 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'deepseek/deepseek-non-reasoner-v3.1-terminus',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="deepseek/deepseek-non-reasoner-v3.1-terminus",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Product Detail
✨ DeepSeek V3.1 Terminus (Non-Reasoning Mode): High-Speed, Efficient AI for Direct Tasks
The DeepSeek V3.1 Terminus model, specifically in its non-reasoning mode, stands as an advanced large language model meticulously engineered for rapid, efficient, and lightweight generation tasks. It's designed to excel where deep analytical reasoning isn't required, making it perfect for straightforward content generation. As part of the DeepSeek V3.1 series, it delivers substantial enhancements in stability, multilingual consistency, and tool use reliability, making it an optimal choice for agent workflows that demand speed and low resource consumption.
⚙️ Technical Specifications
- • Model Family: DeepSeek V3.1 Terminus (Non-Reasoning Mode)
- • Parameters: 671 billion total, 37 billion active in inference
- • Architecture: Hybrid LLM with dual-mode inference (thinking & non-thinking)
- • Context Window: Supports up to 128,000 tokens long-context training
- • Precision & Efficiency: Utilizes FP8 microscaling for memory and inference efficiency
- • Modes: Non-reasoning mode disables elaborate chain-of-thought for faster responses
- • Language Support: Improved multilingual consistency, particularly in English and Chinese
📊 Performance Benchmarks
- • Reasoning (MMLU-Pro): 85.0 (slight improvement)
- • Agentic Web Navigation (BrowseComp): 38.5 (significant multi-step tool use gains)
- • Command Line (Terminal-bench): 36.7 (better command sequence handling)
- • Code Generation (LiveCodeBench): 74.9 (high capabilities maintained)
- • Software Engineering Verification (SWE Verified): 68.4 (improved validation accuracy)
- • QA Accuracy (SimpleQA): 96.8 (robust performance)
- • Overall Stability: Reduced variance and more deterministic outputs for enhanced real-world reliability.
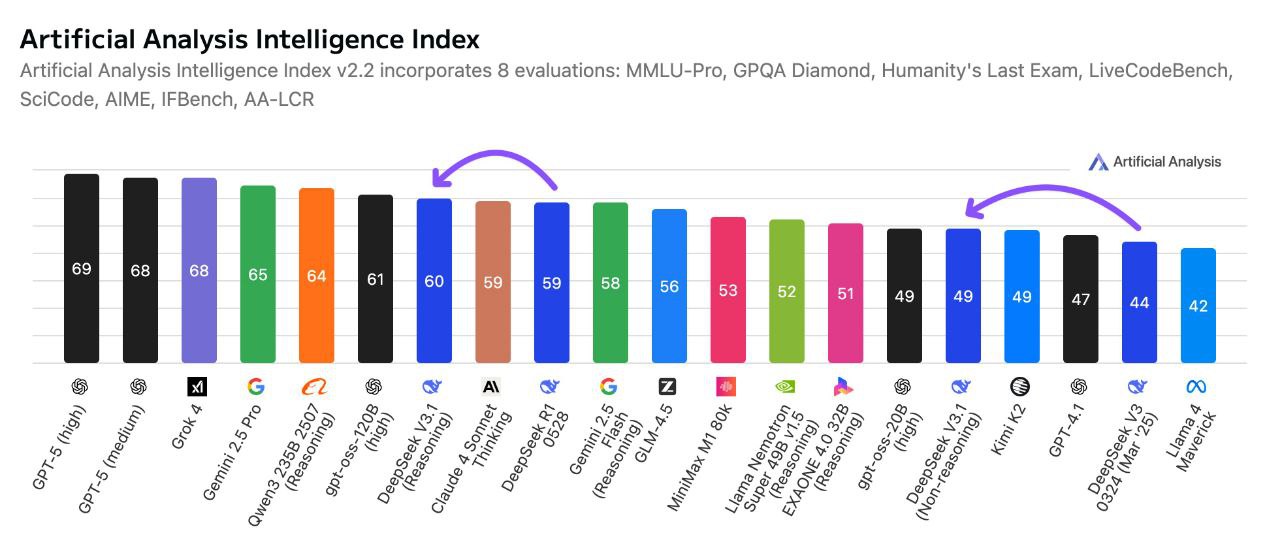
Performance Benchmarks: DeepSeek V3.1 Terminus in Action
⭐ Key Features
- 🚀 Fast & Lightweight Generation: Prioritized non-thinking mode ensures reduced processing time and resource consumption, ideal for quick outputs.
- 🌐 Robust Multilingual Output: Enhancements prevent language mixing and inconsistent tokens, supporting global applications.
- 🛠️ Improved Tool Use: Bolsters reliability in tool invocation workflows, including code execution and web search chains.
- 📖 Flexible Long-Context: Supports massive contexts up to 128K tokens for extensive input histories.
- ✅ Stable & Consistent Outputs: Post-training optimizations significantly reduce hallucinations and tokenization artifacts.
- 🔄 Backward Compatible: Integrates seamlessly into existing DeepSeek API ecosystems without disruptive changes.
- ⚡ Scalable Hybrid Inference: Balances large-scale model capacity with efficient active parameter deployment.
💰 API Pricing
- • 1 Million Input Tokens: $0.294
- • 1 Million Output Tokens: $0.441
💡 Practical Use Cases
- 💬 Fast Customer Support: Quick and efficient chatbot responses.
- ✍️ Multilingual Content Generation: Marketing copy, summaries, and more across languages.
- 👨💻 Automated Coding Assistance: Script execution and basic code generation.
- 📚 Knowledge Base Querying: Efficient search and retrieval within long documents.
- ⚙️ Tool-Assisted Task Automation: Streamlined workflows with reliable tool invocation.
- 📄 Quick Document Summarization: Rapid overviews without deep analytical explanations.
💻 Code Sample
<snippet data-name="open-ai.chat-completion" data-model="deepseek/deepseek-non-reasoner-v3.1-terminus"></snippet>🤝 Comparison with Other Leading Models
DeepSeek V3.1 Terminus vs. GPT-4: DeepSeek V3.1 Terminus offers a significantly larger context window (up to 128K tokens) compared to GPT-4's 32K tokens, making it superior for extensive documents and research. It's optimized for faster generation in its specialized non-reasoning mode, while GPT-4 prioritizes detailed reasoning with higher latency.
DeepSeek V3.1 Terminus vs. GPT-5: While GPT-5 excels in multimodal tasks and broader ecosystem integration with an even larger context, DeepSeek V3.1 Terminus emphasizes cost-efficiency and open-weight licensing, appealing to developers and startups focused on infrastructure capabilities.
DeepSeek V3.1 Terminus vs. Claude 4.5: Claude 4.5 prioritizes safety, alignment, and strong reasoning with robust constitutional AI. DeepSeek V3.1 Terminus focuses on lightweight, rapid output. Claude often has higher per-task pricing, favored in regulated industries, whereas DeepSeek offers open licensing and accessibility for rapid prototyping.
DeepSeek V3.1 Terminus vs. OpenAI GPT-4.5: GPT-4.5 improves reasoning and creative writing but shares a similar 128K token context window with DeepSeek. DeepSeek V3.1 Terminus achieves faster response times in its non-reasoning mode, making it ideal for speed-critical applications without complex chain-of-thought. GPT-4.5 boasts stronger creative generation and ecosystem integration, while DeepSeek excels in scalability and cost efficiency.
❓ Frequently Asked Questions (FAQ)
Q: What does 'Non-Reasoning' mean for DeepSeek V3.1 Terminus?
A: 'Non-Reasoning' signifies that this model is optimized for tasks that do not demand complex logical deduction, multi-step problem-solving, or deep analytical thought. It prioritizes direct text generation, simple Q&A, and straightforward processing with maximum efficiency and speed.
Q: What are the primary advantages of using the Non-Reasoning variant?
A: Key advantages include significantly faster response times, lower computational costs, higher throughput, efficient resource usage, and optimized performance for simple tasks where the full reasoning capabilities of standard models are not necessary.
Q: What is the context window size for DeepSeek V3.1 Terminus Non-Reasoning?
A: DeepSeek V3.1 Terminus Non-Reasoning features an impressive 128K token context window, enabling it to process extensive documents and maintain context effectively for simple text generation and processing tasks.
Q: What types of tasks is this model best suited for?
A: It is ideal for simple text generation, basic Q&A, content summarization, text classification, straightforward translations, template filling, data extraction, and any application requiring fast, reliable text processing without complex reasoning.
Q: How does its speed compare to standard reasoning models?
A: The Non-Reasoning variant typically responds 2-4 times faster than standard reasoning models for simple tasks, offering significantly lower latency and higher throughput for high-volume text processing applications.
AI Playground

