 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in



const axios = require('axios').default;
const api = axios.create({
baseURL: 'https://api.ai.cc/v1',
headers: { Authorization: 'Bearer ' },
});
const main = async () => {
const response = await api.post('/tts', {
model: 'hume/octave-2',
text: 'OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.',
voice: 'coral',
});
console.log('Audio URL:', response.data.audio.url);
console.log('Characters:', response.data.usage.characters);
};
main();
import requests
def main():
url = "https://api.ai.cc/v1/tts"
headers = {
"Authorization": "Bearer ",
}
payload = {
"model": "hume/octave-2",
"text": "OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.",
"voice": "coral"
}
response = requests.post(url, headers=headers, json=payload)
data = response.json()
print("Audio URL:", data["audio"]["url"])
print("Characters:", data["usage"]["characters"])
main()

.png)
Product Detail
🚀 Octave 2: Next-Generation LLM-Powered Text-to-Speech
Octave 2 represents a significant leap forward in text-to-speech (TTS) technology. Powered by advanced Large Language Models (LLMs), it goes beyond simple text conversion to deeply understand the emotional and semantic nuances of text. This intelligence enables Octave 2 to generate expressive, human-like speech in real time, setting a new standard for voice quality and responsiveness across various applications.
Designed for versatility, Octave 2 delivers industry-leading audio with ultra-low latency and extensive multilingual support, making it ideal for everything from dynamic conversational AI to immersive audiobooks.
⚙️ Technical Specifications
- ✓ Supported Languages: English, Japanese, Korean, Spanish, French, Portuguese, Italian, German, Russian, Hindi, Arabic
- ✓ Latency: Impressively low at ~100 ms
- ✓ Voice Cloning: Supported with just ~15 seconds of audio input
- ✓ Audio Formats: MP3, WAV, PCM
📈 Performance Benchmarks
- 📈 Octave 2 delivers 40% faster audio generation compared to its predecessor, Octave 1, consistently achieving latencies under 200 milliseconds.
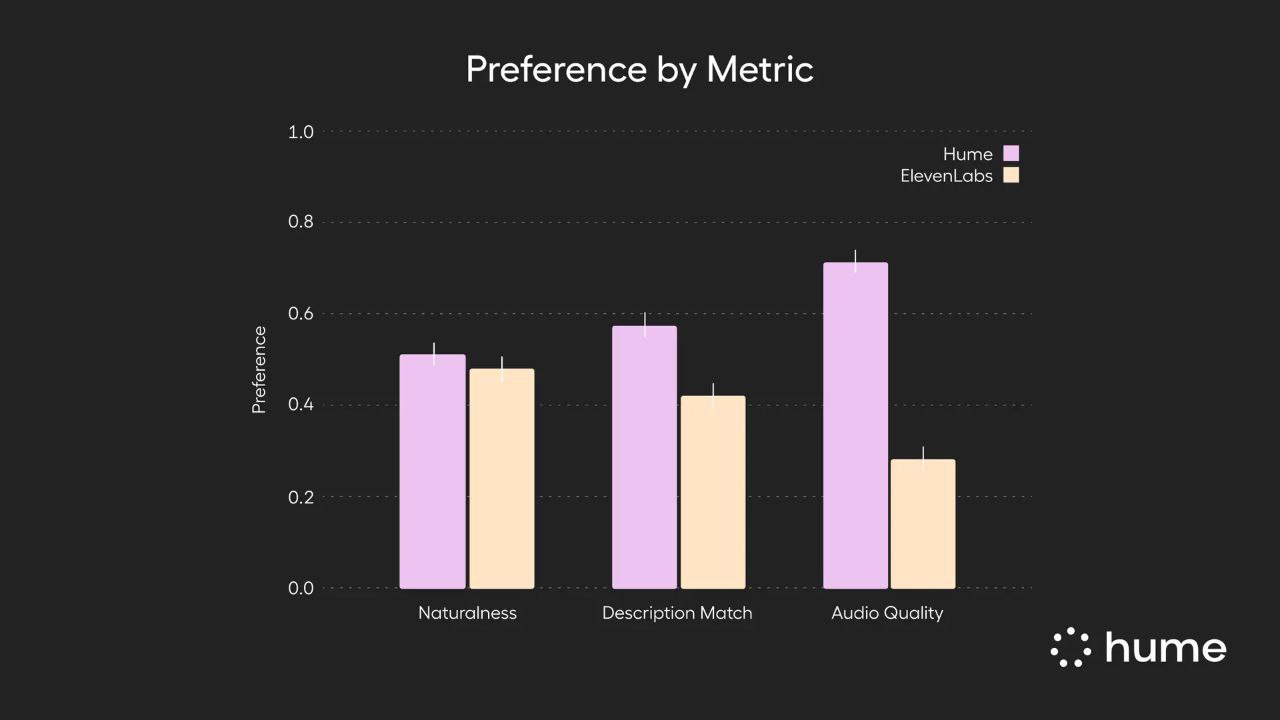
- 🎉 In blind auditory tests involving 180 human raters, Octave 2 was preferred over ElevenLabs Voice Design for audio quality (71.6%), naturalness (51.7%), and matching voice descriptions (57.7%).
- 💬 The model excels at handling complex speech patterns and subtle emotional shifts, significantly enhancing overall naturalness and expressiveness.
✨ Key Features of Octave 2
- 💡 LLM-powered Emotional Understanding: Unlike traditional TTS, Octave 2 interprets the meaning and emotional intent, modulating pitch, tempo, and emphasis to precisely match context.
- 📣 Ultra-low Latency: Experience real-time speech synthesis with model latency as low as ~100 milliseconds, perfect for interactive and conversational applications.
- 🌐 Multilingual Support: Fluent and natural synthesis in 11 key languages, including English, Japanese, Korean, Spanish, French, Portuguese, Italian, German, Russian, Hindi, and Arabic.
- 📚 Long-Form Versatility: Maintains consistent emotional tone and character voices across extended content like audiobooks and podcasts, adapting seamlessly to scene changes.
- ⚙ Advanced Features: Includes voice conversion, direct phoneme editing, and reliable pronunciation for uncommon words, numbers, and symbols.
💰 Octave 2 API Pricing
Simple and transparent pricing: $0.063 per 1000 characters.
🎯 Diverse Use Cases
- 👤 Conversational AI & Interactive Agents: Real-time, emotionally aware speech for chatbots, virtual assistants, and customer service.
- 🎧 Audiobooks & Podcasts: High-quality, long-form narration with consistent emotional tone and character voice adaptation.
- 🎨 Voice Cloning & Custom Voices: Personalized voice creation for branding, media production, and accessibility solutions.
- 🎮 Gaming & Animation: Dynamic character dialogue with nuanced emotional expression, bringing virtual worlds to life.
- 📞 Telephony & IVR Systems: Fast, natural-sounding prompts and responses for automated phone systems, enhancing user experience.
- 💪 Accessibility Tools: Enhanced screen readers and speech aids with emotional and contextual speech understanding for broader inclusion.
🆚 Octave 2 vs. Leading TTS Models
Understand how Octave 2 stands out from other prominent text-to-speech solutions:
vs. ElevenLabs: Octave 2 harnesses LLM intelligence for deeper emotional and semantic understanding, producing more nuanced speech with real-time latency (~100ms). While ElevenLabs offers natural and expressive voices, it typically lacks Octave 2's advanced semantic understanding and broader multilingual support.
vs. OpenAI TTS: OpenAI's TTS excels in clarity, prosody control, and flexible speaking styles via prompts. Octave 2 builds upon this by integrating emotional intent recognition at a semantic level, leading to significantly more human-like expressiveness and contextual depth.
vs. Mozilla TTS: Mozilla TTS is highly customizable for research and custom voice building. However, Octave 2, as a commercial-grade LLM-based system, delivers superior out-of-the-box voice quality, faster synthesis, and more natural emotional modulation and real-time responsiveness.
vs. Chatterbox: Chatterbox is optimized for low-latency dialogue and configurable expressiveness with efficient voice cloning at a smaller scale. Octave 2 surpasses Chatterbox in semantic understanding, emotional depth, long-form consistency, and comprehensive multilingual capabilities, offering a richer real-time voice experience.
❓ Frequently Asked Questions (FAQ)
Q: What makes Octave 2 different from other text-to-speech systems?
A: Octave 2 is uniquely powered by Large Language Models (LLMs) which allow it to understand the emotional and semantic context of text, generating more expressive and human-like speech in real time, unlike traditional TTS models.
Q: How low is the latency for Octave 2 speech generation?
A: Octave 2 boasts ultra-low latency, achieving real-time speech synthesis with model latency as low as approximately 100 milliseconds, making it ideal for interactive applications.
Q: Can Octave 2 support multiple languages?
A: Yes, Octave 2 offers fluent synthesis in 11 languages, including English, Japanese, Korean, Spanish, French, Portuguese, Italian, German, Russian, Hindi, and Arabic.
Q: Is Octave 2 suitable for long-form content like audiobooks?
A: Absolutely. Octave 2 is designed for long-form versatility, maintaining emotional consistency across extended content such as audiobooks and podcasts, and seamlessly adapting to character and scene changes.
Q: What is the pricing structure for the Octave 2 API?
A: The Octave 2 API is priced at a competitive rate of $0.063 per 1000 characters generated.
AI Playground

