 OpenAI - ChatGPT、Sora
OpenAI - ChatGPT、Sora Google - Gemini,Nano Banana
Google - Gemini,Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok DeepSeek
DeepSeek 阿里巴巴 - Qwen
阿里巴巴 - Qwen 字节跳动 - 豆包
字节跳动 - 豆包 所有型号
所有型号 企业API定制计划
企业API定制计划 AI应用开发服务
AI应用开发服务 AI智能翻译API
AI智能翻译API AI SEO/GEO 服务
AI SEO/GEO 服务 GEO/AI大模型优化
GEO/AI大模型优化 网络爬虫服务
网络爬虫服务 OpenClaw
OpenClaw 顶级人工智能工具
顶级人工智能工具 顶级人工智能机器人
顶级人工智能机器人
 登录
登录



const axios = require('axios').default;
const api = axios.create({
baseURL: 'https://api.ai.cc/v1',
headers: { Authorization: 'Bearer ' },
});
const main = async () => {
const response = await api.post('/tts', {
model: 'inworld/tts-1',
text: 'OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.',
voice: 'coral',
});
console.log('Audio URL:', response.data.audio.url);
console.log('Characters:', response.data.usage.characters);
};
main();
import requests
def main():
url = "https://api.ai.cc/v1/tts"
headers = {
"Authorization": "Bearer ",
}
payload = {
"model": "inworld/tts-1",
"text": "OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.",
"voice": "coral"
}
response = requests.post(url, headers=headers, json=payload)
data = response.json()
print("Audio URL:", data["audio"]["url"])
print("Characters:", data["usage"]["characters"])
main()


产品详情
✨ Inworld TTS-1 API:高级实时语音合成
这 Inworld TTS-1 该模型代表了一种尖端的、基于Transformer的自回归文本转语音(TTS)解决方案,专为生成语音而设计。 高质量、实时多语言语音它提供音频 极低的延迟 它拥有卓越的 48 kHz 分辨率。此外,它还集成了先进的功能,用于…… 精细的情绪控制使其既适用于设备端应用,也适用于云端应用。
⚙️ 技术规格
- • 建筑学: 基于Transformer的自回归模型
- • 参数数量: 16亿(TTS-1)
- • 采样率: 最高支持 48 kHz 高分辨率音频
- • 延迟: 针对以下方面进行了优化 低延迟实时应用
- • 语言: 支持 11种语言 具备强大的多语言能力
- • 情绪控制: 高级精细表现力
🌟 主要特点
- • 高保真音频: 采用超分辨率技术,可实现 48 kHz 语音生成,带来水晶般清晰的音频。
- • 细致入微的情绪控制: 允许进行精细的情感和韵律调整,从而实现高度细致的语音输出。
- • 始终如一的多语言质量: 确保所有 11 种支持的语言都能获得一致、高质量的语音。
- • 高效部署: 优化的架构,可无缝集成到云端和边缘(设备端)环境中。
- • 稳健训练: 基于超过 30 万小时的英语和中文语音的庞大训练数据集,增强了自然性和鲁棒性。
🚀 性能和视觉基准测试
Inworld TTS-1 的性能始终优于许多竞争型号,尤其是在以下方面: 多语言语音质量、情感范围和超低延迟使其成为高要求实时应用领域的领导者。
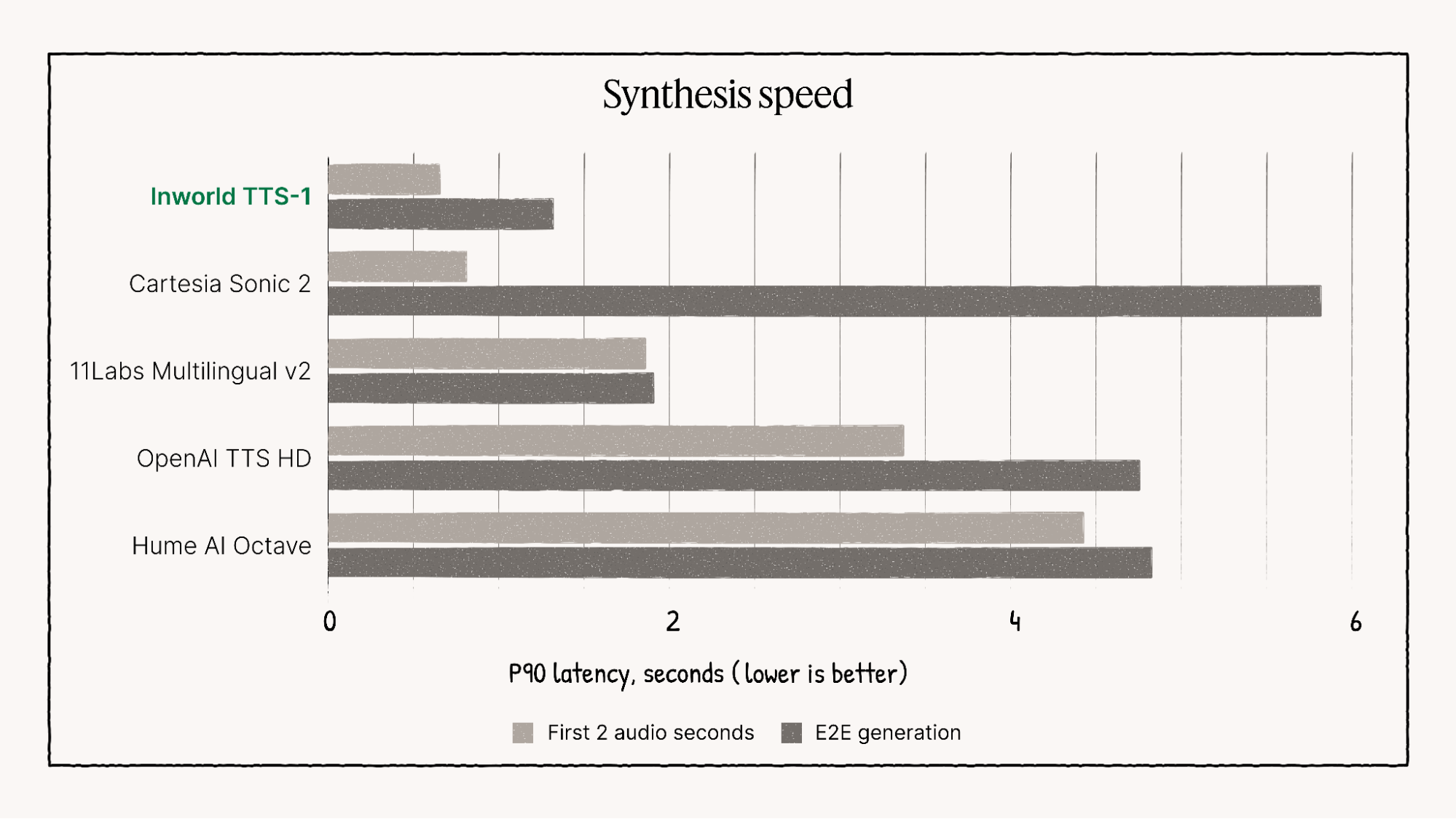
Inworld TTS-1性能特征的可视化表示。
💲 API 定价
5.25美元 每百万字符
(大约 0.00525美元 每分钟生成的语音)
💡 多种应用场景
- • 实时语音助手和对话式人工智能: 非常适合需要自然、低延迟语音以实现无缝交互的应用。
- • 多媒体内容创作: 使用高质量的多语言配音来增强有声读物、播客和视频旁白。
- • 交互式语音应答(IVR)系统: 在交互式语音应答系统中融入情感元素,可以显著提高用户参与度。
- • 设备端TTS应用: 在资源有限的移动和嵌入式系统上高效部署高质量语音合成。
- • 教育和辅助工具: 提供高质量的多语言语音合成,以丰富学习和无障碍体验。
🆚 Inworld TTS-1 对阵主要竞争对手
对比 Google WaveNet: Inworld TTS-1 的优势在于 更低的延迟和更优异的实时合成这使其成为交互式应用的理想选择。WaveNet 提供高度自然且富有表现力的语音,但通常计算成本较高。
与 11LABS 多语言版 V2 相比: Inworld TTS-1 提供 更细腻的情感表达和更低的延迟 对于实时互动场景,虽然 11LABS 提供强大的多语言功能和更简洁的界面,但 Inworld TTS-1 是实现高质量、富有表现力的输出效果的首选。
与 OpenAI TTS-1-HD 相比: OpenAI TTS-1-HD 提供超高清、录音棚品质的音频,具有卓越的保真度,在音频丰富度方面通常超越 Inworld。然而,这是以牺牲……为代价的。 更高的延迟和成本Inworld TTS-1 为多语言和设备灵活部署提供了一种更具成本效益和多功能的解决方案,非常适合日常实时需求。
❓ 常见问题解答 (FAQ)
Inworld TTS-1 是一款基于 Transformer 的先进自回归文本转语音模型,专为高质量、实时语音合成而设计。它具有 48 kHz 的低延迟音频,支持精细的情感控制,并针对云端和设备端的多语言应用进行了优化。
主要规格包括16亿参数架构、高达48 kHz的高分辨率音频以及对11种语言的支持。其核心功能包括高保真语音生成、细致入微的情感和韵律控制、高效的云/边缘部署以及基于超过30万小时训练数据集的稳健性。
与 Google WaveNet 相比,Inworld TTS-1 具有更低的延迟和更优异的实时性能;与 11LABS Multilingual V2 相比,它具有更精细的情感细微差别和更低的实时交互延迟;与 OpenAI TTS-1-HD 相比,它具有更高的成本效益和设备灵活性,而 OpenAI TTS-1-HD 则优先考虑超高清,但成本和延迟更高。
主要应用场景包括实时语音助手、多媒体内容创作、情感智能交互式语音应答系统、设备端文本转语音(TTS)以及多语言教育/辅助工具。该API的定价为每百万字符5.25美元,相当于每分钟语音约0.00525美元。

