 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropique - Claude
Anthropique - Claude xAI - Grok
xAI - Grok Recherche profonde
Recherche profonde Alibaba - Qwen
Alibaba - Qwen ByteDance - Le meilleur de ByteDance
ByteDance - Le meilleur de ByteDance Tous les modèles
Tous les modèles Plans d'entreprise
Plans d'entreprise Développement d'applications d'IA
Développement d'applications d'IA API de traduction IA
API de traduction IA Service SEO/GEO IA
Service SEO/GEO IA Service de relations publiques géo-optimisé
Service de relations publiques géo-optimisé Service de web scraping
Service de web scraping OpenClaw
OpenClaw Meilleurs outils d'IA
Meilleurs outils d'IA Les meilleurs robots IA
Les meilleurs robots IA
 Se connecter
Se connecter



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'alibaba/qwen3-next-80b-a3b-instruct',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="alibaba/qwen3-next-80b-a3b-instruct",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")

-p-130x130q80-p-130x130q80.png)
Détails du produit
Instructions Qwen3-Next-80B-A3B Il s'agit d'un modèle de langage étendu et hautement avancé, optimisé pour les instructions, conçu pour une vitesse, une stabilité et une gestion des contextes extrêmement longs exceptionnelles, avec un débit élevé. Il permet d'obtenir des gains significatifs en termes de vitesse et de rentabilité en n'activant qu'une petite partie de ses 80 milliards de paramètres, sans compromettre les performances dans des domaines critiques tels que le raisonnement complexe et la génération de code.
⚙️ Spécifications techniques
L'instruction Qwen3-Next-80B-A3B optimise ses opérations en Activation d'environ 3 milliards de paramètres seulement sur 80 milliards lors de l'inférenceCe mécanisme d'activation parcimonieux offre des avantages considérables :
- Rapidité et rentabilité : Fonctionne environ 10 fois plus vite et de manière plus rentable que le modèle Qwen3-32B précédent.
- Débit : Offre un débit plus de 10 fois supérieur lors du traitement de longs contextes de 32 000 jetons ou plus.
- Déploiement flexible : Offre des options de déploiement polyvalentes, notamment l'hébergement sans serveur, l'hébergement dédié à la demande et l'hébergement réservé mensuel.
- Compatibilité de déploiement : Compatible avec SGLang et vLLM pour une utilisation efficace et évolutive, avec des capacités avancées de prédiction multi-jetons.
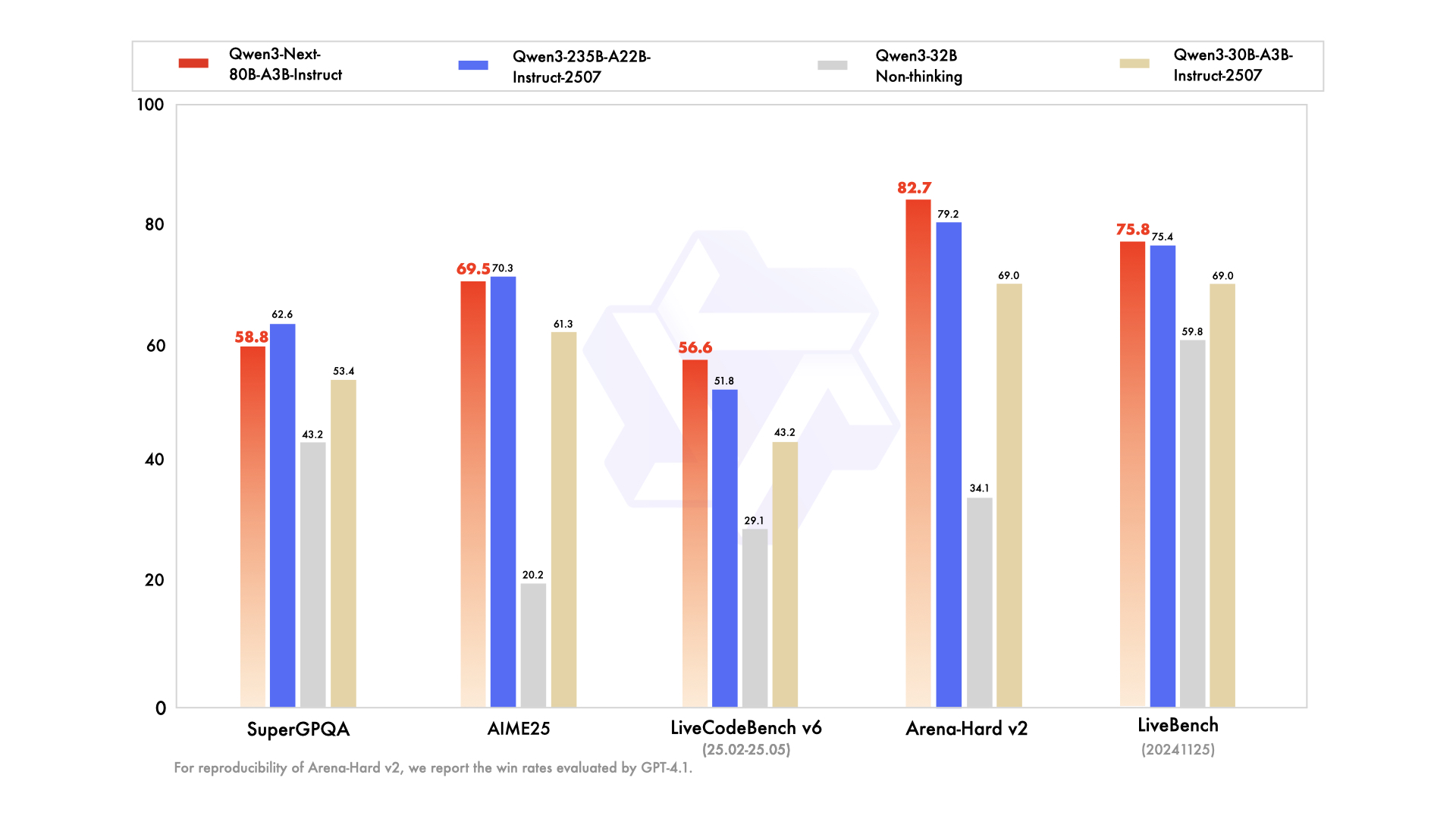
📊 Indicateurs de performance
- ✅ Performances de haut niveau : Égale ou se rapproche fortement des performances du modèle phare Qwen3-235B dans diverses tâches de raisonnement, de complétion de code et de suivi d'instructions.
- ✅ Gestion infaillible des contextes longs : Fournit systématiquement des réponses stables et déterministes, excellant particulièrement dans les tâches exigeant une compréhension approfondie du contexte.
- ✅ Économe en ressources : Surpasse en efficacité les modèles précédents de taille moyenne optimisés pour les instructions, atteignant des performances élevées avec moins de ressources de calcul.
- ✅ Intégration polyvalente : Particulièrement adapté à l'intégration d'outils, à la génération augmentée par la récupération (RAG) et aux flux de travail d'agents sophistiqués qui nécessitent des sorties cohérentes dans la chaîne de pensée.
💰 Tarification de l'API
Saisir: 0,1575 $
Sortir: 1,6 $
✨ Capacités clés
- 🚀 Inférence ultra-efficace : Utilise une architecture Mixture-of-Experts (MoE) clairsemée, activant dynamiquement seulement 3 milliards de paramètres sur 80 milliards pour une inférence nettement plus rapide et plus rentable.
- 🧠 Performance exceptionnelle dans l'exécution des tâches : Excelle dans un large éventail de tâches complexes, notamment le raisonnement avancé, la génération de code robuste, la réponse précise aux questions de connaissances et les applications multilingues polyvalentes.
- ⚡️ Réponses stables et rapides : Optimisé pour le mode instruction, garantissant des réponses rapides et cohérentes sans étapes de « réflexion » intermédiaires.
- 📖 Gestion des contextes ultra-longs : Il offre une longueur de contexte native de 262 000 jetons, extensible jusqu'à un impressionnant million de jetons grâce à une technologie de mise à l'échelle avancée.
- 📈 Débit élevé : Permet d'obtenir un débit 10 fois supérieur pour le traitement de contextes longs et étendus par rapport aux modèles précédents.
- 💬 Dialogue et réponses cohérents : Idéal pour les dialogues à plusieurs tours et les tâches exigeant des réponses finales déterministes et cohérentes.
- 🛠️ Flux de travail d'agents avancés : Solides capacités d'appel d'outils, d'exécution de tâches en plusieurs étapes et de flux de travail automatisés sophistiqués avec des outils parfaitement intégrés.
💡 Cas d'utilisation
- Génération de code : Accélérez le développement logiciel grâce à des suggestions de code intelligentes et à la génération complète de blocs de code.
- Création et édition de contenu : Générer du contenu varié, allant des articles aux textes marketing, et effectuer un travail d'édition complexe en suivant des instructions détaillées.
- Analyse des données : Faciliter l'interprétation de données complexes, l'analyse statistique et la génération de rapports complets.
- Automatisation du service client : Améliorez l'efficacité de votre service client grâce à une gestion précise des instructions et à des réponses automatisées.
- Documentation technique : Rationalisez la création de documents techniques, de manuels et de documents de sortie spécifiques à un format.
- Automatisation des processus : Exécutez des tâches en plusieurs étapes et intégrez des appels d'outils pour automatiser et rationaliser différents flux de travail.
- Conversations longues et gestion de documents : Gérer efficacement les dialogues longs, résumer les documents volumineux et extraire les informations clés des textes longs.
💻 Exemple de code
import openai client = openai.OpenAI( base_url="https://api.perplexity.ai", # Exemple d'URL de base, à remplacer par votre point de terminaison réel api_key="VOTRE_CLÉ_API", # À remplacer par votre clé API réelle ) messages = [ { "role": "system", "content": "Vous êtes Qwen3-Next-80B-A3B Instruct, un assistant IA utile." }, { "role": "user", "content": "Expliquez le concept d'intrication quantique en termes simples à un lycéen." }, ] response = client.chat.completions.create( model="alibaba/qwen3-next-80b-a3b-instruct", messages=messages, max_tokens=500, temperature=0.7, top_p=0.9, frequency_penalty=0, presence_penalty=0, ) print(response.choices[0].message.content) Remarque : Les variables `base_url` et `api_key` de l’exemple ci-dessus sont des exemples. Veuillez consulter la documentation officielle de l’API pour obtenir des informations précises sur l’intégration.
🆚 Comparaison avec d'autres modèles
Le modèle 80B A3B offre des performances qui égalent ou approchent de très près celles du modèle phare 235B dans les tâches de raisonnement et de codage, tout en étant nettement plus efficace en activant moins de paramètres pour une inférence plus rapide et plus rentable.
Qwen3-Next offre des capacités de suivi d'instructions et de contexte long comparables, se distinguant par un avantage en termes de débit et une taille de fenêtre de jetons plus grande, ce qui le rend particulièrement adapté aux tâches de compréhension de documents étendues.
Qwen3-Next affiche des performances supérieures dans les dialogues à plusieurs tours et les flux de travail multi-agents, fournissant des résultats plus déterministes dans des contextes très longs par rapport aux points forts conversationnels de Claude.
Qwen3-Next présente une meilleure évolutivité dans la gestion de contextes ultra-longs et une efficacité de prédiction multi-jetons supérieure, ce qui lui confère un avantage distinct dans le traitement de tâches de raisonnement complexes et à plusieurs étapes.
❓ Foire aux questions
Q1 : Qu'est-ce qui rend l'instruction Qwen3-Next-80B-A3B exceptionnellement efficace ?
Ce modèle exploite une architecture de type Mixture-of-Experts (MoE) clairsemée, n'activant qu'environ 3 milliards de ses 80 milliards de paramètres lors de l'inférence. Cette approche novatrice permet un traitement nettement plus rapide et des coûts opérationnels réduits, avec une efficacité jusqu'à 10 fois supérieure à celle des modèles précédents.
Q2 : Comment se comporte-t-il avec des contextes ultra-longs ?
Qwen3-Next-80B-A3B Instruct prend en charge une longueur de contexte native de 262 000 jetons, et grâce à une technologie de mise à l'échelle avancée, cette capacité peut être étendue jusqu'à 1 million de jetons. Cette fonctionnalité la rend idéale pour les tâches nécessitant une compréhension approfondie de documents volumineux et de longues conversations.
Q3 : Comment ses performances se comparent-elles à celles des autres principaux modèles de langage ?
Tout en étant extrêmement efficace, Qwen3-Next-80B-A3B Instruct atteint, voire surpasse, les performances de modèles phares tels que Qwen3-235B pour les tâches complexes de raisonnement et de génération de code. Il offre également des capacités comparables, voire supérieures, en termes de débit, de gestion de contextes longs et de résultats déterministes, par rapport à des modèles comme GPT-4.1, Claude 4.1 Opus et Gemini 2.5 Flash.
Q4 : Quels sont les principaux cas d'utilisation de l'instruction Qwen3-Next-80B-A3B ?
Ce modèle est particulièrement adapté aux applications exigeant un débit élevé, un suivi précis des instructions et un traitement contextuel étendu. Parmi ses principaux cas d'utilisation figurent la génération de code avancée, la création de contenu sophistiqué, l'analyse de données détaillée, le service client automatisé, la documentation technique et les flux de travail complexes impliquant des agents.
Q5 : L'instruction Qwen3-Next-80B-A3B est-elle compatible avec les infrastructures de déploiement existantes ?
Oui, ce modèle est conçu pour une intégration transparente avec les outils de déploiement existants tels que SGLang et vLLM, et prend en charge des fonctionnalités avancées de prédiction multi-jetons. Il offre également des options de déploiement flexibles, notamment l'hébergement sans serveur, l'hébergement dédié à la demande et l'hébergement réservé mensuel, afin de répondre à divers besoins opérationnels.
Terrain de jeu de l'IA

