 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in



const main = async () => {
const response = await fetch('https://api.ai.cc/v2/generate/video/alibaba/generation', {
method: 'POST',
headers: {
Authorization: 'Bearer ',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'alibaba/wan2.2-t2v-plus',
prompt: 'A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background',
aspect_ratio: '16:9',
}),
}).then((res) => res.json());
console.log('Generation:', response);
};
main()
import requests
def main():
url = "https://api.ai.cc/v2/generate/video/alibaba/generation"
payload = {
"model": "alibaba/wan2.2-t2v-plus",
"prompt": "A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background",
"aspect_ratio": "16:9",
}
headers = {"Authorization": "Bearer ", "Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print("Generation:", response.json())
if __name__ == "__main__":
main()

.webp)
Product Detail
Alibaba's Wan2.2 is a state-of-the-art AI model meticulously engineered for advanced multi-modal understanding. It seamlessly integrates both text and vision inputs, offering robust capabilities for large context processing and delivering superior precision in complex text-to-vision tasks and intricate reasoning challenges.
✨ Technical Specifications
Performance Benchmarks
- ✅ VQA-bench: 78.3%
- ✅ Multi-modal Reasoning: 52.7%
- ✅ Cross-modal Retrieval: 81.9%
Performance Metrics (Wan2.1)
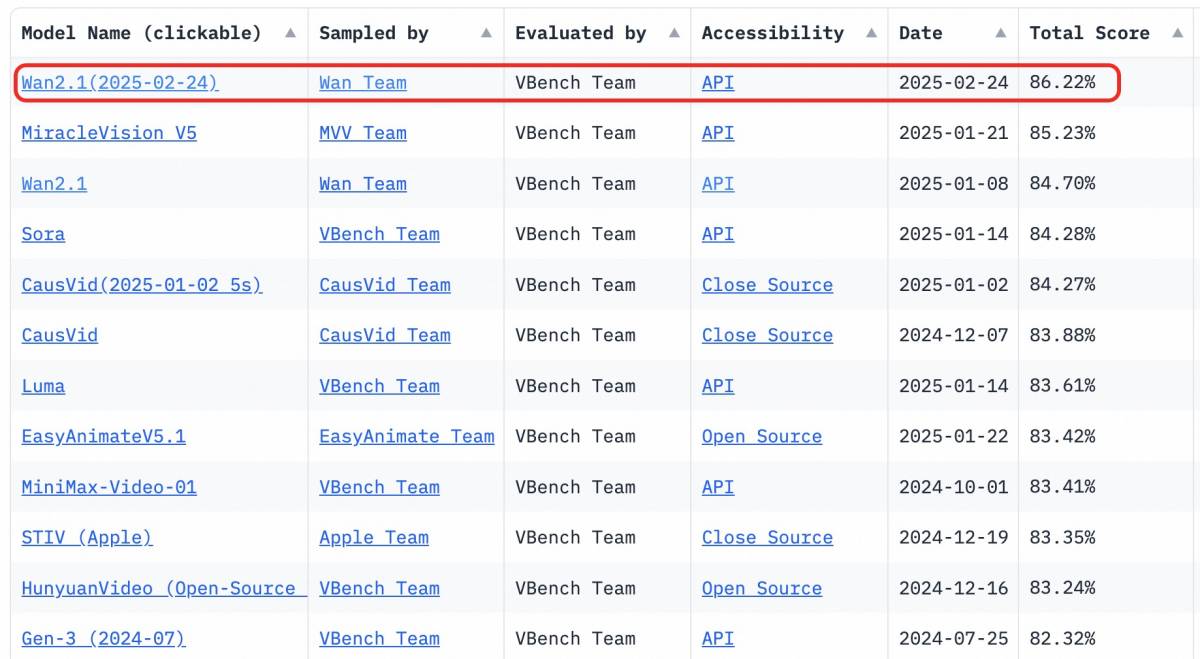
Wan2.1 leads with an impressive overall VBench score of 86.22%, demonstrating exceptional performance in dynamic motion, spatial relationships, color accuracy, and multi-object interaction. Training foundational video models demands significant compute power and access to vast, high-quality datasets. Open access to such advanced models drastically reduces barriers, empowering more businesses to create tailored, high-quality visual content in a cost-effective manner.
Key Capabilities
- 💡 Vision-Language Fusion: Excels at interpreting and generating precise responses by seamlessly combining image and text data.
- 💡 Advanced Reasoning: Demonstrates strong multi-step reasoning abilities across various modalities for in-depth analytics and complex understanding.
💲 API Pricing
- 🎥 480P: $0.105/video
- 🎥 1080P: $0.525/video
🚀 Optimal Use Cases
- ✅ Multi-modal Analysis: Enhancing comprehension through the expert combination of image and text data.
- ✅ Visual Question Answering (VQA): Providing accurate and context-aware answers based on integrated image-text inputs.
- ✅ Cross-modal Retrieval: Enabling efficient matching and retrieval of information across both vision and language domains.
- ✅ Business Intelligence: Facilitating complex data interpretation by integrating visual content with textual analytics for deeper insights.
💻 Code Sample
📊 Comparison with Other Leading Models
- Vs. Gemini 2.5 Flash: Alibaba Wan2.2 offers higher multi-modal accuracy (78.3% vs. 70.8% VQA-bench), making it a superior choice for integrated vision-language tasks.
- Vs. OpenAI GPT-4 Vision: Wan2.2 provides a significantly larger context window (65K vs. 32K tokens text), enabling more extensive and coherent conversations with embedded images.
- Vs. Qwen3-235B-A22B: Alibaba Wan2.2 demonstrates superior cross-modal retrieval precision (81.9% vs. ~78% estimated), optimizing it for demanding large-scale vision-language workflows.
⚠️ Limitations
Occasionally, generated videos may contain unwanted elements such as text artifacts or watermarks. While employing negative prompts can help mitigate these occurrences, it does not fully eliminate them.
🔗 API Integration
Alibaba Wan2.2 is readily accessible via the AI/ML API. Comprehensive documentation is available to facilitate a smooth and efficient integration process.
❓ Frequently Asked Questions (FAQ)
A: Alibaba Wan2.2 is an advanced AI model engineered for multi-modal understanding, specifically integrating text and vision inputs for complex reasoning and high-precision text-to-vision tasks.
A: Wan2.2 demonstrates higher multi-modal accuracy (78.3% VQA-bench) compared to Gemini 2.5 Flash (70.8%), making it particularly effective for integrated vision-language tasks.
A: Its primary capabilities include robust vision-language fusion for interpreting and generating content from combined image and text data, and advanced multi-step reasoning across modalities.
A: Occasionally, generated videos might contain unwanted elements such as text artifacts or watermarks. While negative prompts can mitigate these, they don't fully eliminate them.
A: Alibaba Wan2.2 is easily accessible through the AI/ML API, with comprehensive documentation provided to guide the integration process.
AI Playground

