 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in



const axios = require('axios').default;
const api = axios.create({
baseURL: 'https://api.ai.cc/v1',
headers: { Authorization: 'Bearer ' },
});
const main = async () => {
const response = await api.post('/tts', {
model: 'inworld/tts-1-max',
text: 'OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.',
voice: 'coral',
});
console.log('Audio URL:', response.data.audio.url);
console.log('Characters:', response.data.usage.characters);
};
main();
import requests
def main():
url = "https://api.ai.cc/v1/tts"
headers = {
"Authorization": "Bearer ",
}
payload = {
"model": "inworld/tts-1-max",
"text": "OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.",
"voice": "coral"
}
response = requests.post(url, headers=headers, json=payload)
data = response.json()
print("Audio URL:", data["audio"]["url"])
print("Characters:", data["usage"]["characters"])
main()


Product Detail
Inworld TTS-1-Max: Revolutionizing Text-to-Speech
Discover the Inworld TTS-1-Max API, a state-of-the-art, Transformer-based autoregressive text-to-speech (TTS) model. Engineered to deliver unparalleled speech quality and expressiveness, it stands as the premier choice for professional and commercial applications demanding high-resolution, nuanced voice synthesis.
With an impressive 8.8 billion parameters, TTS-1-Max pushes the boundaries of natural language generation, producing voices that are virtually indistinguishable from human speech.
Technical Specifications & Performance
- ⚙️ Architecture: Advanced Transformer-based autoregressive model
- 🔢 Parameters: A massive 8.8 billion (the largest in the Inworld TTS-1 family)
- 🔊 Audio Output: Crystal-clear, high-resolution 48 kHz speech
- 🌐 Supported Languages: Comprehensive support for 11 major languages
- ⚡ Inference Speed: Achieves approximately 8,000 tokens/sec per GPU on a 32 H100 setup, ensuring efficiency.
Leading the Quality Leaderboards
The TTS-1-Max model consistently ranks as a top performer on independent quality leaderboards, showcasing its superior output and naturalness in various evaluations.
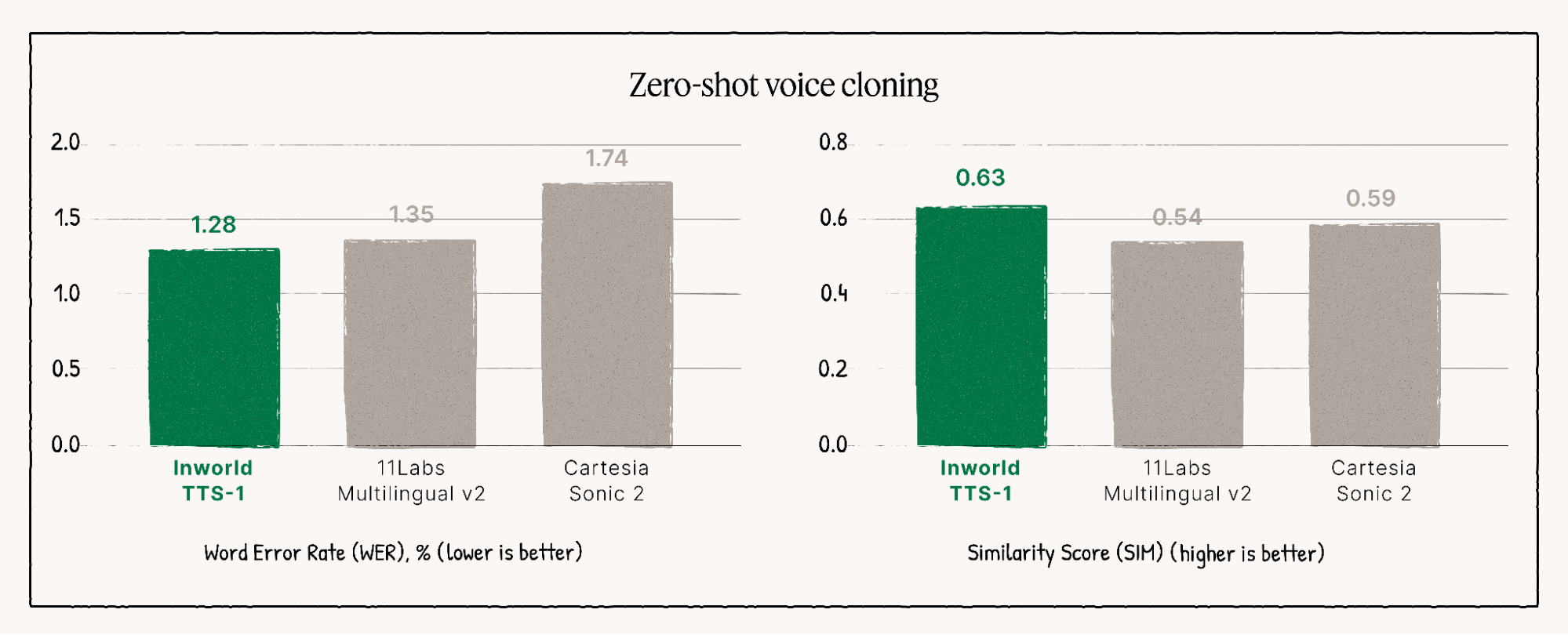
Key Features for Unrivaled Speech Synthesis
- ✨ Superior Naturalness & Expressiveness: Leverages large-scale parameterization for incredibly natural and emotionally rich voice outputs.
- 🗣️ High-Fidelity Multilingual Synthesis: Generate speech with exceptional clarity and accuracy across 11 diverse languages, ideal for global applications.
- 🎭 Advanced Emotional Modulation: Fine-tune speech styles with robust emotional modulation capabilities, adding profound nuance and depth to every utterance.
- 👂 Realistic Non-Verbal Sounds & Vocalizations: Enhances speech realism with seamless support for various non-verbal cues, making AI voices more lifelike.
- 👤 Pure In-Context Voice Cloning: Achieves voice cloning without requiring any pre-recorded speaker data, relying purely on sophisticated in-context learning.
Transparent & Competitive API Pricing
💰 Experience premium speech synthesis with straightforward and transparent pricing:
- Cost: Only $10.5 per 1 Million characters generated.
- Estimated per minute cost: Approximately $0.0105 per minute of high-quality generated speech.
Integrate with Ease: Code Sample
Implementing Inworld TTS-1-Max into your applications is seamless. Below is a representation of the API snippet for quick integration:
<snippet data-docs="https://docs.ai.cc/api-references/speech-models/text-to-speech/inworld/tts-1-max" snippet data-name="voice.tts-openai" data-model="inworld/tts-1-max"></snippet>For comprehensive integration details, advanced parameters, and more code examples, please refer to the official Inworld TTS-1-Max API Documentation.
Inworld TTS-1-Max: Competitive Edge
Understand how Inworld TTS-1-Max distinguishes itself from other leading text-to-speech models in the market, offering specialized advantages for various use cases.
🆚 vs. Inworld TTS-1
TTS-1-Max delivers superior expressiveness and naturalness thanks to its significantly larger 8.8 billion parameter scale (compared to TTS-1's 1.6 billion), making it ideal for premium content like audiobooks. In contrast, TTS-1 prioritizes real-time speed (~153 characters/second vs. TTS-1-Max's ~69 characters/second), making it better suited for highly interactive applications.
🆚 vs. ElevenLabs Multilingual V2
In quality tests, TTS-1-Max achieves a 59.1% head-to-head win rate, offering finer emotional granularity and robust support for non-verbal sounds via markups. While ElevenLabs provides strong multilingual cloning, TTS-1-Max leads in raw audio resolution and the purity of its in-context learning approach.
🆚 vs. MiniMax-Speech
TTS-1-Max prioritizes peak voice quality and fidelity across its 11 supported languages, demonstrating leadership in benchmarked naturalness and emotional prosody control. MiniMax-Speech, conversely, emphasizes broader 32-language zero-shot cloning capabilities and rapid one-shot voice replication.
Frequently Asked Questions (FAQ)
❓ What is Inworld TTS-1-Max?
Inworld TTS-1-Max is a cutting-edge, Transformer-based autoregressive text-to-speech API, featuring 8.8 billion parameters. It's designed for professional and commercial applications demanding superior speech quality and expressiveness.
❓ What are its key technical features?
It offers an autoregressive Transformer architecture, 8.8 billion parameters, 48 kHz high-resolution audio, support for 11 major languages, and an inference speed of approximately 8,000 tokens/sec per GPU.
❓ How does TTS-1-Max achieve high expressiveness?
Its exceptional expressiveness and naturalness stem from its large-scale 8.8 billion parameterization, coupled with emotional modulation capabilities and support for non-verbal sounds, creating highly nuanced speech.
❓ What is the pricing structure for the TTS-1-Max API?
The API is priced at $10.5 per 1 million characters, which translates to an estimated cost of about $0.0105 per minute of generated speech.
❓ What are the ideal use cases for Inworld TTS-1-Max?
It's perfectly suited for professional voice-overs, dubbing, advanced conversational AI, multilingual media content production, interactive voice applications, audiobooks, gaming, and immersive virtual environments where superior voice quality and expressiveness are paramount.
AI Playground

