 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'alibaba/qwen3-vl-32b-instruct',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="alibaba/qwen3-vl-32b-instruct",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Product Detail
✨ Discover Qwen3 VL 32B Instruct: Your Advanced Vision-Language AI
The Qwen3 VL 32B Instruct is a cutting-edge vision-language large model (VL) specifically engineered for precise instruction-following across a spectrum of visual tasks. It stands out in its ability to interpret complex visual inputs and generate highly coherent, context-aware textual outputs. This model is meticulously optimized to excel in image description, engaging visual dialogue, and versatile content generation, making it a powerful tool for multimodal AI applications.
As detailed in its Official Qwen3 VL 32B Overview, the Qwen3 VL 32B Instruct is a "non-thinking only" version, meaning it's streamlined for direct, efficient execution of visual tasks rather than broader general reasoning, ensuring superior performance in its specialized domain.
⚙️ Technical Specifications at a Glance
- Model Type: Vision-Language Large Model (VL)
- Parameter Count: 32 Billion Parameters
- Architecture: Transformer-based multimodal architecture, integrating a robust visual encoder with a sophisticated text decoder.
- Input Modalities: Supports seamless integration of Images + Text instructions/prompts.
- Output Modalities: Specialized in high-quality Text Generation (descriptions, dialogues, creative content).
- Training Data: Trained on a vast, large-scale multimodal dataset comprising meticulously annotated images paired with rich descriptive and conversational text.
- Inference Capabilities: Offers strong zero-shot and few-shot instruction following, eliminating the need for extensive retraining.
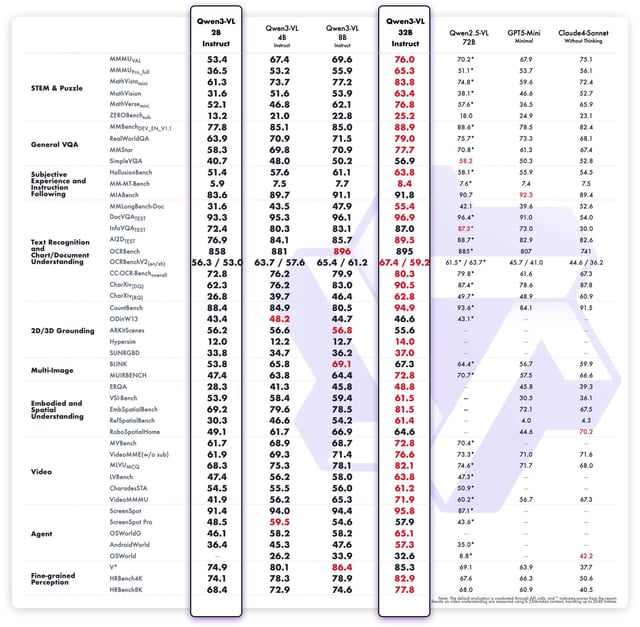
🚀 Unmatched Performance & Benchmarks
- 🎯 Achieves state-of-the-art accuracy on leading visual description datasets, rigorously benchmarked against COCO Caption and VQA tasks.
- 📈 Demonstrates superior instruction-following abilities, validated through human evaluations for exceptional relevance and coherence.
- 💡 Outperforms previous Qwen VL versions in multimodal content generation quality and precise instruction alignment.
- 🔒 Exhibits robust zero-shot performance in complex visual dialogue tasks when compared to baseline models.
🌟 Key Features & Advantages
- ✨ Precise Image Descriptions: Optimized for generating exceptionally clear and accurate image descriptions based on user instructions.
- 💬 Engaging Visual Dialogues: Capable of understanding intricate visual contexts and participating in dynamic visual dialogues.
- 🎨 Creative Content Generation: Produces highly relevant and innovative visual content directly from textual prompts.
- ✔️ High Instruction Alignment: Minimizes irrelevant or hallucinatory content by ensuring strong alignment with user instructions.
- 🖼️ Efficient High-Resolution Processing: Handles large, high-resolution images efficiently with fine-grained visual understanding.
- 🌍 Multilingual Output: Supports multilingual text output, demonstrating strong language fluency across various languages.
- 🔌 Easy Integration: Designed for straightforward integration into AI-driven content creation pipelines and interactive visual assistants.
💰 Qwen3 VL 32B API Pricing
- ➡️ Input: $0.735 / 1 Million Tokens
- ⬅️ Output: $2.94 / 1 Million Tokens
💡 Versatile Use Cases
- 📸 Automated Image Captioning: Ideal for digital asset management systems, providing instant, accurate descriptions.
- 🗣️ Visual QA & Customer Support: Enhances customer service bots with interactive visual question answering capabilities.
- ✍️ Marketing & Content Creation: Powers content generation for marketing campaigns, social media, and creative storytelling using images.
- 🚶♀️ Assistance for Visually Impaired: Describes visual scenes in rich detail, offering invaluable support.
- 🔍 Enhanced Multimedia Search: Improves search engine capabilities through advanced image-based context understanding.
- 📚 Educational Applications: Supports interactive visual explanations and tutorials, making learning more engaging.
💻 Code Sample for Integration
Below is a typical code snippet demonstrating how to interact with the Qwen3 VL 32B Instruct API.
import openai client = openai.OpenAI( api_key="YOUR_API_KEY", # Replace with your actual API key base_url="https://api.your-provider.com/v1" # Replace with your API endpoint ) response = client.chat.completions.create( model="alibaba/qwen3-vl-32b-instruct", messages=[ {"role": "system", "content": "You are a helpful assistant that can describe images."}, {"role": "user", "content": [ {"type": "text", "text": "What is in this image?"}, {"type": "image_url", "image_url": {"url": "https://example.com/image.jpg"}} ]} ], max_tokens=500 ) print(response.choices[0].message.content) 🆚 Qwen3 VL 32B Instruct vs. Other Leading Models
vs. Qwen3 VL 32B Base:
The Instruct version is meticulously fine-tuned for superior instruction adherence, yielding more context-relevant and accurate descriptions. In contrast, the Base model primarily targets general multimodal understanding.
vs. OpenAI GPT-4 (with vision):
Qwen3 VL 32B Instruct is purpose-built and optimized for specialized instruction-following and visual content generation, demonstrating fewer hallucinations on visual inputs. While GPT-4 offers broader general AI capabilities, it can be less specialized in direct visual instruction adherence.
vs. Claude 4.5 Visual:
Qwen3 VL 32B Instruct delivers stronger image description and dialogue quality, with a focused emphasis on visual instructions. Claude, while excellent in text-based reasoning and managing larger contexts, typically offers slightly less visual specialization.
vs. DeepSeek V3.1:
Qwen3 VL 32B Instruct excels in detailed content generation and sophisticated visualization tasks. DeepSeek, on the other hand, is more oriented towards semantic image search and retrieval functionalities.
❓ Frequently Asked Questions (FAQ)
Q: What is Qwen3 VL 32B Instruct primarily designed for?
A: It's a specialized vision-language model optimized for instruction-following in tasks like precise image description, engaging visual dialogue, and intelligent content generation based on visual inputs and textual prompts.
Q: How does Qwen3 VL 32B Instruct compare to its Base version?
A: The Instruct version is specifically fine-tuned for enhanced instruction adherence, resulting in more accurate and context-relevant descriptions, unlike the Base model which provides general multimodal understanding.
Q: What are the key advantages of using Qwen3 VL 32B Instruct?
A: Key advantages include precise image description, robust visual dialogue capabilities, creative content generation with high instruction alignment, efficient handling of high-resolution images, and multilingual text output.
Q: Can Qwen3 VL 32B Instruct be used in real-world applications?
A: Absolutely. It's ideal for automated image captioning, visual Q&A in customer service, AI-driven content creation, assisting visually impaired users, enhancing multimedia search, and interactive educational tools.
Q: What is the pricing structure for the Qwen3 VL 32B API?
A: The pricing is tiered: Input costs $0.735 per 1 Million tokens, and Output costs $2.94 per 1 Million tokens.
AI Playground

