 OpenAI - ChatGPT、Sora
OpenAI - ChatGPT、Sora Google - Gemini,Nano Banana
Google - Gemini,Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok DeepSeek
DeepSeek 阿里巴巴 - Qwen
阿里巴巴 - Qwen 字节跳动 - 豆包
字节跳动 - 豆包 所有型号
所有型号 企业API定制计划
企业API定制计划 AI应用开发服务
AI应用开发服务 AI智能翻译API
AI智能翻译API AI SEO/GEO 服务
AI SEO/GEO 服务 GEO/AI大模型优化
GEO/AI大模型优化 网络爬虫服务
网络爬虫服务 OpenClaw
OpenClaw 顶级人工智能工具
顶级人工智能工具 顶级人工智能机器人
顶级人工智能机器人
 登录
登录



const main = async () => {
const response = await fetch('https://api.ai.cc/v2/video/generations', {
method: 'POST',
headers: {
Authorization: 'Bearer ',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'tencent/hunyuan-video-foley',
video_url: 'https://storage.googleapis.com/falserverless/model_tests/video_models/1_video.mp4',
prompt: 'A person walks on frozen ice',
}),
}).then((res) => res.json());
console.log('Generation:', response);
};
main()
import requests
def main():
url = "https://api.ai.cc/v2/video/generations"
payload = {
"model": "tencent/hunyuan-video-foley",
"video_url": "https://storage.googleapis.com/falserverless/model_tests/video_models/1_video.mp4",
"prompt": "A person walks on frozen ice",
}
headers = {"Authorization": "Bearer ", "Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print("Generation:", response.json())
if __name__ == "__main__":
main()


产品详情
✨ 混源视频拟音:AI驱动的视频音效生成
混源视频拟音 代表了一种由……开发的创新型人工智能模型 腾讯混源团队这种先进的解决方案经过精心设计,旨在生成 高品质、细节丰富的音效 对于无声视频,这极大地增强了视觉媒体的听觉体验。通过利用最先进的技术 多模态扩散 通过技术和广泛的大规模数据训练,它能够熟练地合成与视频内容和附带的文本描述完全一致的音频。
⚙️ 技术规格
- 建筑学: 一个强大的多模态扩散模型,无缝地结合了视频、文本和音频模态,并通过专门的对齐损失和音频 VAE 优化进一步增强。
- 音频采样率: 提供卓越的高保真音频输出 48 kHz。
- 模型组件: 整合 DAC-FOOT 用于实现卓越的音频重建和复杂的多模态变换器模块,以实现连贯的视频和文本联合集成。
- 训练数据: 在包括 Kling-Audio-Eval、VGGSound 和 MovieGen-Audio 在内的庞大数据集上进行了广泛的训练,涵盖了广泛的声音、音乐和语音领域。
- 输出特性: 生成在视觉和语义上与相应视频帧精确对齐的时间同步音频流。
🚀 无与伦比的性能标杆
在一系列严格的基准测试中,包括 Kling-Audio-Eval、VGGSound-Test 和 MovieGen-Audio-Bench, 混源视频拟音始终展现出卓越的性能超越了 FoleyCrafter、MMAudio、V-AURA 和 ThinkSound 等领先竞争对手。

该模型在关键性能指标方面始终处于领先地位: 音频保真度、视觉和声音之间的语义一致性、时间同步性和分布匹配在这些方面,它始终优于所有知名的开源模型。经客观评估和专家人工评估验证,混源视频拟音表现出色。 稳健的性能 在广泛的视频内容和音频场景中,证实了其在各种实际应用中的可靠性。
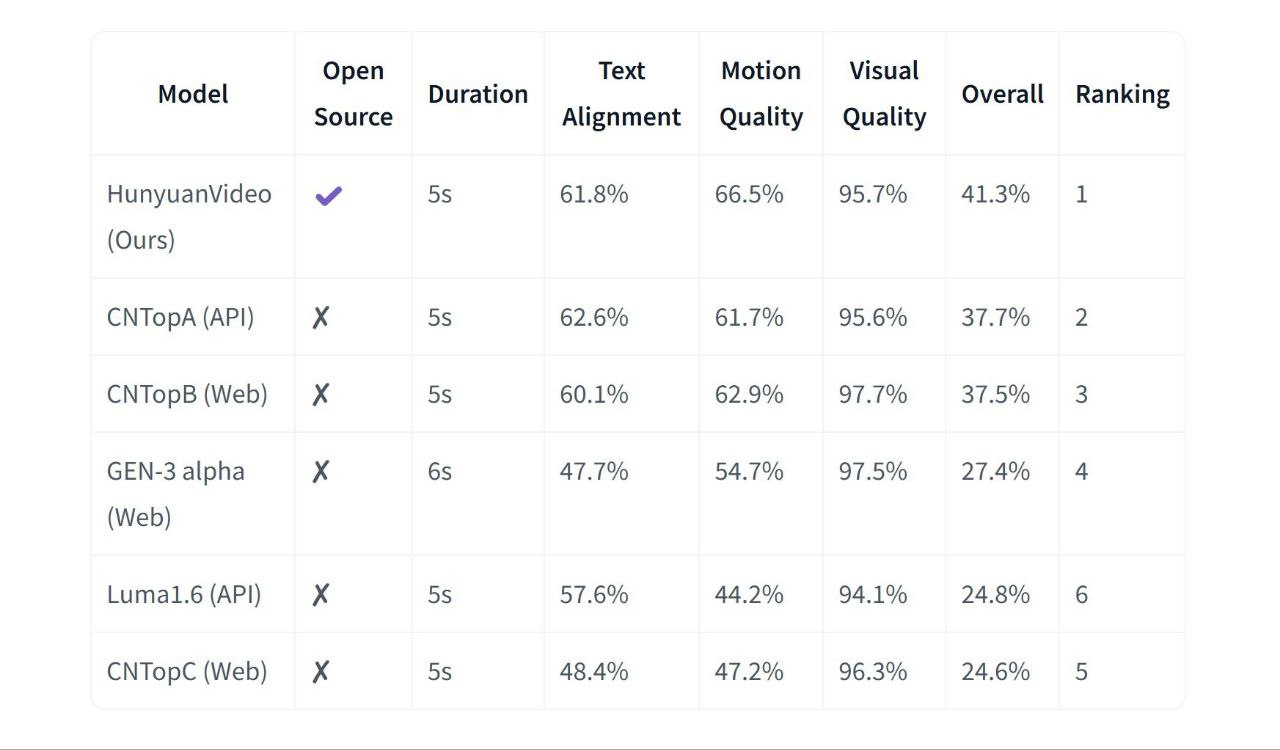
💡 主要特点和优势
- ✅ 自动生成拟音: 将无声视频和附带文本转换为生动、贴合语境且身临其境的音效。
- 🌍 多场景适用性: 具有很强的适应性,适用于各种应用,包括短视频创作、专业电影后期制作、动态广告和沉浸式游戏开发。
- 🔊 高保真音频输出: 即使是最细微的音频细节也能捕捉到,从细微的物体碰撞声到复杂而广阔的环境氛围声。
- ⚖️语义均衡响应: 智能处理和平衡输入的视频和文本描述,以构建整体且完美平衡的音景。
- 🏗️ 强大的音频重建: 由其驱动 DAC-VAE骨干网确保在一般声音、复杂的音乐作品和清晰的语音领域中始终保持强劲可靠的性能。
💰 灵活的 API 定价
价格非常实惠,仅售 0.0105美元 每秒。
🎯 多样化的应用和用例
- 🎥 短视频和社交视频创作: 利用动态且与情境相关的音效,显著提升观众的参与度。
- 🎬 影视后期制作音效设计: 简化和提升专业声音设计工作流程,节省时间和资源。
- 📈 营销和广告视频音频增强: 利用引人入胜、富有说服力的音频提升视频广告效果,增强广告影响力。
- 🎮 游戏开发中的沉浸式音频: 创造丰富、互动且真正身临其境的音景,以增强玩家体验。
- 🗣️ 自动配音和拟音替换: 高效地替换或生成关键音频元素,包括对话和音效,以实现全球覆盖。
💻 集成:代码示例
生成代码示例
输出代码示例
🆚 混源视频拟音 vs. 竞争对手
vs Runway Gen-3: 混源视频拟音器擅长生成高度同步、高保真的视频音效,尤其注重音画精准匹配和逼真效果。相比之下,Runway Gen-3 主要专注于视觉文本到视频的合成,并提供更全面的视频编辑工具,但并不具备集成的音频特效生成功能。
对比 Luma 1.6: Foley 在音视频语义同步和整体音质方面显著优于 Luma 1.6。Luma 1.6 擅长保持视频在空间和时间上的一致性,但并不提供音效生成功能。混源视频 Foley 独具特色地实现了专业级 Foley 音效的自动化生成。
vs Wan 2.1: Wan 2.1 专为多语言文本转视频生成而设计,硬件要求较低,使用起来也更方便;而 Foley 则专注于高端、计算密集型的拟音生成,专为专业应用而打造。需要注意的是,Wan 2.1 不支持像混源视频 Foley 那样能够高效生成的同步音频效果。
❓ 常见问题解答 (FAQ)
Q1:什么是混源视频拟音?
混源视频拟音是腾讯混源团队开发的高级人工智能模型。它专门用于根据视频内容和任何随附的文字描述,自动为无声视频生成高质量、完美同步的音效。
Q2:哪些类型的项目可以从混源视频拟音中受益?
它用途广泛,非常适合各种应用,包括短视频和社交视频创作、专业电影和电视后期制作、增强营销和广告视频以及为游戏开发创建沉浸式音频。
Q3:混源视频拟音是如何保证如此高保真音频的?
该模型采用复杂的多模态扩散架构,融合了DAC-VAE骨干网络,并在海量数据集上进行训练。这种精细的设计确保了稳健的音频重建能力,并能以惊人的48 kHz采样率捕捉到精细的声音细节。
Q4:混源视频拟音的输出是否兼容移动设备?
是的,生成的音频和提供的 HTML 结构均采用完全响应式和兼容的设计,确保用户在各种移动设备和平台上都能获得流畅、高质量的体验。
Q5:混源视频拟音与其他知名AI模型(如Runway Gen-3)相比如何?
混源视频Foley的独特之处在于其专注于卓越的视听同步和高保真音效生成。虽然像Runway Gen-3这样的机型在视觉文本到视频的合成方面表现出色,但Foley在集成音频效果生成和整体声音真实感方面具有显著优势。

