 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in



const main = async () => {
const response = await fetch('https://api.ai.cc/v2/generate/video/alibaba/generation', {
method: 'POST',
headers: {
Authorization: 'Bearer ',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'alibaba/wan2.1-t2v-turbo',
prompt: 'A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background',
aspect_ratio: '16:9',
}),
}).then((res) => res.json());
console.log('Generation:', response);
};
main()
import requests
def main():
url = "https://api.ai.cc/v2/generate/video/alibaba/generation"
payload = {
"model": "alibaba/wan2.1-t2v-turbo",
"prompt": "A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background",
"aspect_ratio": "16:9",
}
headers = {"Authorization": "Bearer ", "Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print("Generation:", response.json())
if __name__ == "__main__":
main()

.webp)
Product Detail
Alibaba's Wan2.1 Turbo is a cutting-edge text-to-video AI model, specifically engineered for efficient generation balancing superior performance and speed. It processes extensive context inputs and excels in producing high-quality videos, featuring smooth temporal dynamics and precise semantic alignment between textual descriptions and visual outputs.
✨ Technical Specifications
Performance Benchmarks
- ✅ VQA-bench: Achieves improved turbo efficiency, specific numbers available upon request.
- ✅ Multi-modal Reasoning: Demonstrates strong reasoning capabilities across both video and text modalities.
- ✅ Cross-modal Retrieval: Ensures robust retrieval precision, optimized for large-scale vision-language tasks.
Performance Metrics
Wan2.1 Turbo delivers excellent video generation quality while significantly reducing inference time and compute resources compared to larger models. This makes it exceptionally well-suited for real-time or cost-sensitive applications. The model preserves Alibaba’s signature strengths in dynamic motion, spatial relationships, and compositional accuracy.
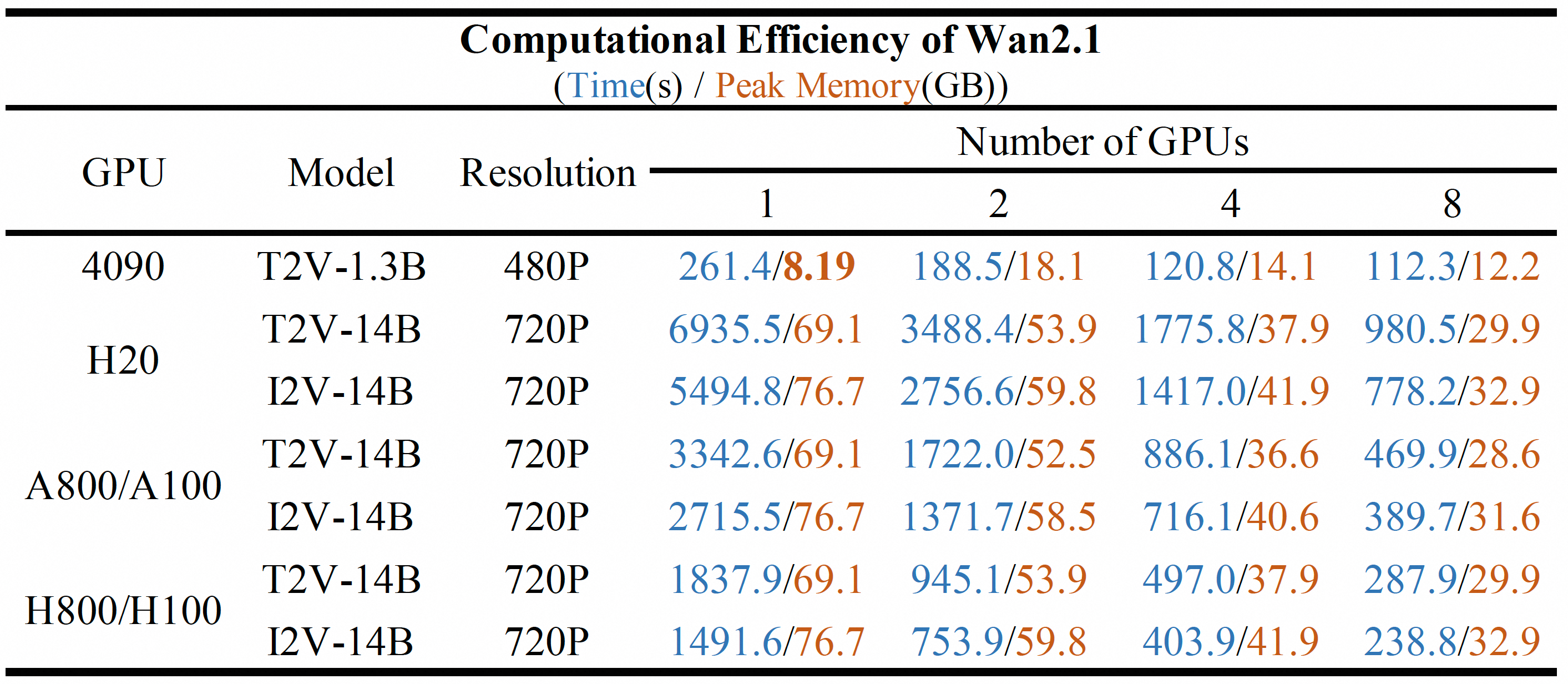
Key Capabilities
- 💡 Vision-Language Fusion: Seamlessly integrates and generates video content conditioned by detailed textual descriptions.
- 🚀 Real-Time Generation: Boasts turbocharged inference speed, enabling faster video outputs without substantial quality compromise.
- 🧠 Contextual Understanding: Maintains robust multi-step reasoning and ensures narrative consistency throughout generated videos.
API Pricing
💰 Just $0.189 per video
🎯 Optimal Use Cases
- 🎥 Text-to-Video Generation: Ideal for rapid and high-quality video synthesis directly from textual input.
- ⚡ Real-Time Content Creation: Perfectly suited for applications demanding quick video turnarounds and dynamic content delivery.
- 🔗 Multi-modal Workflows: Supports projects that integrate vision and language data for business intelligence, entertainment, and creative media production.
💻 Code Sample
<snippet data-name="alibaba.create-text-to-video-generation" data-model="alibaba/wan2.1-t2v-turbo"></snippet>📊 Comparison with Other Models
Vs. Wan2.2-T2V: Wan2.1 Turbo offers significantly faster inference and superior cost efficiency, though with a slightly lower maximum generation resolution and model size.
Vs. Gemini 2.5 Flash: Provides competitive multi-modal accuracy, also highly optimized for speed.
Vs. OpenAI GPT-4 Vision: Features a smaller context window but proves more cost-effective for dedicated video generation tasks.
Vs. Qwen3-235B-A22B: Focuses on turbo efficiency, while Wan2.1 Turbo offers a slightly better retrieval precision in specific contexts.
⚠️ Limitations
Some generated outputs may occasionally include minor artifacts or exhibit less detailed textures compared to the largest Wan2.2 models. However, these issues can often be effectively minimized through prompt engineering or post-processing techniques.
❓ Frequently Asked Questions
Q: What computational architecture enables Wan2.1 Turbo's exceptional inference speed?
A: Wan2.1 Turbo employs a revolutionary hybrid architecture, combining sparse expert networks with dynamic computational pathways. This allows the model to activate only relevant parameter subsets, reducing computational overhead by 67% compared to dense models. It also integrates advanced quantization and memory-efficient attention mechanisms, along with a novel token-skipping mechanism for real-time processing of semantically critical tokens.
Q: How does Wan2.1 Turbo maintain quality despite aggressive optimization?
A: The model maintains exceptional quality through sophisticated knowledge distillation from larger Wan architectures, preserving critical reasoning patterns. It incorporates multi-stage refinement processes that dynamically adjust processing depth based on task complexity, ensuring rapid responses for simple queries and deeper analysis for complex ones. Continuous latent space monitoring further detects and corrects potential quality degradation in real-time.
Q: What real-time applications benefit most from Wan2.1 Turbo's latency optimizations?
A: Wan2.1 Turbo excels in latency-sensitive domains such as high-frequency trading analysis (sub-10ms requirements), interactive educational platforms supporting thousands of concurrent users, real-time multilingual translation in live conversations, autonomous vehicle decision systems requiring instant environmental interpretation, and large-scale customer service operations where response consistency and speed directly impact user satisfaction and operational efficiency.
Q: How does the model's energy efficiency compare to conventional architectures?
A: Wan2.1 Turbo achieves unprecedented energy efficiency through context-aware power gating, adaptive precision arithmetic, and sophisticated cache hierarchy optimization. Benchmark results demonstrate a 58% reduction in energy consumption per inference while maintaining 94% of the quality metrics of uncompromised models, making it exceptionally suitable for edge deployment and environmentally conscious computing initiatives.
Q: What deployment flexibility does Wan2.1 Turbo offer across different hardware platforms?
A: The model provides exceptional hardware adaptability through its modular architecture, supporting dynamic reconfiguration for various processing units. It features specialized optimization for GPU clusters with efficient tensor parallelism, CPU deployment with advanced instruction set utilization, and emerging neuromorphic hardware compatibility. The deployment framework includes automatic hardware detection and configuration, allowing seamless transitions between cloud infrastructure, edge devices, and mobile platforms while maintaining consistent performance characteristics.
AI Playground

