 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banane
Google - Gemini, Nano Banane Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance – Das Beste von ByteDance
ByteDance – Das Beste von ByteDance Alle Modelle
Alle Modelle Unternehmenspläne
Unternehmenspläne KI-Anwendungsentwicklung
KI-Anwendungsentwicklung KI-Übersetzer-API
KI-Übersetzer-API KI-SEO/GEO-Dienst
KI-SEO/GEO-Dienst Geooptimierter PR-Service
Geooptimierter PR-Service Web-Scraping-Dienst
Web-Scraping-Dienst OpenClaw
OpenClaw Die besten KI-Tools
Die besten KI-Tools Top-KI-Roboter
Top-KI-Roboter
 Einloggen
Einloggen



const axios = require('axios').default;
const api = axios.create({
baseURL: 'https://api.ai.cc/v1',
headers: { Authorization: 'Bearer ' },
});
const main = async () => {
const response = await api.post('/tts', {
model: 'inworld/tts-1',
text: 'OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.',
voice: 'coral',
});
console.log('Audio URL:', response.data.audio.url);
console.log('Characters:', response.data.usage.characters);
};
main();
import requests
def main():
url = "https://api.ai.cc/v1/tts"
headers = {
"Authorization": "Bearer ",
}
payload = {
"model": "inworld/tts-1",
"text": "OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.",
"voice": "coral"
}
response = requests.post(url, headers=headers, json=payload)
data = response.json()
print("Audio URL:", data["audio"]["url"])
print("Characters:", data["usage"]["characters"])
main()


Produktdetails
✨ Inworld TTS-1 API: Fortschrittliche Echtzeit-Sprachsynthese
Der Inworld TTS-1 Das Modell stellt eine hochmoderne, auf Transformer basierende autoregressive Text-to-Speech (TTS)-Lösung dar, die für die Produktion von Hochwertige Echtzeit-Sprachübertragung in mehreren SprachenEs liefert Audio mit außergewöhnlich niedrige Latenz mit einer überlegenen Auflösung von 48 kHz. Darüber hinaus verfügt es über fortschrittliche Funktionen für fein abgestufte emotionale KontrolleDadurch ist es vielseitig einsetzbar, sowohl für gerätebasierte als auch für cloudbasierte Anwendungen.
⚙️ Technische Spezifikationen
- • Architektur: Transformerbasiertes autoregressives Modell
- • Anzahl der Parameter: 1,6 Milliarden (TTS-1)
- • Abtastrate: Hochauflösendes Audio mit bis zu 48 kHz
- • Latenz: Optimiert für geringe LatenzEchtzeitanwendungen
- • Sprachen: Unterstützt 11 Sprachen mit robusten Mehrsprachigkeitsfunktionen
- • Emotionale Kontrolle: Hochentwickelte, feinkörnige Ausdruckskraft
🌟 Hauptmerkmale
- • HiFi-Audio: Bietet 48-kHz-Sprachgenerierung mit Super-Resolution-Techniken für kristallklaren Klang.
- • Nuancierte Emotionskontrolle: Ermöglicht fein abgestufte emotionale und prosodische Anpassungen und damit eine hochgradig nuancierte Sprachausgabe.
- • Gleichbleibende mehrsprachige Qualität: Gewährleistet eine gleichbleibend hohe Sprachqualität in allen 11 unterstützten Sprachen.
- • Effiziente Bereitstellung: Optimierte Architektur für die nahtlose Integration in Cloud- und Edge-Umgebungen (auf dem Gerät).
- • Solides Training: Basierend auf einem umfangreichen Trainingsdatensatz von über 300.000 Stunden englischer und chinesischer Sprachaufnahmen, was die Natürlichkeit und Robustheit erhöht.
🚀 Leistungs- und visuelle Benchmarks
Inworld TTS-1 übertrifft viele Konkurrenzmodelle durchweg, insbesondere in folgenden Bereichen: Mehrsprachige Sprachqualität, emotionale Bandbreite und extrem niedrige Latenzund etablierte sich damit als führender Anbieter für anspruchsvolle Echtzeitanwendungen.
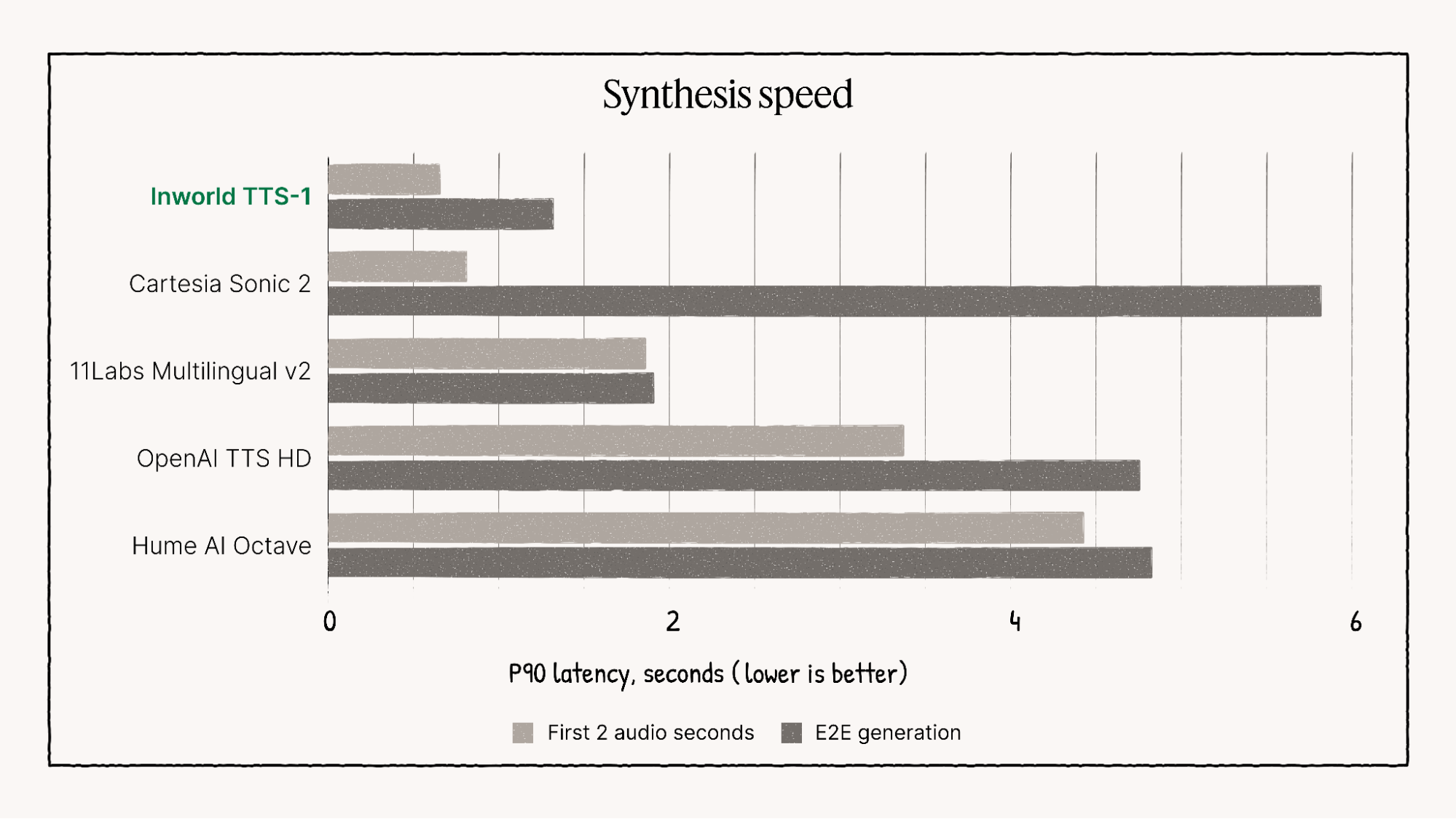
Visuelle Darstellung der Leistungsmerkmale von Inworld TTS-1.
💲 API-Preise
5,25 $ pro 1 Million Zeichen
(etwa 0,00525 USD pro Minute generierter Sprache)
💡 Vielseitige Anwendungsfälle
- • Echtzeit-Sprachassistenten und Konversations-KI: Perfekt für Anwendungen, die eine natürliche Sprachübertragung mit geringer Latenz für eine nahtlose Interaktion erfordern.
- • Multimedia-Inhaltserstellung: Werten Sie Hörbücher, Podcasts und Video-Kommentare mit hochwertigen, mehrsprachigen Voiceovers auf.
- • Interaktive Sprachdialogsysteme (IVR): Durch die Integration emotionaler Nuancen in IVR-Systeme lässt sich die Nutzerbindung deutlich steigern.
- • On-Device-TTS-Anwendungen: Effizienter Einsatz hochwertiger Sprachsynthese auf mobilen und eingebetteten Systemen mit begrenzten Ressourcen.
- • Bildungs- und Barrierefreiheitstools: Hochwertige mehrsprachige Sprachsynthese zur Bereicherung des Lern- und Barrierefreiheitserlebnisses.
🆚 Inworld TTS-1 gegen führende Wettbewerber
im Vergleich zu Google WaveNet: Inworld TTS-1 zeichnet sich durch seine geringere Latenz und überlegene EchtzeitsyntheseDadurch eignet es sich ideal für interaktive Anwendungen. WaveNet bietet eine sehr natürliche und ausdrucksstarke Sprachwiedergabe, erfordert jedoch in der Regel einen höheren Rechenaufwand.
vs. 11LABS Multilingual V2: Inworld TTS-1 bietet feinere emotionale Nuancen und noch geringere Latenz Für Live-Interaktionsszenarien. Während 11LABS starke Mehrsprachigkeitsfunktionen mit einer einfacheren Benutzeroberfläche bietet, ist Inworld TTS-1 die bevorzugte Wahl für hochwertige, ausdrucksstarke Ausgaben.
vs. OpenAI TTS-1-HD: OpenAI TTS-1-HD liefert ultrahochauflösenden, studioqualitativen Klang mit außergewöhnlicher Klangtreue und übertrifft Inworld in puncto Klangfülle oft. Dies geht jedoch auf Kosten von höhere Latenz und KostenInworld TTS-1 bietet eine kostengünstigere und vielseitigere Lösung für mehrsprachige und geräteflexible Implementierungen und eignet sich perfekt für den täglichen Echtzeitbedarf.
💻 Codebeispiel & Dokumentation
Ausführliche Informationen zur API-Nutzung und -Integration finden Sie in der offiziellen Dokumentation:
Inworld TTS-1 API-Dokumentation (Externer Link)
❓ Häufig gestellte Fragen (FAQ)
Inworld TTS-1 ist ein hochmodernes, Transformer-basiertes autoregressives Text-to-Speech-Modell, das für hochwertige Echtzeit-Sprachsynthese entwickelt wurde. Es bietet latenzarmes Audio mit 48 kHz, unterstützt eine differenzierte Emotionssteuerung und ist für mehrsprachige Anwendungen in Cloud- und On-Device-Umgebungen optimiert.
Zu den wichtigsten Spezifikationen gehören eine Architektur mit 1,6 Milliarden Parametern, hochauflösendes Audio mit bis zu 48 kHz und Unterstützung für 11 Sprachen. Zu den Kernfunktionen zählen die originalgetreue Sprachgenerierung, die differenzierte Steuerung von Emotionen und Prosodie, die effiziente Bereitstellung in der Cloud/am Edge sowie die Robustheit dank eines Trainingsdatensatzes von über 300.000 Stunden.
Inworld TTS-1 zeichnet sich durch geringere Latenz und überlegene Echtzeitfähigkeiten im Vergleich zu Google WaveNet, feinere emotionale Nuancen und geringere Latenz bei Live-Interaktionen gegenüber 11LABS Multilingual V2 sowie eine bessere Kosteneffizienz und Geräteflexibilität im Vergleich zu OpenAI TTS-1-HD aus, das Ultra-High-Definition bei höheren Kosten und Latenz priorisiert.
Zu den Hauptanwendungsfällen gehören Echtzeit-Sprachassistenten, die Erstellung von Multimedia-Inhalten, emotional intelligente IVR-Systeme, geräteinterne Text-to-Speech-Funktionen (TTS) und mehrsprachige Bildungs- und Barrierefreiheitstools. Die API kostet 5,25 US-Dollar pro 1 Million Zeichen, was etwa 0,00525 US-Dollar pro Sprachminute entspricht.
KI-Spielplatz

