 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropique - Claude
Anthropique - Claude xAI - Grok
xAI - Grok Recherche profonde
Recherche profonde Alibaba - Qwen
Alibaba - Qwen ByteDance - Le meilleur de ByteDance
ByteDance - Le meilleur de ByteDance Tous les modèles
Tous les modèles Plans d'entreprise
Plans d'entreprise Développement d'applications d'IA
Développement d'applications d'IA API de traduction IA
API de traduction IA Service SEO/GEO IA
Service SEO/GEO IA Service de relations publiques géo-optimisé
Service de relations publiques géo-optimisé Service de web scraping
Service de web scraping OpenClaw
OpenClaw Meilleurs outils d'IA
Meilleurs outils d'IA Les meilleurs robots IA
Les meilleurs robots IA
 Se connecter
Se connecter



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'deepseek/deepseek-non-reasoner-v3.1-terminus',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="deepseek/deepseek-non-reasoner-v3.1-terminus",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Détails du produit
✨ DeepSeek V3.1 Terminus (Mode sans raisonnement) : IA haute vitesse et efficace pour les tâches directes
Le Terminus DeepSeek V3.1 modèle, en particulier dans son mode non raisonnantDeepSeek est un modèle de langage avancé et performant, conçu avec précision pour des tâches de génération rapides, efficaces et légères. Il excelle là où un raisonnement analytique poussé n'est pas nécessaire, ce qui le rend idéal pour la génération de contenu simple. Intégré à la série DeepSeek V3.1, il offre des améliorations significatives en termes de stabilité, de cohérence multilingue et de fiabilité d'utilisation, ce qui en fait un choix optimal pour les flux de travail d'agents exigeant rapidité et faible consommation de ressources.
⚙️ Spécifications techniques
- • Modèles de la famille : Terminus DeepSeek V3.1 (Mode sans raisonnement)
- • Paramètres : 671 milliards au total, 37 milliards d'actifs en inférence
- • Architecture: Modèle linéaire hybride avec inférence à double mode (pensée et non-pensée)
- • Fenêtre contextuelle : Supporte jusqu'à 128 000 jetons formation en contexte long
- • Précision et efficacité : Utilise Micro-mise à l'échelle FP8 pour l'efficacité de la mémoire et de l'inférence
- • Modes : Le mode non-raisonnement désactive les raisonnements complexes pour des réponses plus rapides
- • Assistance linguistique : Amélioration de la cohérence multilingue, notamment dans Anglais et chinois
📊 Indicateurs de performance
- • Raisonnement (MMLU-Pro) : 85,0 (légère amélioration)
- • Navigation Web Agentic (BrowseComp) : 38,5 (gains significatifs grâce à l'utilisation d'outils en plusieurs étapes)
- • Ligne de commande (Terminal-bench) : 36,7 (meilleure gestion des séquences de commandes)
- • Génération de code (LiveCodeBench) : 74,9 (capacités élevées maintenues)
- • Vérification en génie logiciel (SWE Verified) : 68,4 (précision de validation améliorée)
- • Précision de l'assurance qualité (SimpleQA) : 96,8 (performance robuste)
- • Stabilité globale : Variance réduite et résultats plus déterministes pour une fiabilité accrue dans le monde réel.
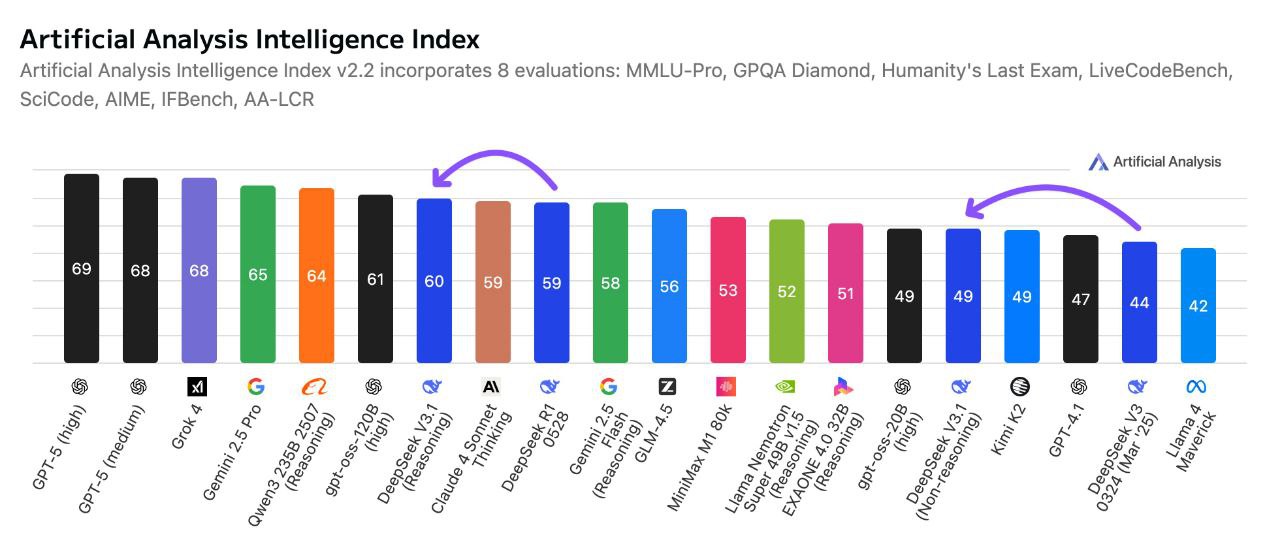
Tests de performance : DeepSeek V3.1 Terminus en action
⭐ Fonctionnalités clés
- 🚀 Génération rapide et légère : Le mode non-pensée prioritaire garantit réduction du temps de traitement et de la consommation de ressources, idéal pour des productions rapides.
- 🌐 Sortie multilingue robuste : Les améliorations empêchent le mélange des langues et les jetons incohérents, prenant en charge applications globales.
- 🛠️ Amélioration de l'utilisation des outils : Renforce la fiabilité des flux de travail d'invocation d'outils, notamment chaînes d'exécution de code et de recherche Web.
- 📖 Contexte long flexible : Prend en charge des contextes massifs jusqu'à 128 000 jetons pour des historiques de saisie détaillés.
- ✅ Résultats stables et cohérents : Les optimisations post-entraînement réduisent considérablement les hallucinations et les artefacts de tokenisation.
- 🔄 Rétrocompatible : S'intègre parfaitement aux écosystèmes d'API DeepSeek existants sans modifications perturbatrices.
- ⚡ Inférence hybride évolutive : Concilie la capacité des modèles à grande échelle et le déploiement efficace des paramètres actifs.
💰 Tarification de l'API
- • 1 million de jetons d'entrée : 0,294 $
- • 1 million de jetons de production : 0,441 $
💡 Cas d'utilisation pratiques
- 💬 Assistance clientèle rapide : Réponses rapides et efficaces du chatbot.
- ✍️ Génération de contenu multilingue : Textes marketing, résumés et bien plus encore, dans différentes langues.
- 👨💻 Assistance au codage automatisé : Exécution de scripts et génération de code de base.
- 📚 Interrogation de la base de connaissances : Recherche et extraction efficaces au sein de documents longs.
- ⚙️ Automatisation des tâches assistée par des outils : Flux de travail rationalisés grâce à une invocation fiable des outils.
- 📄 Résumé rapide du document : Aperçus rapides sans explications analytiques approfondies.
💻 Exemple de code
🤝 Comparaison avec d'autres modèles leaders
Terminus DeepSeek V3.1 vs. GPT-4: DeepSeek V3.1 Terminus offre une fenêtre de contexte nettement plus large (jusqu'à 128 000 jetons) par rapport aux 32 000 jetons de GPT-4, ce qui le rend supérieur pour les documents volumineux et la recherche. Il est optimisé pour génération plus rapide dans son mode spécialisé de non-raisonnement, tandis que GPT-4 privilégie un raisonnement détaillé avec une latence plus élevée.
Terminus DeepSeek V3.1 vs. GPT-5: Alors que GPT-5 excelle dans les tâches multimodales et l'intégration plus large à l'écosystème dans un contexte encore plus vaste, DeepSeek V3.1 Terminus met l'accent sur rentabilité et licences à poids libre, séduisant les développeurs et les startups axées sur les capacités d'infrastructure.
Terminus DeepSeek V3.1 vs. Claude 4.5: Claude 4.5 privilégie la sécurité, l'alignement et un raisonnement rigoureux grâce à une IA constitutionnelle robuste. DeepSeek V3.1 Terminus se concentre sur léger, sortie rapideClaude pratique souvent des tarifs plus élevés par tâche, plébiscités dans les secteurs réglementés, tandis que DeepSeek propose licences ouvertes et accessibilité pour le prototypage rapide.
Terminus DeepSeek V3.1 vs. OpenAI GPT-4.5: GPT-4.5 améliore le raisonnement et l'écriture créative, mais partage une fenêtre de contexte de 128 000 jetons similaire à celle de DeepSeek. DeepSeek V3.1 Terminus atteint temps de réponse plus rapides En mode non raisonné, il est idéal pour les applications critiques en termes de vitesse, sans raisonnement complexe. GPT-4.5 se distingue par une génération créative plus performante et une meilleure intégration à l'écosystème, tandis que DeepSeek excelle dans… évolutivité et rentabilité.
❓ Foire aux questions (FAQ)
Q : Que signifie « Non-raisonnement » pour DeepSeek V3.1 Terminus ?
A : « Non-raisonnement » signifie que ce modèle est optimisé pour les tâches ne nécessitant ni déduction logique complexe, ni résolution de problèmes en plusieurs étapes, ni réflexion analytique approfondie. Il privilégie la génération directe de texte, les questions-réponses simples et un traitement direct, avec une efficacité et une rapidité maximales.
Q : Quels sont les principaux avantages de l'utilisation de la variante sans raisonnement ?
A : Les principaux avantages comprennent des temps de réponse nettement plus rapides, des coûts de calcul inférieurs, un débit plus élevé, une utilisation efficace des ressources et des performances optimisées pour les tâches simples où toutes les capacités de raisonnement des modèles standard ne sont pas nécessaires.
Q : Quelle est la taille de la fenêtre de contexte pour DeepSeek V3.1 Terminus Non-Reasoning ?
A: DeepSeek V3.1 Terminus Non-Reasoning offre des fonctionnalités impressionnantes Fenêtre de contexte de jeton de 128 Ko, ce qui lui permet de traiter des documents volumineux et de conserver efficacement le contexte pour des tâches simples de génération et de traitement de texte.
Q : À quels types de tâches ce modèle est-il le mieux adapté ?
A: Il est idéal pour la génération de texte simple, les questions-réponses de base, la synthèse de contenu, la classification de texte, les traductions simples, le remplissage de modèles, l'extraction de données et toute application nécessitant un traitement de texte rapide et fiable sans raisonnement complexe.
Q : Comment sa vitesse se compare-t-elle à celle des modèles de raisonnement standard ?
A : La variante non raisonnée répond généralement 2 à 4 fois plus rapide que les modèles de raisonnement standard pour les tâches simples, offrant une latence nettement inférieure et un débit supérieur pour les applications de traitement de texte à volume élevé.
Terrain de jeu de l'IA

