 企业API定制计划
企业API定制计划 AI应用开发服务
AI应用开发服务 AI智能翻译API
AI智能翻译API AI SEO/GEO 服务
AI SEO/GEO 服务 地理优化公关服务
地理优化公关服务 网络爬虫服务
网络爬虫服务
 登录
登录
 聊天
聊天  视频
视频  图像
图像  嗓音
嗓音  音乐
音乐  代码
代码  OCR
OCR  嵌入
嵌入  人工智能搜索
人工智能搜索  3D
3D  安全与审核
安全与审核 





- API 操练场(Playground)

在集成之前,请在沙箱环境中测试所有 API 模型。
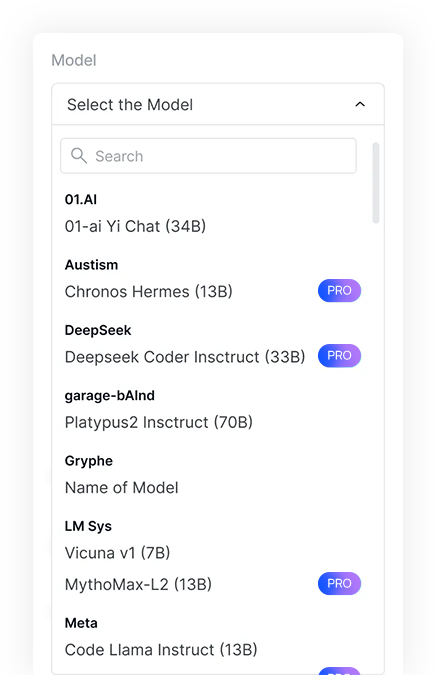
我们提供 300 多种模型供您集成到您的应用程序中。
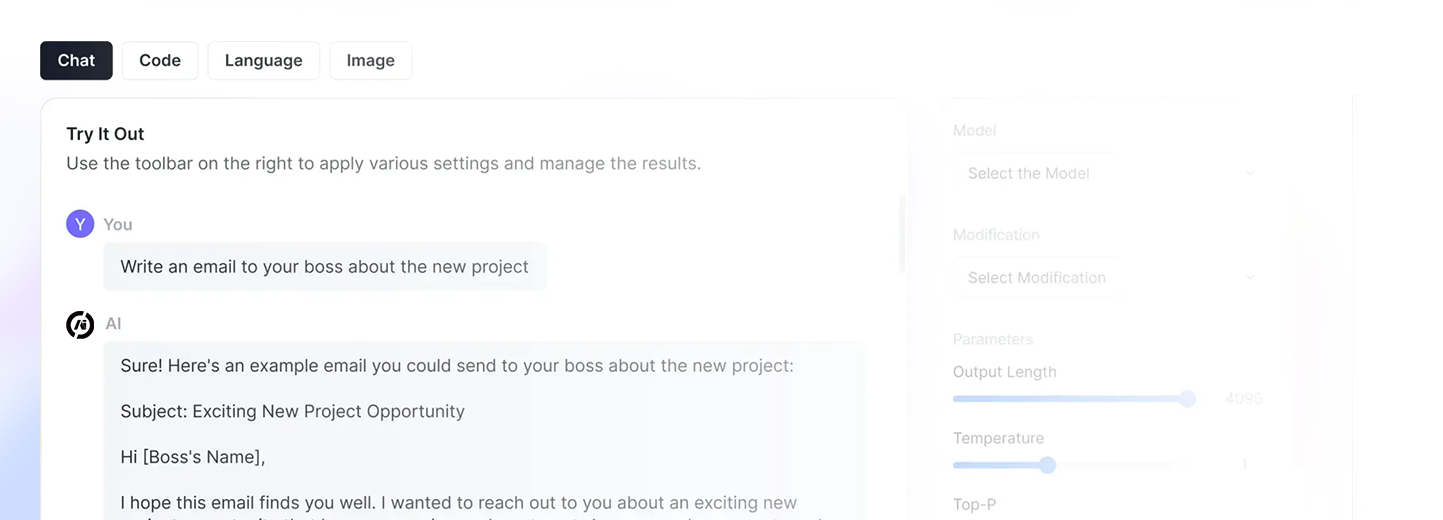
- 简单集成

只需更改现有文件中的端点即可
设置完毕,就可以出发了。
- 无限可扩展性

使用我们的AI API,体验低延迟,即时部署。
并且超越速率限制而不会产生影响。







一个 API 全部完成
一个界面即可调用 300 多个型号,实现统一计费和密钥管理。
最高速度,无限缩放
低延迟、高并发(无限TPM/RPM*),应用程序运行流畅,不会卡顿。
省钱多多,最高可享20%折扣
主流模型价格更低,可以直接为您节省人工智能方面的支出。

完全自由选择,无合约限制
300多种模型可随意切换,不受单一供应商限制,掌控未来。
90
M+
每日请求
10
K+
活跃用户
99
%
满意度
300
+
集成模型
-
1. 什么是 AICC API?
-
2. 我该如何开始?
-
3. 它适合我的业务吗?
AICC 是需要快速、可扩展 AI 解决方案的企业的理想之选。它拥有超过 400 个模型和低延迟响应,非常适合高级机器学习项目。其经济高效的无服务器架构最大限度地降低了部署和维护成本,使其成为各种规模企业的理想选择。 -
4. 如何跟踪使用情况和成本?
您可以通过平台控制面板跟踪使用情况和费用,该面板提供 API 使用情况、请求和响应时间的实时数据。您还可以设置提醒,以便管理限额并避免意外费用。透明的费用结构显示历史账单,而无服务器架构确保您只需为实际使用的资源付费,从而帮助您优化并降低成本。 -
5. 可以获得哪些支持?
该平台提供全天候支持,性能可靠稳定。您可以访问各种资源,包括文档、常见问题解答,以及一支专业的支持团队,随时为您解决任何问题。