 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'alibaba/qwen3-next-80b-a3b-instruct',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="alibaba/qwen3-next-80b-a3b-instruct",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")

-p-130x130q80-p-130x130q80.png)
Product Detail
Qwen3-Next-80B-A3B Instruct is a highly advanced, instruction-tuned large language model engineered for exceptional speed, stability, and ultra-long context handling with high throughput. It achieves significant improvements in speed and cost-efficiency by activating only a small portion of its 80 billion parameters, all without compromising performance in critical areas like complex reasoning and code generation.
⚙️ Technical Specifications
Qwen3-Next-80B-A3B Instruct optimizes its operations by activating only about 3 billion parameters out of 80 billion during inference. This sparse activation mechanism provides substantial advantages:
- Speed & Cost-Efficiency: Operates approximately 10 times faster and more cost-efficiently compared to the previous Qwen3-32B model.
- Throughput: Delivers over 10 times higher throughput when processing long contexts of 32K tokens or more.
- Flexible Deployment: Offers versatile deployment options, including serverless, on-demand dedicated, and monthly reserved hosting.
- Deployment Compatibility: Compatible with SGLang and vLLM for efficient, scalable usage, featuring advanced multi-token prediction capabilities.
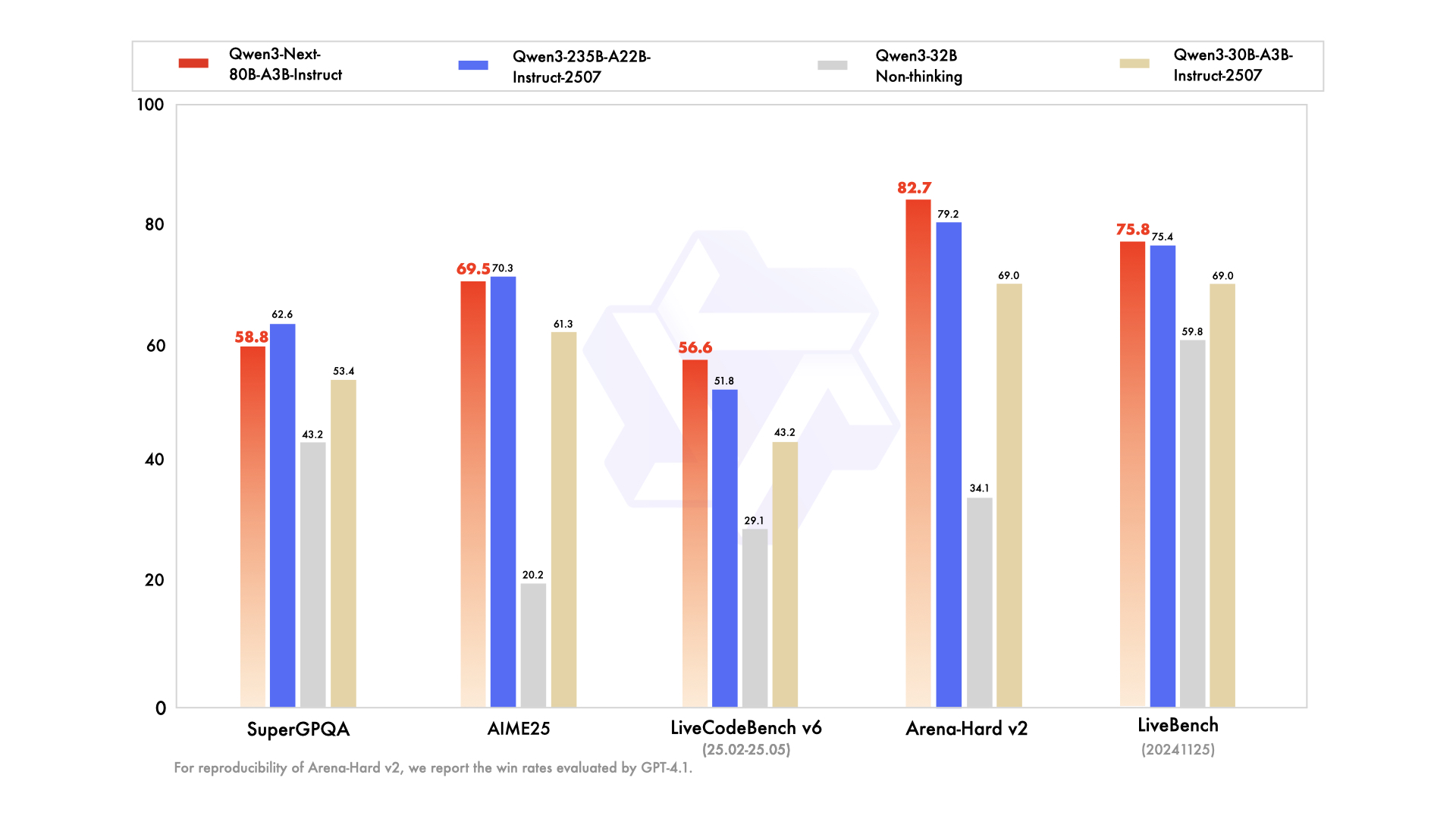
📊 Performance Benchmarks
- ✅ Top-Tier Performance: Matches or closely approximates the performance of the Qwen3-235B flagship model across various reasoning, code completion, and instruction-following tasks.
- ✅ Unwavering Long-Context Handling: Consistently provides stable and deterministic answers, particularly excelling in tasks demanding extensive context understanding.
- ✅ Resource-Efficient: Surpasses earlier mid-sized instruction-tuned models in efficiency, achieving high performance with fewer computational resources.
- ✅ Versatile Integration: Highly suitable for tools integration, Retrieval-Augmented Generation (RAG), and sophisticated agentic workflows that require consistent chain-of-thought outputs.
💰 API Pricing
Input: $0.1575
Output: $1.6
✨ Key Capabilities
- 🚀 Ultra-Efficient Inference: Employs a sparse Mixture-of-Experts (MoE) architecture, dynamically activating only 3 billion parameters out of 80 billion for significantly faster and more cost-effective inference.
- 🧠 Exceptional Task Performance: Excels in a broad range of complex tasks, including advanced reasoning, robust code generation, precise knowledge question answering, and versatile multilingual applications.
- ⚡️ Stable & Rapid Responses: Optimized for instruction mode, ensuring quick and consistent responses without intermediate "thinking" steps.
- 📖 Ultra-Long Context Handling: Features a native context length of 262K tokens, extendable up to an impressive 1 million tokens using advanced scaling technology.
- 📈 High Throughput: Achieves a 10x improvement in throughput for processing extensive long contexts compared to previous models.
- 💬 Consistent Dialogue & Answers: Ideal for multi-turn dialogues and tasks that demand deterministic, consistent final answers.
- 🛠️ Advanced Agentic Workflows: Strong capabilities for tool calling, multi-step task execution, and sophisticated agentic workflows with seamlessly integrated tools.
💡 Use Cases
- Code Generation: Accelerate software development through intelligent code suggestions and full code block generation.
- Content Creation & Editing: Generate diverse content, from articles to marketing copy, and perform intricate editing based on detailed instructions.
- Data Analysis: Facilitate complex data interpretation, statistical analysis, and comprehensive report generation.
- Customer Service Automation: Enhance customer support efficiency with precise instruction handling and automated responses.
- Technical Documentation: Streamline the creation of technical documents, manuals, and format-specific outputs.
- Process Automation: Execute multi-step tasks and integrate tool calling to automate and streamline various workflows.
- Long Conversation & Document Handling: Efficiently manage extended dialogues, summarize large documents, and extract key information from extensive texts.
💻 Code Sample
import openai client = openai.OpenAI( base_url="https://api.perplexity.ai", # Example base URL, replace with actual endpoint api_key="YOUR_API_KEY", # Replace with your actual API key ) messages = [ { "role": "system", "content": "You are Qwen3-Next-80B-A3B Instruct, a helpful AI assistant." }, { "role": "user", "content": "Explain the concept of quantum entanglement in simple terms for a high school student." }, ] response = client.chat.completions.create( model="alibaba/qwen3-next-80b-a3b-instruct", messages=messages, max_tokens=500, temperature=0.7, top_p=0.9, frequency_penalty=0, presence_penalty=0, ) print(response.choices[0].message.content) Note: The `base_url` and `api_key` in the example above are placeholders. Please refer to the official API documentation for specific integration details.
🆚 Comparison with Other Models
The 80B A3B model offers performance that matches or closely approaches the flagship 235B in reasoning and code tasks, while being significantly more efficient by activating fewer parameters for faster and more cost-effective inference.
Qwen3-Next delivers comparable instruction-following and long-context capabilities, distinguished by an advantage in throughput and a larger token window size, making it particularly well-suited for extensive document comprehension tasks.
Qwen3-Next exhibits superior performance in multi-turn dialogues and agentic workflows, providing more deterministic outputs on very long contexts compared to Claude’s conversational strengths.
Qwen3-Next shows better scaling in ultra-long context handling and superior multi-token prediction efficiency, giving it a distinct advantage in processing complex, multi-step reasoning tasks.
❓ Frequently Asked Questions
Q1: What makes Qwen3-Next-80B-A3B Instruct exceptionally efficient?
The model leverages a sparse Mixture-of-Experts (MoE) architecture, activating only approximately 3 billion out of its 80 billion parameters during inference. This innovative approach leads to significantly faster processing and lower operational costs, achieving up to 10 times greater efficiency than earlier models.
Q2: How does it perform with ultra-long contexts?
Qwen3-Next-80B-A3B Instruct supports a native context length of 262K tokens, and with advanced scaling technology, this can be extended to an impressive 1 million tokens. This capability makes it ideal for tasks requiring deep comprehension of extensive documents and long conversations.
Q3: How does its performance stack up against other leading language models?
While being highly efficient, Qwen3-Next-80B-A3B Instruct matches or closely approaches the performance of flagship models like Qwen3-235B in complex reasoning and code generation tasks. It also offers comparable or superior capabilities in throughput, long-context handling, and deterministic outputs when compared to models like GPT-4.1, Claude 4.1 Opus, and Gemini 2.5 Flash.
Q4: What are the primary use cases for Qwen3-Next-80B-A3B Instruct?
This model is exceptionally well-suited for applications demanding high throughput, precise instruction-following, and extensive context processing. Key use cases include advanced code generation, sophisticated content creation, detailed data analysis, automated customer service, technical documentation, and complex agentic workflows.
Q5: Is Qwen3-Next-80B-A3B Instruct compatible with existing deployment infrastructures?
Yes, the model is designed for seamless integration with existing deployment tools such as SGLang and vLLM, supporting advanced multi-token prediction capabilities. It also provides flexible deployment options including serverless, on-demand dedicated, and monthly reserved hosting to fit various operational needs.
AI Playground

