 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Busca profunda
Busca profunda Alibaba - Qwen
Alibaba - Qwen ByteDance - O Melhor da ByteDance
ByteDance - O Melhor da ByteDance Todos os modelos
Todos os modelos Planos Empresariais
Planos Empresariais Desenvolvimento de aplicações de IA
Desenvolvimento de aplicações de IA API de tradução de IA
API de tradução de IA Serviço de SEO/GEO com IA
Serviço de SEO/GEO com IA Serviço de Relações Públicas Otimizado por Geolocalização
Serviço de Relações Públicas Otimizado por Geolocalização Serviço de Web Scraping
Serviço de Web Scraping OpenClaw
OpenClaw Principais ferramentas de IA
Principais ferramentas de IA Os melhores robôs de IA
Os melhores robôs de IA
 Conecte-se
Conecte-se



const axios = require('axios').default;
const api = axios.create({
baseURL: 'https://api.ai.cc/v1',
headers: { Authorization: 'Bearer ' },
});
const main = async () => {
const response = await api.post('/tts', {
model: 'inworld/tts-1',
text: 'OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.',
voice: 'coral',
});
console.log('Audio URL:', response.data.audio.url);
console.log('Characters:', response.data.usage.characters);
};
main();
import requests
def main():
url = "https://api.ai.cc/v1/tts"
headers = {
"Authorization": "Bearer ",
}
payload = {
"model": "inworld/tts-1",
"text": "OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.",
"voice": "coral"
}
response = requests.post(url, headers=headers, json=payload)
data = response.json()
print("Audio URL:", data["audio"]["url"])
print("Characters:", data["usage"]["characters"])
main()


Detalhes do produto
✨ API TTS-1 integrada: Síntese de fala avançada em tempo real
O Inworld TTS-1 O modelo representa uma solução de síntese de voz (TTS) autorregressiva de ponta, baseada em Transformers, projetada para produzir Discurso em tempo real de alta qualidade em vários idiomas.Ele fornece áudio com latência excepcionalmente baixa com uma resolução superior de 48 kHz. Além disso, incorpora recursos avançados para controle emocional minucioso, tornando-o versátil tanto para aplicações em dispositivos móveis quanto para aplicações baseadas na nuvem.
⚙️ Especificações Técnicas
- • Arquitetura: Modelo autorregressivo baseado em transformadores
- • Contagem de parâmetros: 1,6 bilhão (TTS-1)
- • Taxa de amostragem: Áudio de alta resolução de até 48 kHz
- • Latência: Otimizado para baixa latência, aplicações em tempo real
- • Idiomas: Suportes 11 idiomas com recursos multilíngues robustos
- • Controle emocional: Expressividade refinada e avançada
🌟 Principais Características
- • Áudio de alta fidelidade: Oferece geração de voz em 48 kHz com técnicas de super-resolução para áudio cristalino.
- • Controle Emocional Sutis: Permite ajustes emocionais e prosódicos precisos, possibilitando uma produção de fala altamente matizada.
- • Qualidade multilíngue consistente: Garante uma fala consistente e de alta qualidade em todos os 11 idiomas suportados.
- • Implantação eficiente: Arquitetura otimizada para integração perfeita em ambientes de nuvem e de borda (no dispositivo).
- • Treinamento robusto: Construído com base em um vasto conjunto de dados de treinamento com mais de 300.000 horas de fala em inglês e chinês, aprimorando a naturalidade e a robustez.
🚀 Indicadores de desempenho e visuais
O Inworld TTS-1 supera consistentemente muitos modelos concorrentes, particularmente nas áreas de Qualidade de fala multilíngue, amplitude emocional e latência ultrabaixa., consolidando-a como líder em aplicações exigentes em tempo real.
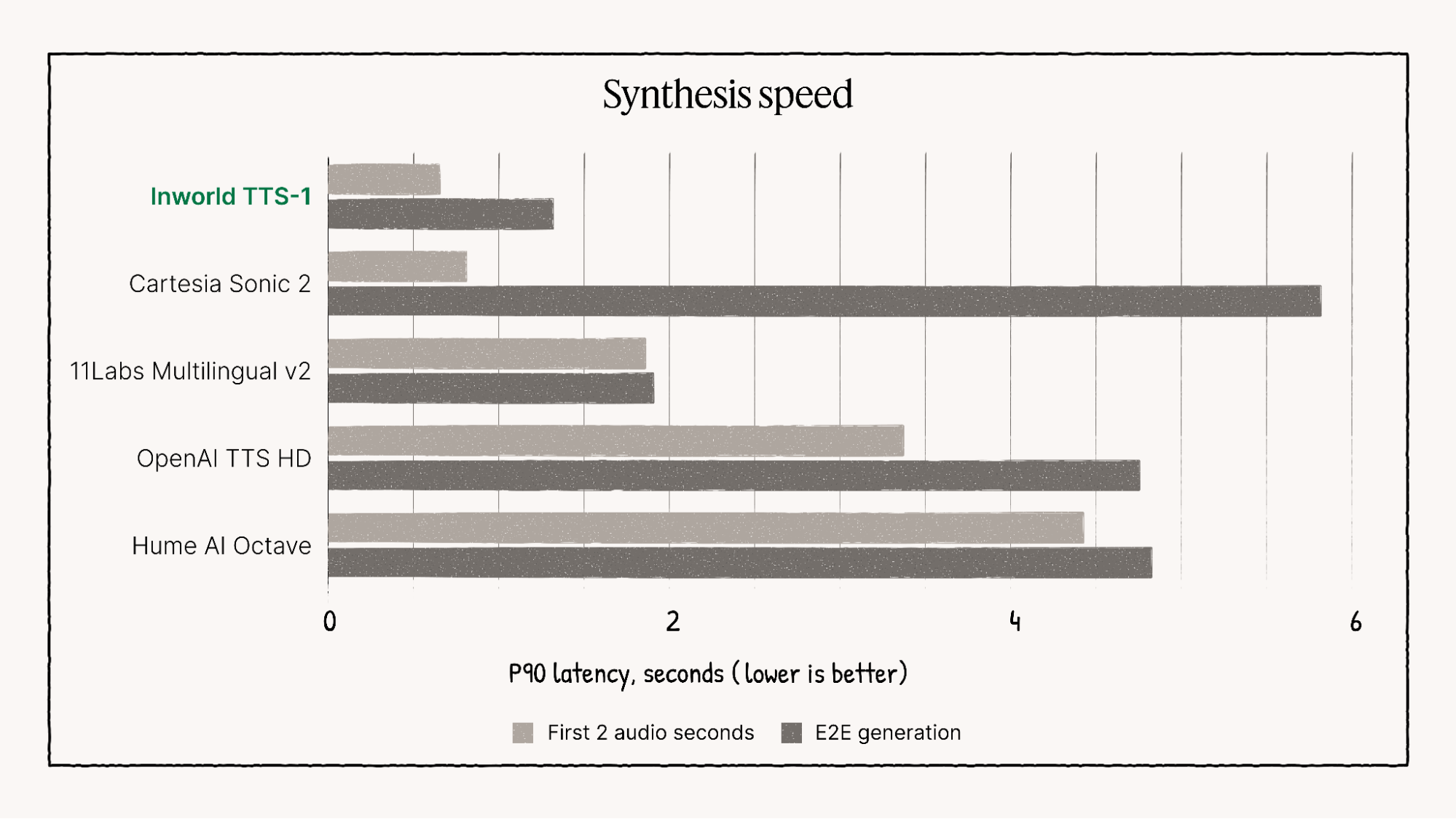
Representação visual das características de desempenho do Inworld TTS-1.
💲 Preços da API
$ 5,25 por 1 milhão de caracteres
(aproximadamente $ 0,00525 por minuto de fala gerada)
💡 Casos de uso versáteis
- • Assistentes de voz em tempo real e IA conversacional: Ideal para aplicações que exigem fala natural e de baixa latência para uma interação perfeita.
- • Criação de conteúdo multimídia: Aprimore audiolivros, podcasts e narrações de vídeo com locuções multilíngues de alta qualidade.
- • Sistemas de Resposta de Voz Interativa (IVR): Incorpore nuances emocionais aos sistemas de URA (Unidade de Resposta Audível) para aumentar significativamente o engajamento do usuário.
- • Aplicações de TTS (sincronização de fala) no dispositivo: Implante de forma eficiente a síntese de voz de alta qualidade em sistemas móveis e embarcados com recursos limitados.
- • Ferramentas educacionais e de acessibilidade: Fornecer síntese de voz multilíngue de alta qualidade para enriquecer as experiências de aprendizagem e acessibilidade.
🆚 Inworld TTS-1 vs. Principais concorrentes
vs. Google WaveNet: O Inworld TTS-1 se destaca com seu menor latência e síntese em tempo real superiorO WaveNet é ideal para aplicações interativas. Ele oferece fala altamente natural e expressiva, mas geralmente a um custo computacional mais elevado.
vs. 11LABS Multilingual V2: O Inworld TTS-1 fornece nuances emocionais mais sutis e latência ainda menor. Para cenários de interação ao vivo, o Inworld TTS-1 é a opção preferida para uma saída expressiva e de alta qualidade, embora o 11LABS ofereça recursos multilíngues robustos com uma interface mais simples.
vs. OpenAI TTS-1-HD: O OpenAI TTS-1-HD oferece áudio de ultra-alta definição com qualidade de estúdio e fidelidade excepcional, muitas vezes superando o Inworld em riqueza sonora. No entanto, isso ocorre à custa de maior latência e custoO Inworld TTS-1 oferece uma solução mais econômica e versátil para implantações multilíngues e flexíveis em relação a dispositivos, perfeitamente adequada para as necessidades diárias em tempo real.
💻 Exemplo de código e documentação
Para obter informações detalhadas sobre o uso e a integração da API, consulte a documentação oficial:
Documentação da API Inworld TTS-1 (Link externo)
❓ Perguntas frequentes (FAQ)
O Inworld TTS-1 é um modelo de síntese de voz autorregressivo de última geração, baseado em Transformers, projetado para síntese de fala em tempo real de alta qualidade. Ele oferece áudio de baixa latência a 48 kHz, suporta controle emocional preciso e é otimizado para aplicações multilíngues em ambientes de nuvem e dispositivos móveis.
As principais especificações incluem uma arquitetura com 1,6 bilhão de parâmetros, áudio de alta resolução de até 48 kHz e suporte para 11 idiomas. Seus recursos essenciais abrangem geração de fala de alta fidelidade, controle emocional e prosódico preciso, implantação eficiente em nuvem/borda e robustez comprovada por um conjunto de dados de treinamento com mais de 300.000 horas de uso.
O Inworld TTS-1 se destaca pela menor latência e capacidades superiores em tempo real em comparação com o Google WaveNet, nuances emocionais mais refinadas e menor latência para interações ao vivo em relação ao 11LABS Multilingual V2, além de melhor custo-benefício e flexibilidade de dispositivos do que o OpenAI TTS-1-HD, que prioriza a ultra-alta definição a um custo e latência maiores.
Os principais casos de uso incluem assistentes de voz em tempo real, criação de conteúdo multimídia, sistemas IVR com inteligência emocional, síntese de voz integrada (TTS) e ferramentas educacionais/de acessibilidade multilíngues. A API custa US$ 5,25 por 1 milhão de caracteres, o que equivale a aproximadamente US$ 0,00525 por minuto de fala.
Playground de IA

