 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'deepseek/deepseek-v3.2-speciale',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2-speciale",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Product Detail
DeepSeek V3.2 Speciale is an advanced, reasoning-focused large language model (LLM) engineered to excel in multi-step logical problem-solving and extensive context processing. With an impressive context window of up to 128K tokens, it's designed for complex analytical tasks. A groundbreaking feature, the "thinking-only" mode, allows the model to perform silent internal reasoning before generating any output. This innovative approach significantly enhances accuracy, factual coherence, and stepwise deduction, especially for intricate queries.
This model adheres to DeepSeek’s Chat Prefix/FIM completion specifications and offers robust tool calling capabilities. Accessible via a Speciale endpoint for limited durations, it bridges the gap between cutting-edge research and practical AI reasoning applications, ensuring analytical consistency across diverse domains like code generation, mathematical computations, and scientific exploration.
✨ Technical Specifications ✨
- ✅ Architecture: Text-based reasoning LLM
- ✅ Context Length: 128K tokens
- ✅ Capabilities: Chat, advanced reasoning, tool use, FIM completion
- ✅ Training Data: Reasoning-optimized datasets, human feedback alignment
🧠 Performance Benchmarks 🧠
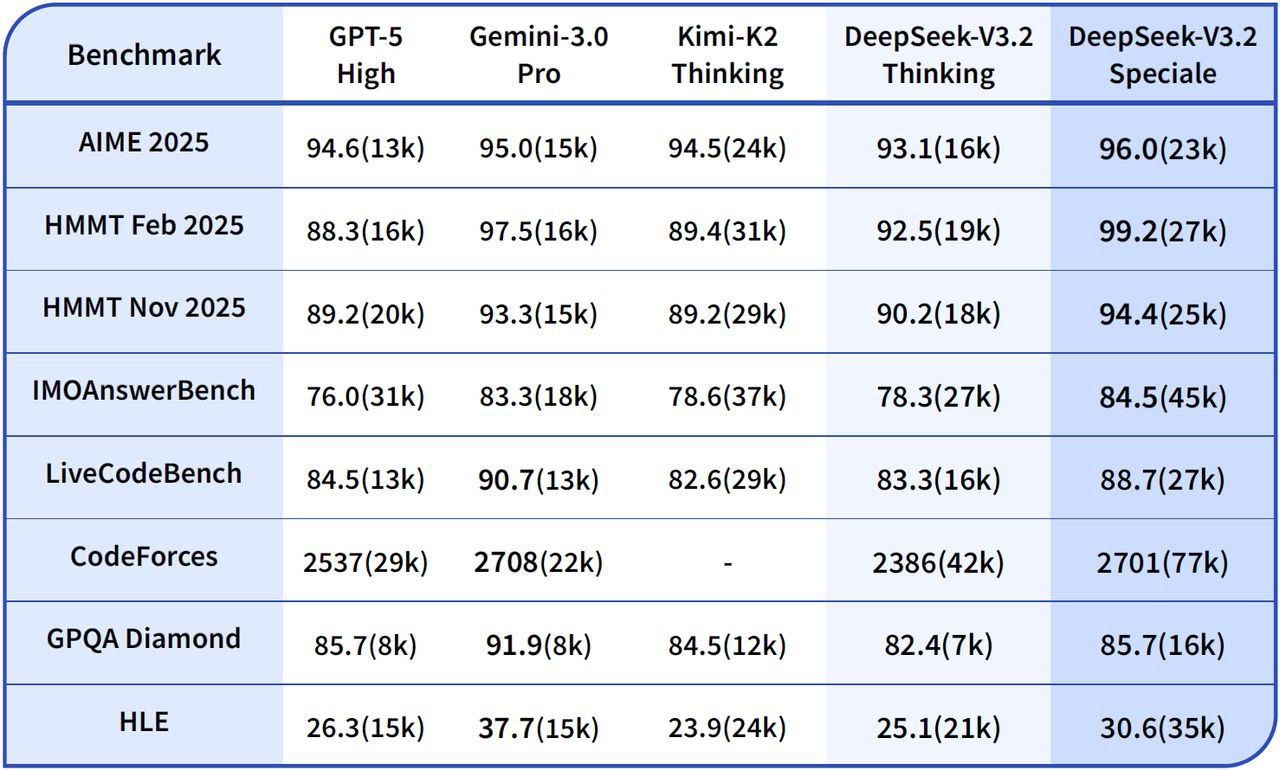
- 📈 Complex Reasoning: Demonstrates improved stability on multi-step chains, including mathematical and symbolic tasks.
- 💻 Code Synthesis / Debugging: Provides better trace explainability, aiding in development and debugging processes.
💡 Output Quality & Reasoning Performance 💡
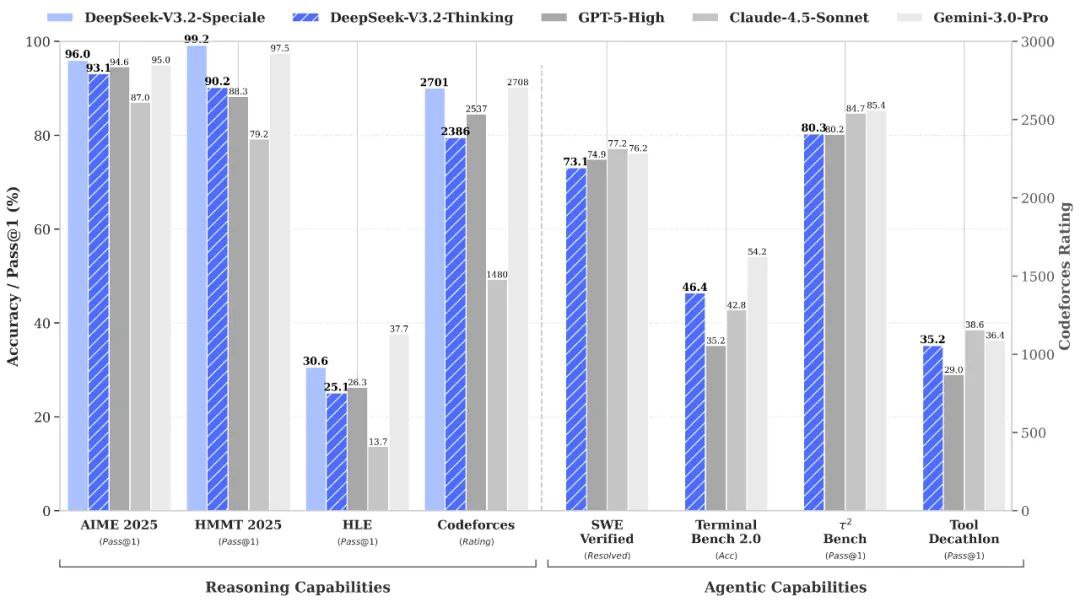
🌟 Quality Improvements
- ✔️ Coherent Reasoning: Consistent reasoning threads maintain coherence over 100K+ tokens.
- ✔️ Enhanced Error Recovery: Improved error recovery during long chains through adaptive attention control.
- ✔️ Superior Symbolic Accuracy: Outperforms earlier DeepSeek models in multi-variable logic and code inference.
- ✔️ Balanced Analytical Tone: Delivers precision explanation while reducing overfits or semantic drift.
⚠️ Limitations
- Formal Tone: May sound overly formal or rigid in casual tasks.
- Increased Latency: "Thinking-only" mode slightly increases latency on highly complex chains.
- Limited Creative Variation: Minimal creative tone variation compared to storytelling-oriented LLMs.
🚀 New Features & Technical Upgrades 🚀
DeepSeek-V3.2-Speciale introduces pioneering reasoning frameworks and internal optimization layers, engineered for superior stability, interpretability, and long-context accuracy.
Key Upgrades
- 🧠 Thinking-Only Mode: Adds a silent cognitive pass before user-visible output, dramatically reducing contradiction rates and hallucinations for more reliable responses.
- 📏 Extended Context Window (128K): Enables comprehensive long-document synthesis, sustained dialogue memory, and data-driven reasoning across multiple sources.
- 🔍 Internal Chain Auditing: Offers enhanced reasoning trace visibility, invaluable for researchers validating multi-step inference and ensuring transparency.
- ✏️ FIM (Fill-in-the-Middle) Completion: Facilitates context-level insertions and structured code patching without the need for full prompt resubmission, boosting efficiency for developers.
Practical Impact
These significant upgrades translate into a higher interpretive depth across mathematics, scientific logic, and long analytical tasks. DeepSeek V3.2 Speciale is therefore ideal for sophisticated automation pipelines and advanced cognitive research experiments.
💰 API Pricing 💰
- Input: $0.2977 per 1M tokens
- Output: $0.4538 per 1M tokens
💻 Code Sample 💻
# Example Python code for DeepSeek V3.2 Speciale API call import openai client = openai.OpenAI( base_url="https://api.deepseek.com/v1", api_key="YOUR_API_KEY" ) response = client.chat.completions.create( model="deepseek/deepseek-v3.2-speciale", messages=[ {"role": "user", "content": "Explain the concept of quantum entanglement in a step-by-step logical manner."}, {"role": "assistant", "content": "(Thinking-only mode activated: Deconstructing query, identifying key concepts, planning logical progression, recalling relevant physics principles, structuring explanation into discrete steps.)"} ], # The 'thinking-only' mode is an internal mechanism. # The API call itself remains standard, but the model's internal processing changes. temperature=0.7, max_tokens=500 ) print(response.choices[0].message.content) 🆚 Comparison with Other Models 🆚
DeepSeek V3.2 Speciale vs. Gemini-3.0-Pro: Benchmarks indicate that DeepSeek-V3.2-Speciale achieves comparable overall proficiency to Gemini-3.0-Pro. However, DeepSeek places a significantly stronger emphasis on transparent, stepwise reasoning, making it particularly advantageous for agentic AI applications.
DeepSeek V3.2 Speciale vs. GPT-5: Reported evaluations position DeepSeek-V3.2-Speciale ahead of GPT-5 on challenging reasoning workloads, especially in math-heavy and competition-style benchmarks. It also maintains high competitiveness in coding and tool-use reliability, offering a compelling alternative for complex tasks.
DeepSeek V3.2 Speciale vs. DeepSeek-R1: Speciale is engineered for even more extreme reasoning scenarios, featuring a 128K context window and a high-compute "thinking mode." This makes it exceptionally well-suited for advanced agentic frameworks and benchmark-grade experiments, distinguishing it from DeepSeek-R1 which is designed for more casual interactive use.
💬 Community Feedback 💬
User feedback on platforms like Reddit consistently highlights DeepSeek V3.2 Speciale as a standout for high-stakes reasoning tasks. Developers particularly praise its benchmark dominance and impressive cost efficiency, noting its superiority over GPT-5 on math, code, and logical benchmarks, often at a 15x lower cost. Many describe it as "remarkable" for agentic workflows and complex problem-solving. Users also commend its impressive coherence in long chains, significantly reduced errors, and "human-like" depth, especially when compared to prior DeepSeek versions.
❓ Frequently Asked Questions (FAQ) ❓
Q1: What is DeepSeek V3.2 Speciale's primary focus?
A1: It primarily focuses on advanced reasoning and multi-step logical problem-solving, designed for complex analytical tasks in code, math, and scientific domains.
Q2: How does the "thinking-only" mode work?
A2: This mode allows the model to perform silent internal reasoning before generating any visible output. This internal cognitive pass significantly improves accuracy, factual coherence, and the logical flow of responses, especially for complex queries.
Q3: What is the maximum context length for DeepSeek V3.2 Speciale?
A3: DeepSeek V3.2 Speciale supports an extended context window of up to 128K tokens, enabling it to handle very long documents, maintain sustained dialogue memory, and perform data-driven reasoning across multiple sources.
Q4: How does its pricing compare to other models?
A4: Community feedback suggests that DeepSeek V3.2 Speciale offers highly competitive pricing, with developers reporting it can be up to 15x lower cost than some competitors like GPT-5 for similar complex tasks.
Q5: Is DeepSeek V3.2 Speciale suitable for creative writing tasks?
A5: While highly capable in analytical reasoning, its "Limitations" include a minimal creative tone variation compared to storytelling-oriented LLMs. It may sound overly formal or rigid for casual or highly creative tasks.
AI Playground

