 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in



const main = async () => {
const response = await fetch('https://api.ai.cc/v2/video/generations', {
method: 'POST',
headers: {
Authorization: 'Bearer ',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'klingai/video-o1-reference-to-video',
prompt: 'A graceful ballerina dancing outside a circus tent on green grass, with colorful wildflowers swaying around her as she twirls and poses in the meadow.',
image_list: [
'https://storage.googleapis.com/falserverless/example_inputs/veo31-r2v-input-1.png',
'https://storage.googleapis.com/falserverless/example_inputs/veo31-r2v-input-2.png',
'https://storage.googleapis.com/falserverless/example_inputs/veo31-r2v-input-3.png',
],
}),
}).then((res) => res.json());
console.log('Generation:', response);
};
main()
import requests
def main():
url = "https://api.ai.cc/v2/video/generations"
payload = {
"model": "klingai/video-o1-reference-to-video",
"prompt": "A graceful ballerina dancing outside a circus tent on green grass, with colorful wildflowers swaying around her as she twirls and poses in the meadow.",
"image_list": [
"https://storage.googleapis.com/falserverless/example_inputs/veo31-r2v-input-1.png",
"https://storage.googleapis.com/falserverless/example_inputs/veo31-r2v-input-2.png",
"https://storage.googleapis.com/falserverless/example_inputs/veo31-r2v-input-3.png"
]
}
headers = {"Authorization": "Bearer ", "Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print("Generation:", response.json())
if __name__ == "__main__":
main()

-min-p-130x130q80.png)
Product Detail
🚀 Kling Video O1 API: Breakthrough Reference-to-Video Generation
Kuaishou's Kling Video O1 Reference-to-Video delivers unparalleled subject-consistent video generation directly from image references. This unified multimodal model leverages advanced feature extraction to impeccably preserve character, prop, and scene identity across entirely new and diverse scenarios, setting a new standard in AI-powered video creation.
⚙️ Technical Specifications
- Input Support: Accepts single or multiple reference images (up to 4 viewpoints per element) in JPG, JPEG, or PNG formats. Optional video references up to 10 seconds, 200MB, and 2K resolution are also supported.
- Output Capabilities: Generates videos ranging from 5 to 10 seconds in length, with resolutions up to 2K (1080p standard), at 30 frames per second (fps). Common aspect ratios, including 16:9, are fully supported.
- Model Architecture: Built on a powerful unified multimodal engine that incorporates Chain of Thought (CoT) reasoning, multi-element fusion, and sophisticated vision-language processing for precise identity retention and deep contextual understanding.
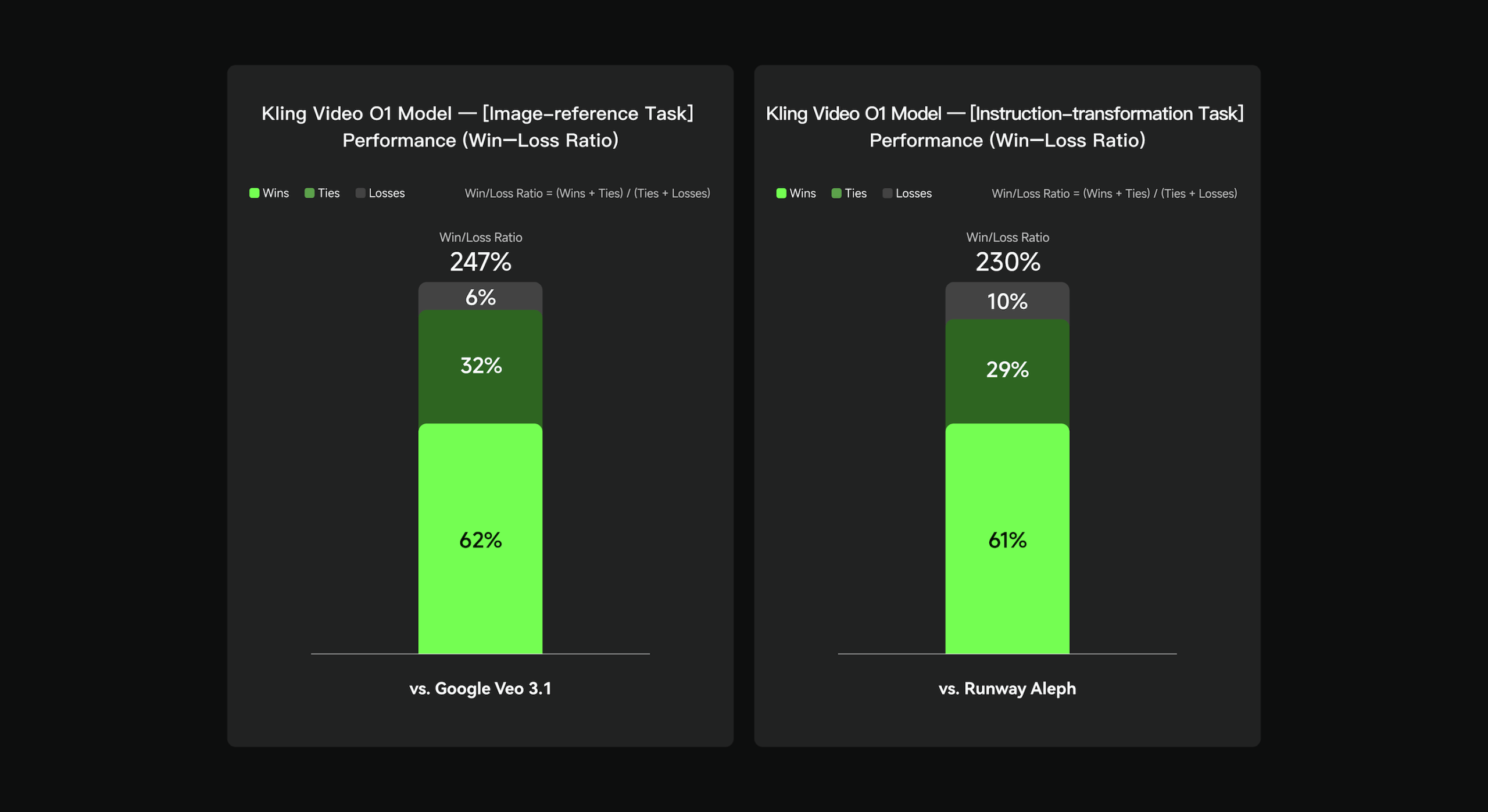
📈 Performance Benchmarks
Kling Video O1 excels in both identity consistency and motion quality, outperforming competitors in critical reference generation tasks:
- ✅ Demonstrates a 247% improvement in reference generation tasks compared to Google Veo 3.1.
- ✅ Achieved a 230% improvement over Runway Aleph in similar benchmarks.
- ✨ Features superior frame stability, effectively reducing flickering in complex multi-subject scenes.
- 🧠 Enhanced reasoning via CoT significantly boosts prompt accuracy by intelligently analyzing inputs prior to rendering.
🌟 Key Features of Kling Video O1
- 🖼️ Multi-reference Subject Building: Extracts comprehensive features from diverse viewpoints, ensuring highly stable and consistent identity for subjects within dynamic scenes.
- 🌍 New Scenario Generation: Enables the creation of entirely fresh and unique content, such as futuristic character walks or complex interactions, while rigorously maintaining reference details.
- 🎛️ Professional/Standard Modes: Offers flexible modes to balance quality and speed, alongside robust support for advanced camera control, precise motion accuracy, and realistic physics simulation.
- 융 All-in-one Reference Handling: Seamlessly fuses multiple subjects (characters, props, and entire scenes) to produce intricate, consistently coherent, and high-quality video outputs.
💲 Kling Video O1 API Pricing
The Kling Video O1 API is offered at a competitive rate:
- $0.1176 / second of generated video
💻 Code Sample
Here's an example of how to integrate the Kling Video O1 API:
<snippet data-name="video.image-list-to-video" data-model="klingai/video-o1-reference-to-video"></snippet> Comparison with Leading AI Models
Kling Video O1 stands out in the competitive landscape of AI video generation:
- 🆚 vs. Google Veo 3.1: Kling O1 outperforms Veo 3.1 by a remarkable 247% in reference fidelity, offering superior multi-view fusion without coherence loss. Veo often shows limitations in handling complex subject interactions.
- 🆚 vs. Runway Gen-4.5: Kling provides exceptional identity retention across various angles, making it ideal for professional-grade consistency. Runway Gen-4.5 focuses more on text-driven motion but struggles with stability when incorporating multiple reference inputs.
- 🆚 vs. Hailuo 2.3: Kling's advanced Chain of Thought reasoning ensures smoother physics and camera work, resulting in higher quality and more natural motion. Hailuo 2.3 may excel in generation speed but typically trails in maintaining subject stability for longer video clips.
❓ Frequently Asked Questions (FAQ)
What is Kling Video O1 Reference-to-Video?
Kling Video O1 is a unified multimodal AI model by Kuaishou that generates videos with consistent subjects, props, and scenes directly from image references, even in new scenarios.
What are the primary input types supported by Kling Video O1?
It primarily accepts single or multiple reference images (JPG, JPEG, PNG) with up to 4 viewpoints per element, and optionally video references up to 10 seconds, 200MB, and 2K resolution.
How long are the videos generated by Kling Video O1 and at what resolution?
Generated videos are typically 5-10 seconds long, with standard 1080p resolution and a maximum of 2K, at 30 frames per second.
What makes Kling Video O1 superior in identity consistency?
Its unified multimodal engine, coupled with Chain of Thought (CoT) reasoning, multi-element fusion, and vision-language processing, ensures precise and stable identity retention across complex scenes.
What is the cost of using the Kling Video O1 API?
The Kling Video O1 API is priced at $0.1176 per second of generated video content.
AI Playground

