 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'x-ai/grok-4-1-fast-reasoning',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="x-ai/grok-4-1-fast-reasoning",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Product Detail
Grok 4.1 Fast Reasoning by xAI represents a significant leap in AI model capabilities, specifically engineered for high-speed, multi-step analytical tasks and comprehensive context handling. This advanced model is perfectly suited for complex real-time applications, offering unparalleled efficiency and precision. Its distinguishing features include a unique dual-mode operation, top-tier reasoning scores on benchmarks, and an architecture designed to power both rapid conversational interfaces and intricate agentic workflows.
Technical Specifications: Powering Advanced AI
- 🚀 Architecture: Transformer-based with advanced agentic reasoning capabilities, ensuring robust and intelligent processing.
- 📚 Context Window: An expansive up to 2,000,000 tokens, enabling deep analysis of massive documents and complex discourse.
- ✍️ Output Length: Capable of generating up to 30,000 tokens per output, ideal for detailed responses.
- 🛡️ Hallucination Reduction: Achieves three times fewer hallucinations in information-seeking queries compared to previous iterations, bolstered by enhanced web grounding through search triggers.
Unmatched Performance Benchmarks
Grok 4.1 showcases significant improvements over its predecessor, particularly excelling in emotional intelligence, creative writing, and dramatically reducing hallucinations. It consistently dominates leaderboards, demonstrating substantial advancements in reasoning, creativity, and overall reliability. Rigorously evaluated through blind user preferences and standardized tests, Grok 4.1 consistently outperforms both previous versions and competitive models.
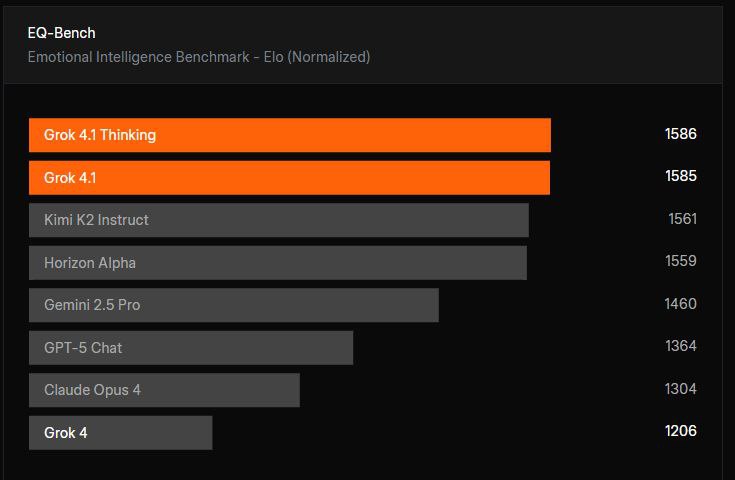
Key Features: What Makes Grok 4.1 Stand Out
- 💖 Enhanced Emotional & Creative Capabilities: More attuned to user intent, providing empathetic, personality-driven replies in role-plays and creative tasks, optimized via reinforcement learning for superior style and alignment.
- ✔️ Factual Accuracy Improvements: Post-training efforts significantly minimize hallucinations, especially in information-seeking scenarios with integrated search tools, ensuring highly reliable outputs.
- 🔒 Robust Safety Layers: Incorporates comprehensive refusal policies for illegal intents, input filters for restricted topics, and advanced mitigations against deception (dishonesty rate around 0.46-0.49%) and sycophancy (0.19-0.23%).
- 🌐 Multilingual & Adversarial Resilience: Extensively evaluated across multiple languages including English, Spanish, and Arabic; specifically trained to withstand prompt injections and various agentic harms, ensuring global applicability and security.
API Pricing: Cost-Effective Performance
- 💲 Input Tokens: $0.21 per 1 Million tokens – Highly competitive for large-scale data processing.
- 💲 Output Tokens: $0.53 per 1 Million tokens – Efficient pricing for generating rich, detailed responses.
Versatile Use Cases for Grok 4.1
- 💡 Creative Content Generation: Effortlessly craft engaging viral posts or compelling short stories, injecting vibrant personality and flair into narratives like Grok's "awakening."
- 💡 Emotional Support Interactions: Provide nuanced empathy for personal queries, such as comforting responses to grief over a lost pet, fostering deeper user connections.
- 💡 Accurate Information Retrieval: Deliver precise travel recommendations (e.g., top San Francisco spots) with minimal errors, utilizing integrated search for the most current insights.
- 💡 Collaborative Roleplay: Enhance team brainstorming sessions or educational simulations through multi-turn interactions driven by advanced emotional intelligence.
- 💡 Sophisticated Agentic Tasks: Tackle complex challenges like cybersecurity analysis or protocol-based problem-solving with reasoned, step-by-step approaches, always within ethical boundaries.
- 💡 Multilingual Assistance: Support a global user base in sensitive discussions, ensuring harmful content is refused across all supported languages.
Code Sample Integration
<snippet data-name="open-ai.chat-completion" data-model="x-ai/grok-4-1-fast-reasoning"></snippet>Grok 4.1 vs. Leading AI Models
Vs. Grok 4: Grok 4.1 achieves a nearly 3x reduction in hallucination rate and an impressive 600-point boost in creative writing scores. It also boasts a larger context window and significantly enhanced emotional intelligence over its predecessor.
Vs. GPT-4: Grok 4.1 offers a far larger context window and a specialized reasoning mode, making it superior for tasks demanding extensive context and transparent thought processes. It also demonstrates stronger emotional intelligence benchmarks.
Vs. Gemini 2.5 Pro: Grok 4.1 differentiates itself with lower hallucination rates and superior fine-tuning for emotionally rich and creative applications, while Gemini 2.5 Pro might retain advantages in specific domain-centric benchmarks.
Vs. Claude 4 Opus: Grok 4.1 achieves higher scores in creativity and emotional engagement. Its instant-mode interaction option provides faster response times compared to Claude's emphasis on safety and controlled outputs.
Frequently Asked Questions (FAQ)
Q: What is the primary advantage of Grok 4.1's "Fast Reasoning" capability?
A: The "Fast Reasoning" capability allows Grok 4.1 to perform low-latency, multi-step reasoning, making it ideal for real-time applications and complex analytical tasks where quick, accurate responses are critical.
Q: How does Grok 4.1 handle large amounts of information?
A: Grok 4.1 is equipped with a massive context window of up to 2,000,000 tokens, enabling it to process and analyze extremely large documents and extensive discourse effectively.
Q: What are the key improvements in Grok 4.1 regarding factual accuracy?
A: Grok 4.1 features three times fewer hallucinations in information-seeking queries compared to previous versions and benefits from enhanced web grounding via search triggers, leading to highly reliable outputs.
Q: Can Grok 4.1 be used for creative writing and emotional interactions?
A: Absolutely. Grok 4.1 excels in emotional intelligence and creative writing, offering empathetic, personality-driven replies and the ability to craft compelling narratives, optimized through reinforcement learning.
Q: Is Grok 4.1 suitable for global users and sensitive topics?
A: Yes, Grok 4.1 is multilingual, evaluated across languages like English, Spanish, and Arabic, and includes robust safety layers with refusal policies for illegal intents and mitigations against deception, ensuring safe and responsible global assistance.
AI Playground

