 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropique - Claude
Anthropique - Claude xAI - Grok
xAI - Grok Recherche profonde
Recherche profonde Alibaba - Qwen
Alibaba - Qwen ByteDance - Le meilleur de ByteDance
ByteDance - Le meilleur de ByteDance Tous les modèles
Tous les modèles Plans d'entreprise
Plans d'entreprise Développement d'applications d'IA
Développement d'applications d'IA API de traduction IA
API de traduction IA Service SEO/GEO IA
Service SEO/GEO IA Service de relations publiques géo-optimisé
Service de relations publiques géo-optimisé Service de web scraping
Service de web scraping OpenClaw
OpenClaw Meilleurs outils d'IA
Meilleurs outils d'IA Les meilleurs robots IA
Les meilleurs robots IA
 Se connecter
Se connecter



const axios = require('axios').default;
const api = axios.create({
baseURL: 'https://api.ai.cc/v1',
headers: { Authorization: 'Bearer ' },
});
const main = async () => {
const response = await api.post('/tts', {
model: 'hume/octave-2',
text: 'OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.',
voice: 'coral',
});
console.log('Audio URL:', response.data.audio.url);
console.log('Characters:', response.data.usage.characters);
};
main();
import requests
def main():
url = "https://api.ai.cc/v1/tts"
headers = {
"Authorization": "Bearer ",
}
payload = {
"model": "hume/octave-2",
"text": "OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.",
"voice": "coral"
}
response = requests.post(url, headers=headers, json=payload)
data = response.json()
print("Audio URL:", data["audio"]["url"])
print("Characters:", data["usage"]["characters"])
main()

.png)
Détails du produit
🚀 Octave 2 : Synthèse vocale nouvelle génération basée sur LLM
Octave 2 représente une avancée majeure dans le domaine de la synthèse vocale. Grâce à ses modèles de langage étendus (LLM) avancés, il va au-delà de la simple conversion de texte pour comprendre en profondeur le langage. nuances émotionnelles et sémantiques de texte. Cette intelligence permet à Octave 2 de générer une parole expressive et naturelle en temps réel, établissant ainsi une nouvelle norme en matière de qualité vocale et de réactivité pour diverses applications.
Conçu pour la polyvalence, Octave 2 offre une qualité audio de pointe avec latence ultra-faible et une prise en charge multilingue étendue, ce qui la rend idéale pour tout, de l'IA conversationnelle dynamique aux livres audio immersifs.
⚙️ Spécifications techniques
- ✓ Langues prises en charge : Anglais, japonais, coréen, espagnol, français, portugais, italien, allemand, russe, hindi, arabe
- ✓ Latence : Remarquablement bas, à environ 100 ms
- ✓ Clonage vocal : Prise en charge avec seulement ~15 secondes d'entrée audio
- ✓ Formats audio : MP3, WAV, PCM
📈 Indicateurs de performance
- 📈 Octave 2 livre Génération audio 40 % plus rapide par rapport à son prédécesseur, Octave 1, il atteint systématiquement des latences inférieures à 200 millisecondes.
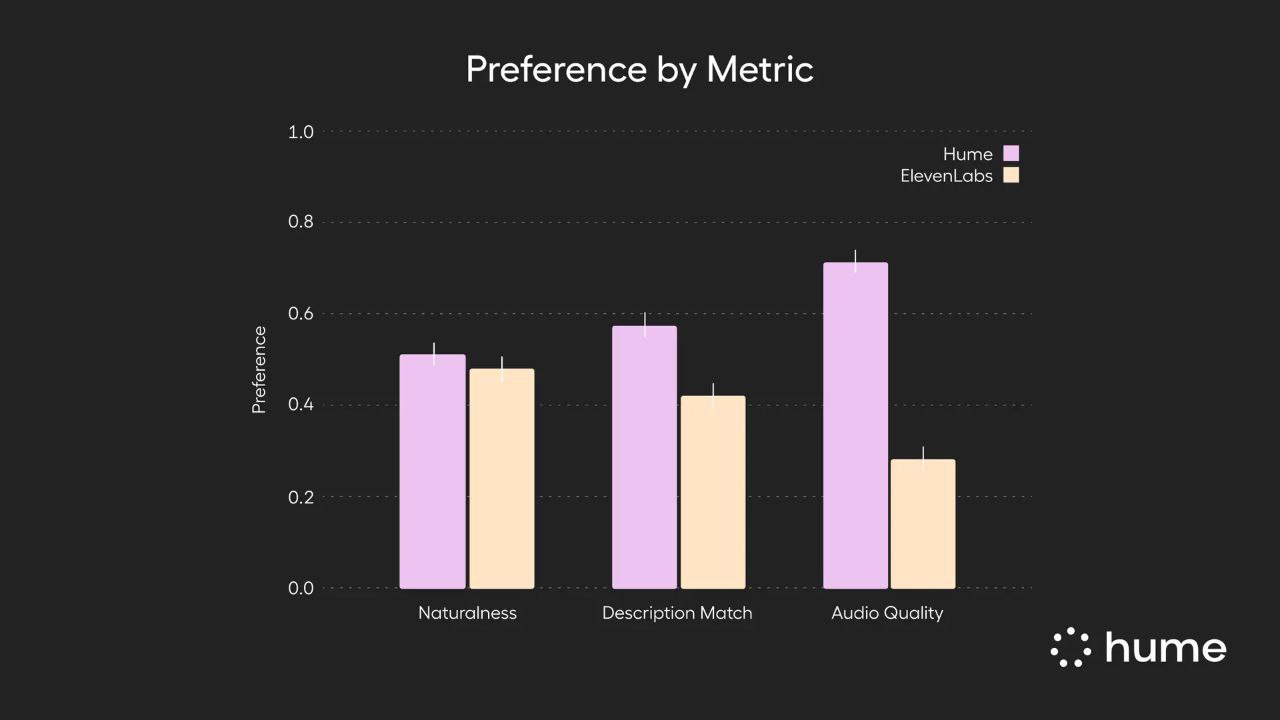
- 🎉 Lors de tests auditifs à l'aveugle menés auprès de 180 évaluateurs humains, Octave 2 a été préféré à ElevenLabs Voice Design pour qualité audio (71,6%), naturel (51,7%)et des descriptions vocales correspondantes (57,7%).
- 💬 Ce modèle excelle dans la gestion des schémas de parole complexes et des changements émotionnels subtils, améliorant considérablement le naturel et l'expressivité globale.
✨ Principales caractéristiques d'Octave 2
- 💡 Compréhension émotionnelle grâce au LLM : Contrairement à la synthèse vocale traditionnelle, Octave 2 interprète le sens et l'intention émotionnelle, en modulant la hauteur, le tempo et l'accentuation pour correspondre précisément au contexte.
- 📣 Latence ultra-faible : Bénéficiez d'une synthèse vocale en temps réel avec une latence de modèle aussi faible que ~100 millisecondes, idéale pour les applications interactives et conversationnelles.
- 🌐 Assistance multilingue : Synthèse fluide et naturelle dans 11 langues clés, dont l'anglais, le japonais, le coréen, l'espagnol, le français, le portugais, l'italien, l'allemand, le russe, l'hindi et l'arabe.
- 📚 Polyvalence des formats longs : Maintient une tonalité émotionnelle et des voix de personnages cohérentes dans les contenus longs tels que les livres audio et les podcasts, s'adaptant parfaitement aux changements de scène.
- ⚙ Fonctionnalités avancées : Inclut la conversion vocale, l'édition directe des phonèmes et une prononciation fiable pour les mots, les chiffres et les symboles peu courants.
💰 Tarification de l'API Octave 2
Tarification simple et transparente : 0,063 $ pour 1000 caractères.
🎯 Cas d'utilisation variés
- 👤 IA conversationnelle et agents interactifs : Une parole en temps réel, sensible aux émotions, pour les chatbots, les assistants virtuels et le service client.
- 🎧 Livres audio et podcasts : Narration de haute qualité et de longue durée, avec un ton émotionnel cohérent et une adaptation parfaite de la voix des personnages.
- 🎨 Clonage vocal et voix personnalisées : Création de voix personnalisées pour le branding, la production multimédia et les solutions d'accessibilité.
- 🎮 Jeux vidéo et animation : Des dialogues dynamiques entre les personnages, empreints d'expressions émotionnelles nuancées, donnent vie aux mondes virtuels.
- 📞 Systèmes de téléphonie et de SVI : Des messages et des réponses rapides et naturels pour les systèmes téléphoniques automatisés, améliorant ainsi l'expérience utilisateur.
- 💪 Outils d'accessibilité : Des lecteurs d'écran et des aides vocales améliorés, dotés d'une compréhension de la parole émotionnelle et contextuelle, pour une inclusion plus large.
🆚 Octave 2 contre les principaux modèles TTS
Découvrez en quoi Octave 2 se distingue des autres solutions de synthèse vocale importantes :
contre ElevenLabs : Octave 2 exploite l'intelligence LLM pour une compréhension émotionnelle et sémantique plus fine, produisant une parole plus nuancée avec une latence quasi instantanée (environ 100 ms). Si ElevenLabs offre des voix naturelles et expressives, il lui manque généralement la compréhension sémantique avancée et la prise en charge multilingue plus étendue d'Octave 2.
contre. OpenAI TTS: Le système de synthèse vocale d'OpenAI excelle par sa clarté, son contrôle de la prosodie et sa flexibilité en matière de styles d'élocution grâce aux invites vocales. Octave 2 s'appuie sur ces atouts en intégrant la reconnaissance des intentions émotionnelles au niveau sémantique, ce qui permet une expressivité et une profondeur contextuelle nettement supérieures à celles de l'humain.
contre Mozilla TTS : Le système de synthèse vocale de Mozilla est hautement personnalisable pour la recherche et la création de voix sur mesure. Cependant, Octave 2, système professionnel basé sur la technologie LLM, offre une qualité vocale supérieure dès sa mise en service, une synthèse plus rapide, une modulation émotionnelle plus naturelle et une réactivité en temps réel.
contre Bavard : Chatterbox est optimisé pour des dialogues à faible latence et une expressivité configurable grâce à un clonage vocal efficace à plus petite échelle. Octave 2 surpasse Chatterbox en matière de compréhension sémantique, de profondeur émotionnelle, de cohérence sur les longs textes et de capacités multilingues complètes, offrant ainsi une expérience vocale en temps réel plus riche.
❓ Foire aux questions (FAQ)
Q : Qu'est-ce qui différencie Octave 2 des autres systèmes de synthèse vocale ?
A: Octave 2 est alimenté de manière unique par de grands modèles de langage (LLM) qui lui permettent de comprendre le contexte émotionnel et sémantique du texte, générant une parole plus expressive et plus humaine en temps réel, contrairement aux modèles TTS traditionnels.
Q : Quel est le faible temps de latence pour la génération vocale d'Octave 2 ?
A: Octave 2 se targue d'une latence ultra-faible, permettant une synthèse vocale en temps réel avec une latence de modèle aussi faible qu'environ 100 millisecondes, ce qui le rend idéal pour les applications interactives.
Q : Octave 2 peut-il prendre en charge plusieurs langues ?
R : Oui, Octave 2 offre une synthèse fluide dans 11 langues, dont l'anglais, le japonais, le coréen, l'espagnol, le français, le portugais, l'italien, l'allemand, le russe, l'hindi et l'arabe.
Q : Octave 2 est-il adapté aux contenus longs comme les livres audio ?
R : Absolument. Octave 2 est conçu pour une grande polyvalence sur les formats longs, en maintenant une cohérence émotionnelle sur des contenus étendus tels que les livres audio et les podcasts, et en s'adaptant de manière transparente aux changements de personnages et de scènes.
Q : Quelle est la structure tarifaire de l'API Octave 2 ?
R : L'API Octave 2 est proposée à un tarif compétitif de 0,063 $ pour 1000 caractères générés.
Terrain de jeu de l'IA

