
- • Modi: Der Modus ohne logisches Denken deaktiviert komplexe Gedankengänge für schnellere Reaktionen
- • Sprachunterstützung: Verbesserte mehrsprachige Konsistenz, insbesondere in Englisch und Chinesisch
📊 Leistungsbenchmarks
- • Logisches Denken (MMLU-Pro): 85,0 (leichte Verbesserung)
- • Agentische Webnavigation (BrowseComp): 38,5 (deutliche Verbesserungen bei der Nutzung mehrstufiger Werkzeuge)
- • Befehlszeile (Terminal-bench): 36,7 (Verbesserte Befehlssequenzverarbeitung)
- • Codegenerierung (LiveCodeBench): 74,9 (Hohe Leistungsfähigkeit erhalten)
- • Software Engineering Verification (SWE Verified): 68,4 (verbesserte Validierungsgenauigkeit)
- • QA-Genauigkeit (SimpleQA): 96,8 (robuste Leistung)
- • Gesamtstabilität: Reduzierte Varianz und deterministischere Ergebnisse für eine höhere Zuverlässigkeit in der Praxis.
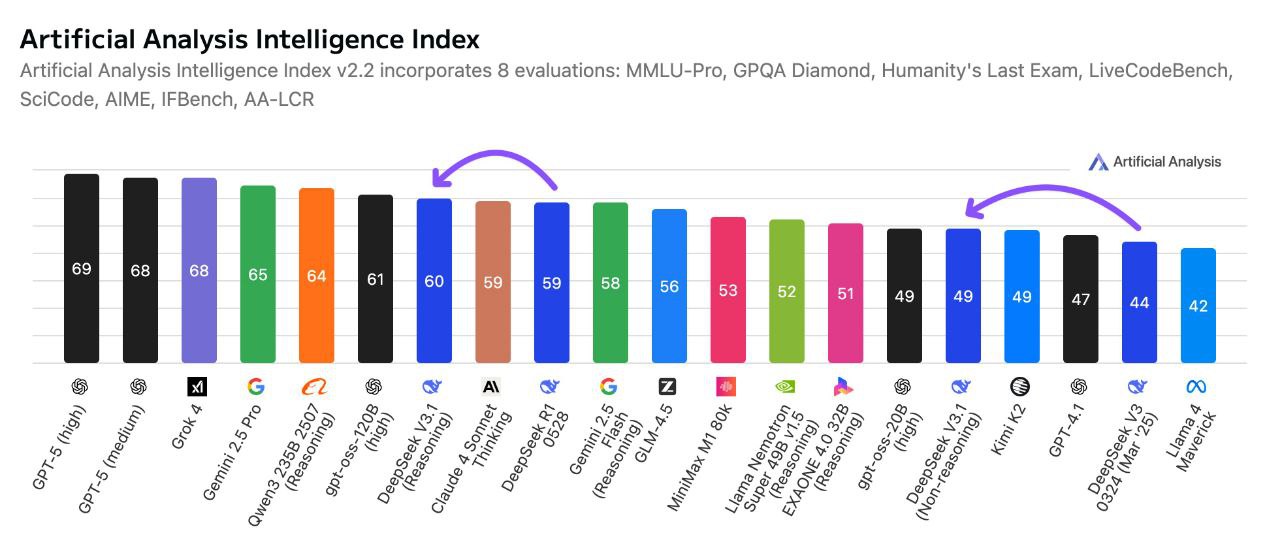
Leistungsvergleich: DeepSeek V3.1 Terminus im Einsatz
⭐ Hauptmerkmale
- 🚀 Schnelle und leichte Generation: Der priorisierte Nicht-Denkmodus gewährleistet reduzierte Verarbeitungszeit und Ressourcenverbrauch, ideal für schnelle Ergebnisse.
- 🌐 Robuste mehrsprachige Ausgabe: Verbesserungen verhindern Sprachvermischung und inkonsistente Token und unterstützen globale AnwendungenDie
- 🛠️ Verbesserte Werkzeugnutzung: Stärkt die Zuverlässigkeit von Werkzeugaufruf-Workflows, einschließlich Codeausführung und Web-SuchkettenDie
- 📖 Flexibler Langzeitkontext: Unterstützt massive Kontexte bis zu 128.000 Token für umfangreiche Eingabehistorien.
- ✅ Stabile und konsistente Ergebnisse: Optimierungen nach dem Training reduzieren Halluzinationen und Tokenisierungsartefakte deutlich.
- 🔄 Rückwärtskompatibel: Lässt sich nahtlos in bestehende DeepSeek-API-Ökosysteme integrieren, ohne dass störende Änderungen erforderlich sind.
- ⚡ Skalierbare hybride Inferenz: Es vereint die Kapazität groß angelegter Modelle mit einer effizienten aktiven Parameterverteilung.
💰 API-Preise
- • 1 Million Input-Tokens: 0,294 $
- • 1 Million Output-Token: 0,441 USD
💡 Praktische Anwendungsfälle
- 💬 Schneller Kundensupport: Schnelle und effiziente Chatbot-Antworten.
- ✍️ Mehrsprachige Inhaltserstellung: Marketingtexte, Zusammenfassungen und mehr in verschiedenen Sprachen.
- 👨💻 Automatisierte Codierungshilfe: Skriptausführung und grundlegende Codegenerierung.
- 📚 Abfragen der Wissensdatenbank: Effiziente Suche und Abfrage in langen Dokumenten.
- ⚙️ Werkzeuggestützte Aufgabenautomatisierung: Optimierte Arbeitsabläufe durch zuverlässige Werkzeugaufrufe.
- 📄 Kurze Dokumentenzusammenfassung: Schnelle Überblicke ohne tiefgehende analytische Erklärungen.
💻 Codebeispiel
🤝 Vergleich mit anderen führenden Modellen
DeepSeek V3.1 Terminus vs. GPT-4: DeepSeek V3.1 Terminus bietet ein deutlich größeres Kontextfenster (bis zu 128.000 TokenIm Vergleich zu den 32.000 Token von GPT-4 ist es für umfangreiche Dokumente und Recherchen deutlich besser geeignet. Es ist optimiert für schnellere Generation im spezialisierten Nicht-Schlussfolgerungsmodus, während GPT-4 detailliertes Schlussfolgern mit höherer Latenz priorisiert.
DeepSeek V3.1 Terminus vs. GPT-5: Während GPT-5 bei multimodalen Aufgaben und der breiteren Integration in ein Ökosystem mit einem noch größeren Kontext hervorragende Leistungen erbringt, legt DeepSeek V3.1 Terminus den Schwerpunkt auf Kosteneffizienz und Lizenzierung mit offenem Gewicht, das sich an Entwickler und Startups mit Fokus auf Infrastrukturkapazitäten richtet.
DeepSeek V3.1 Terminus vs. Claude 4.5: Claude 4.5 legt Wert auf Sicherheit, Ausrichtung und fundierte Argumentation mit robuster, konstitutioneller KI. DeepSeek V3.1 Terminus konzentriert sich auf geringes Gewicht, schnelle LeistungClaude bietet oft höhere Preise pro Aufgabe an, was in regulierten Branchen bevorzugt wird, während DeepSeek Folgendes bietet: offene Lizenzierung und Zugänglichkeit für schnelles Prototyping.
DeepSeek V3.1 Terminus vs. OpenAI GPT-4.5: GPT-4.5 verbessert das logische Denken und das kreative Schreiben, verwendet aber ein ähnliches Kontextfenster von 128.000 Token wie DeepSeek. DeepSeek V3.1 Terminus erreicht Folgendes: schnellere Reaktionszeiten Im Modus ohne logisches Denken eignet es sich ideal für geschwindigkeitskritische Anwendungen ohne komplexe Gedankengänge. GPT-4.5 zeichnet sich durch eine stärkere kreative Generierung und Ökosystemintegration aus, während DeepSeek sich durch Folgendes auszeichnet: Skalierbarkeit und KosteneffizienzDie
❓ Häufig gestellte Fragen (FAQ)
F: Was bedeutet „Nicht-logisches Denken“ für DeepSeek V3.1 Terminus?
A: „Nicht-logisches Denken“ bedeutet, dass dieses Modell für Aufgaben optimiert ist, die keine komplexen logischen Schlussfolgerungen, mehrstufige Problemlösungen oder tiefgreifende analytische Überlegungen erfordern. Es priorisiert die direkte Textgenerierung, einfache Frage-Antwort-Prozesse und eine unkomplizierte Verarbeitung mit maximaler Effizienz und Geschwindigkeit.
F: Was sind die Hauptvorteile der Nicht-Reasoning-Variante?
A: Zu den wichtigsten Vorteilen zählen deutlich schnellere Reaktionszeiten, geringere Rechenkosten, höherer Durchsatz, effiziente Ressourcennutzung und eine optimierte Leistung bei einfachen Aufgaben, bei denen die vollen Schlussfolgerungsfähigkeiten von Standardmodellen nicht erforderlich sind.
F: Welche Kontextfenstergröße hat DeepSeek V3.1 Terminus Non-Reasoning?
A: DeepSeek V3.1 Terminus Non-Reasoning bietet beeindruckende Funktionen 128K Token-KontextfensterDadurch kann es umfangreiche Dokumente verarbeiten und den Kontext bei einfachen Textgenerierungs- und -verarbeitungsaufgaben effektiv beibehalten.
F: Für welche Aufgaben eignet sich dieses Modell am besten?
A: Es eignet sich ideal für einfache Textgenerierung, grundlegende Frage-Antwort-Systeme, Inhaltszusammenfassung, Textklassifizierung, unkomplizierte Übersetzungen, Vorlagenfüllung, Datenextraktion und alle Anwendungen, die eine schnelle und zuverlässige Textverarbeitung ohne komplexe Schlussfolgerungen erfordern.
F: Wie schnell verhält es sich im Vergleich zu Standard-Schlussfolgerungsmodellen?
A: Die nicht-logische Variante reagiert typischerweise 2-4 Mal schneller im Vergleich zu Standard-Schlussfolgerungsmodellen für einfache Aufgaben bieten sie eine deutlich geringere Latenz und einen höheren Durchsatz für Anwendungen zur Verarbeitung großer Textmengen.
KI-Spielplatz

