 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banane
Google - Gemini, Nano Banane Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance – Das Beste von ByteDance
ByteDance – Das Beste von ByteDance Alle Modelle
Alle Modelle Unternehmenspläne
Unternehmenspläne KI-Anwendungsentwicklung
KI-Anwendungsentwicklung KI-Übersetzer-API
KI-Übersetzer-API KI-SEO/GEO-Dienst
KI-SEO/GEO-Dienst Geooptimierter PR-Service
Geooptimierter PR-Service Web-Scraping-Dienst
Web-Scraping-Dienst OpenClaw
OpenClaw Die besten KI-Tools
Die besten KI-Tools Top-KI-Roboter
Top-KI-Roboter
 Einloggen
Einloggen












Gemma 4 Tutorial: Vollständiger Leitfaden zur Integration von Googles leistungsstärkstem Open-Source-Multimodal-KI-Modell + API-Integration im Jahr 2026

Gemma 4: Vollständiger Leitfaden zu Googles leistungsstärkster App Open-Source Multimodale KI
Google DeepMind hat gerade veröffentlicht Gemma 4 — die bisher leistungsfähigste, wirklich quelloffene multimodale Modellfamilie. Veröffentlicht am 2. April 2026 unter einer vollständig permissiven Lizenz. Apache-2.0-LizenzGemma 4 bringt Spitzenleistung (basierend auf derselben Forschung wie Gemini 3) auf Laptops, Smartphones, Raspberry Pi und High-End-GPUs. Dieses praxisorientierte Tutorial deckt alles ab: Modellvarianten, Benchmarks, echten Code und API-Integration.
Modellvarianten: Jedes Einsatzszenario
Die Gemma 4-Familie umfasst vier optimierte Größen. Alle Modelle unterstützen multimodale Eingaben und zeichnen sich durch ihre Eignung für agentenbasierte Arbeitsabläufe, native Funktionsaufrufe, strukturierte JSON-Ausgabe und kontextbezogenes Schließen aus.
| Modellvariante | Parameter | Zielhardware | Kontextfenster | Wichtigste Stärken |
|---|---|---|---|---|
| Gemma 4 E2B | ~2 Milliarden | Mobile-/Edge-Geräte | 128K | Extrem niedrige Latenz, auf dem Gerät |
| Edelstein 4 E4B | ~4 Milliarden | Smartphones / Raspberry Pi | 128K | Multimodal + natives Audio |
| Gemma 4 26B A4B | 26B (MoE) | Workstations / GPUs | 256K | Ausgewogene Geschwindigkeit + Qualität |
| Gemma 4 31B | 31B | High-End-Server | 256K | Maximale Denkfähigkeit |
// Multimodale KI-Architektur: Gemma 4 verarbeitet Text-, Bild-, Audio- und Videoeingaben nahtlos
Warum Gemma 4 heraussticht: Benchmarks
(Modell 31B)
Diamant
Bank
Mehrsprachig
- Multimodal-nativ: Bilder, Audioclips und Videos zusammen mit Text in einem einzigen Modell verstehen.
- Agenten- und Werkzeugnutzung: Integrierte Funktionsaufrufe und Tool-Integration – perfekt für autonome Agenten.
- Leistung auf dem Gerät: Läuft offline mit nahezu null Latenz auf Consumer-Hardware.
- Langer Kontext: Bis zu 256.000 Tokens für umfangreiche Dokumente oder ganze Codebasen.
- Kommerzielle Freiheit: Die Apache 2.0-Lizenz beseitigt alle bisherigen Einschränkungen – Einsatz überall möglich.
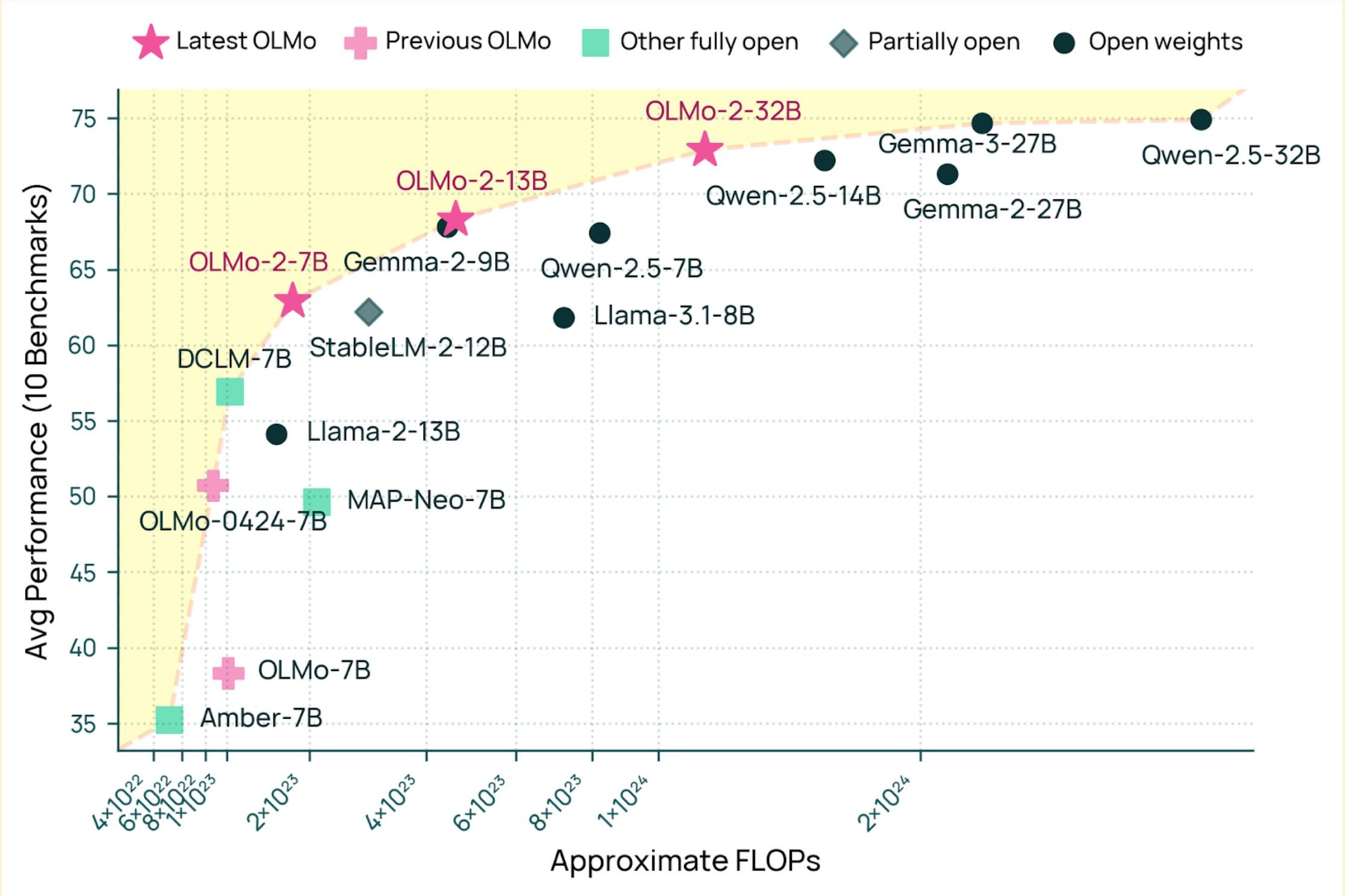
// Gemma 4-Leistung im Vergleich zu anderen offenen Modellen — FLOPs im Vergleich zum Benchmark-Durchschnitt
Praktisches Tutorial zur API-Integration (Python)
Es gibt zwei Hauptwege: gehostete Gemini-API (am einfachsten, empfohlen für Prototypen) oder lokale Bereitstellung Für vollständige Privatsphäre bitte über Hugging Face / Ollama kontaktieren.
Option 1 — Gemini API Schnellstart
from google import genai # Holen Sie sich Ihren kostenlosen API-Schlüssel unter ai.google.dev client = genai.Client(api_key="YOUR_GEMINI_API_KEY") response = client.models.generate_content( model="gemma-4-31b-it", # oder gemma-4-26b-a4b-it usw. contents=[ "Analysiere dieses Bild und erkläre das Diagramm im Detail.", # Sie können hier auch Bildbytes oder URLs übergeben ] ) print(response.text)
Multimodales Beispiel – Bild + Text
response = client.models.generate_content( model="gemma-4-e4b-it", contents=["Was passiert auf diesem Foto?", genai.types.Part.from_image( genai.types.Image.from_bytes(image_bytes) )] )
Option 2 – Lokaler Einsatz durch Hugging Face
from transformers import AutoModelForCausalLM, AutoProcessor import torch model_id = "google/gemma-4-31B-it" # oder kleinere Varianten processor = AutoProcessor.from_pretrained(model_id) model = AutoModelForCausalLM.from_pretrained( model_id, torch_dtype=torch.bfloat16, device_map="auto" ) # Beispiel für multimodale Eingabeaufforderung messages = [ {"role": "user", "content": [ {"type": "image", "image": "https://example.com/chart.png"}, {"type": "text", "text": "Beschreiben Sie die Trends in dieser Datenvisualisierung."} ]} ] inputs = processor.apply_chat_template( messages, add_generation_prompt=True, tokenize=True, return_tensors="pt" ).to(model.device) outputs = model.generate(**inputs, max_new_tokens=512) print(processor.decode(outputs[0])) 
// Google AI Studio – der schnellste Weg, mit Gemma 4 Prototypen zu erstellen
Häufige Anwendungsfälle und Beispiele aus der Praxis
Natives Tool, das Web-Scraping, Datenanalyse oder komplexe, mehrstufige Automatisierungs-Workflows erfordert.
Bildanalyse + Sprache + Text in einem einheitlichen Modell – kein Zusammenfügen erforderlich.
Führen Sie leistungsstarke 2B- bis 4B-Modelle direkt auf mobilen Geräten oder IoT-Hardware aus, vollständig offline.
Das 256K Kontextfenster bewältigt riesige Wissensdatenbanken, ganze Codebasen und juristische Dokumente.
Häufig gestellte Fragen
Ja – vollständige Apache-2.0-Lizenz mit offenen Gewichtungen und uneingeschränkter kommerzieller Nutzung. Keine Einschränkungen.
Absolut. Edge-Varianten (2B/4B) laufen auf Smartphones; größere Varianten auf einer einzelnen GPU mit Quantisierung (4-Bit/8-Bit).
Gemma 4 bietet ähnliche Spitzentechnologien, jedoch mit vollständiger Offenheit und Fokus auf geräteinterne Optimierung.
Gemma 4 und über 100 Topmodelle integrieren – ein SDK
Die Verwaltung mehrerer Modelle, API-Schlüssel, Ratenbegrenzungen und Bereitstellungen ist zeitaufwändig. www.ai.cc bietet Ihnen mit nur einem Klick Zugriff auf Gemma 4, Claude, GPT, Grok, Veo und Dutzende weitere Tools über ein einziges, einfaches SDK.