 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropique - Claude
Anthropique - Claude xAI - Grok
xAI - Grok Recherche profonde
Recherche profonde Alibaba - Qwen
Alibaba - Qwen ByteDance - Le meilleur de ByteDance
ByteDance - Le meilleur de ByteDance Tous les modèles
Tous les modèles Plans d'entreprise
Plans d'entreprise Développement d'applications d'IA
Développement d'applications d'IA API de traduction IA
API de traduction IA Service SEO/GEO IA
Service SEO/GEO IA Service de relations publiques géo-optimisé
Service de relations publiques géo-optimisé Service de web scraping
Service de web scraping OpenClaw
OpenClaw Meilleurs outils d'IA
Meilleurs outils d'IA Les meilleurs robots IA
Les meilleurs robots IA
 Se connecter
Se connecter













Comparaison des API IA 2026 : OpenAI contre Anthropic Claude contre Google Gemini contre Grok

Comparaison des API d'IA en 2026 :
OpenAI contre Claude
contre Gemini contre Grok
En mars 2026, le paysage des API d'IA n'a jamais été aussi concurrentiel — ni aussi complexe. Grok 4.1 : Des records de prix battus à une vitesse fulgurante, Gemini 3.1 Pro domine le raisonnement à long contexte, et Claude Opus 4.6, leader en programmation et en écritureChoisir la bonne API LLM peut avoir un impact considérable sur le budget de votre projet. Ce guide détaille les prix, les points forts, les atouts et le code d'intégration des quatre principales API.
%252520Top%252520Large%252520Language%252520Models_%252520A%252520Comparative%252520Analysis.png)
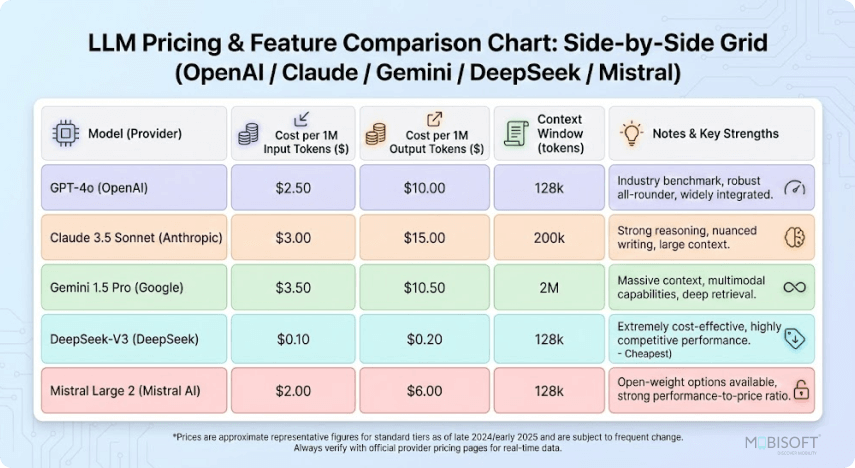
// Comparaison des prix et des fonctionnalités des API LLM modernes — aperçu visuel des structures de coûts des principaux fournisseurs (2026)
Tarification des API d'IA en 2026 (par million de jetons)
Les prix ont considérablement convergé, mais d'importants écarts subsistent, notamment à grande échelle. Dernières données : mars 2026.
| Fournisseur | Modèle | Entrée ($/1M) | Sortie ($/1M) | Fenêtre contextuelle | Idéal pour | Réduction en cache |
|---|---|---|---|---|---|---|
| OpenAI | GPT-5.4 (phare) | 2,50 $ | 15,00 $ | Plus de 400 000 | Entreprise équilibrée | Jusqu'à 90% |
| OpenAI | GPT-5.4-mini | 0,75 $ | 4,50 $ | 400K | Codage et agents | Jusqu'à 90% |
| Anthropique | Claude Opus 4.6 | 5,00 $ | 25,00 $ | 200K (1M bêta) | Raisonnement et écriture approfondis | Mise en cache puissante |
| Anthropique | Claude Sonnet 4.6 | 3,00 $ | 15,00 $ | 200K (1M bêta) | Point culminant le plus populaire | Mise en cache puissante |
| Gemini 3.1 Pro | 2,00 $ | 12,00 $ | 2M | Multimodal et contexte long | Excellent | |
| Gemini 3 Flash | 0,50 $ | 3,00 $ | Plus d'un million | Vitesse à volume élevé | Excellent | |
| xAI Grok | Grok 4.1 Rapide | 0,20 $ | 0,50 $ | 2M | Sensible aux coûts et codage | Compétitif |
| xAI Grok | Grok 4 | 3,00 $ | 15,00 $ | 256K–2M | En temps réel et sans censure | Compétitif |
Point clé à retenir : Grok 4.1 Fast est incontestablement l'option la plus économique pour les environnements multimodaux en 2026. Claude Opus 4.6 reste haut de gamme, mais offre une profondeur inégalée. Gemini propose le meilleur rapport qualité-prix pour les environnements multimodaux.

// Gemini vs GPT vs Claude vs Grok — Comparaison des capacités des modèles d'IA (2026)
Indicateurs de performance — Mars 2026
Aucun modèle n'est parfait. Voici comment ils se comparent selon les principaux tests comparatifs indépendants :
| Référence | Gemini 3.1 Pro | Claude Opus 4.6 | GPT-5.4 | Grok 4.1 Rapide | Gagnant |
|---|---|---|---|---|---|
| Diamant GPQA (niveau doctorat) | 94,3% | 91,3% | 92,8% | ~88% | Gémeaux |
| ARC-AGI-2 (raisonnement novateur) | 77,1% | 68,8% | ~70% | ~16% | Gémeaux |
| SWE-Bench (codage) | 80,6% | 80,8% | 74,9% | ~75% | Claude |
| LiveCodeBench (codage) | Fort | Chef | Fort | Fort | Claude |
| Multimodal (vision/vidéo) | chef autochtone | Bien | Fort | Priorité au texte | Gémeaux |
| En temps réel / Non censuré | Bien | Conservateur | Bien | Chef | Grok |
& en écrivant
contexte massif
production
codage/agents
Avantages, inconvénients et cas d'utilisation optimaux


Exemples de code d'intégration — Python 2026
Exemples minimaux prêts pour la production utilisant les SDK officiels. Tous peuvent être remplacés en moins de 5 minutes sur une plateforme unifiée.
from openai import OpenAI client = OpenAI(api_key="votre-clé-openai") response = client.chat.completions.create( model="gpt-5.4", messages=[{"role": "utilisateur", "content": "Expliquez l'informatique quantique en un paragraphe"}], temperature=0.7 ) print(response.choices[0].message.content) 
// Tableau de bord de codage IA illustrant le flux de travail de développement assisté par LLM
from anthropic import Anthropic client = Anthropic(api_key="votre-clé-anthropique") response = client.messages.create( model="claude-4.6-sonnet", max_tokens=1024, messages=[{"role": "utilisateur", "content": "Rédigez un e-mail professionnel..."}] ) print(response.content[0].text) import google.generativeai as genai genai.configure(api_key="votre-clé-gemini") model = genai.GenerativeModel("gemini-3.1-pro") response = model.generate_content("Analyser cette image et résumer les tendances", stream=False) print(response.text) from xai import Grok # SDK officiel client = Grok(api_key="votre-clé-grok") response = client.chat.completions.create( model="grok-4.1-fast", messages=[{"role": "utilisateur", "content": "Dernières tendances X sur les agents IA"}], temperature=0.8 ) print(response.choices[0].message.content) Pour un conseil : Utilisez LangChain ou LlamaIndex pour les abstraire complètement, puis changez de modèle en une seule ligne de code.
Conseils d'optimisation des coûts pour 2026
- Utiliser mise en cache — les quatre fournisseurs le soutiennent désormais massivement, avec des économies pouvant atteindre 90 % sur le contexte répété.
- Confiez les tâches simples à des modèles moins chers : Grok 4.1 Rapide ou Éclair des Gémeaux pour les demandes en grand volume.
- Utiliser API par lots Là où c'est possible — plus de 50 % d'économies sur les charges de travail non temps réel.
- Surveillez l'utilisation des jetons en temps réel — de petites modifications techniques rapides peuvent réduire les coûts de 30 à 70 %.

// Felix — Tableau de bord de développement IA multi-backend pour le suivi des dépenses et du routage entre les fournisseurs LLM
Arrêtez de jongler avec les API.
Commencez à construire plus rapidement.
Gérer quatre SDK différents, des clés, des limites de débit et des tableaux de bord de facturation est fastidieux. Les équipes performantes centralisent leurs ressources sur une plateforme unique avec une seule clé, un seul tableau de bord et un accès instantané à tous les principaux modèles.