 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropique - Claude
Anthropique - Claude xAI - Grok
xAI - Grok Recherche profonde
Recherche profonde Alibaba - Qwen
Alibaba - Qwen ByteDance - Le meilleur de ByteDance
ByteDance - Le meilleur de ByteDance Tous les modèles
Tous les modèles Plans d'entreprise
Plans d'entreprise Développement d'applications d'IA
Développement d'applications d'IA API de traduction IA
API de traduction IA Service SEO/GEO IA
Service SEO/GEO IA Service de relations publiques géo-optimisé
Service de relations publiques géo-optimisé Service de web scraping
Service de web scraping OpenClaw
OpenClaw Meilleurs outils d'IA
Meilleurs outils d'IA Les meilleurs robots IA
Les meilleurs robots IA
 Se connecter
Se connecter



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'alibaba/qwen3-vl-32b-instruct',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="alibaba/qwen3-vl-32b-instruct",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Détails du produit
✨ Découvrez Qwen3 VL 32B Instruct : votre IA vision-langage avancée
Le Instructions Qwen3 VL 32B Ce modèle de vision et de langage (VL) de pointe est spécialement conçu pour un suivi précis des instructions dans un large éventail de tâches visuelles. Il se distingue par sa capacité à interpréter des entrées visuelles complexes et à générer des sorties textuelles hautement cohérentes et contextuelles. Ce modèle est méticuleusement optimisé pour exceller dans la description d'images, les dialogues visuels engageants et la génération de contenu polyvalent, ce qui en fait un outil puissant pour les applications d'IA multimodales.
Comme détaillé dans son Présentation officielle du Qwen3 VL 32B, le Qwen3 VL 32B Instruct est une version « sans réflexion uniquement », ce qui signifie qu'il est optimisé pour une exécution directe et efficace des tâches visuelles plutôt que pour un raisonnement général plus large, garantissant des performances supérieures dans son domaine spécialisé.
⚙️ Caractéristiques techniques en bref
- Type de modèle : Modèle Vision-Langage à Grand Étendue (VL)
- Nombre de paramètres : 32 milliards de paramètres
- Architecture: Architecture multimodale basée sur un transformateur, intégrant un encodeur visuel robuste et un décodeur de texte sophistiqué.
- Modalités d'entrée : Permet une intégration transparente des images et des instructions/invites textuelles.
- Modalités de sortie : Spécialisé dans la génération de textes de haute qualité (descriptions, dialogues, contenus créatifs).
- Données d'entraînement : Entraîné sur un vaste ensemble de données multimodales à grande échelle comprenant des images méticuleusement annotées associées à un texte descriptif et conversationnel riche.
- Capacités d'inférence : Offre un suivi rigoureux des instructions, du tir zéro au tir réduit, éliminant ainsi le besoin d'une formation de recyclage approfondie.
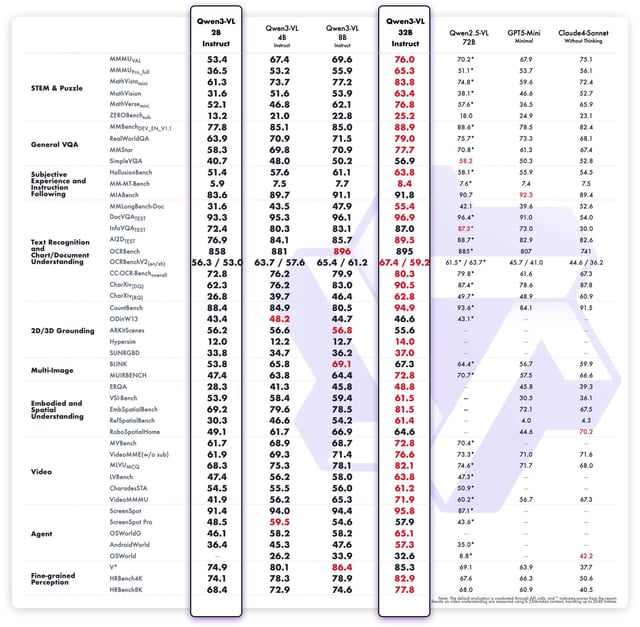
🚀 Performances et références inégalées
- 🎯 Réussit précision de pointe sur les principaux ensembles de données de description visuelle, rigoureusement comparés aux tâches COCO Caption et VQA.
- 📈 Démontre capacités supérieures de suivi des instructions, validées par des évaluations humaines pour leur pertinence et leur cohérence exceptionnelles.
- 💡 Surpasse les versions précédentes de Qwen VL en matière de qualité de génération de contenu multimodal et d'alignement précis des instructions.
- 🔒 Expositions performances robustes en mode zéro tir dans des tâches complexes de dialogue visuel, par rapport aux modèles de référence.
🌟 Principales caractéristiques et avantages
- ✨ Descriptions précises des images : Optimisé pour générer des descriptions d'images exceptionnellement claires et précises, basées sur les instructions de l'utilisateur.
- 💬 Dialogues visuels captivants : Capable de comprendre des contextes visuels complexes et de participer à des dialogues visuels dynamiques.
- 🎨 Génération de contenu créatif : Génère un contenu visuel hautement pertinent et innovant directement à partir de consignes textuelles.
- ✔️ Alignement des instructions de haut niveau : Réduit au minimum les contenus non pertinents ou hallucinatoires en assurant une stricte conformité avec les instructions de l'utilisateur.
- 🖼️ Traitement haute résolution efficace : Gère efficacement les images volumineuses à haute résolution grâce à une compréhension visuelle fine.
- 🌍 Sortie multilingue : Prend en charge la sortie de texte multilingue, démontrant une excellente maîtrise de différentes langues.
- 🔌 Intégration facile : Conçu pour une intégration simple dans les chaînes de production de contenu pilotées par l'IA et les assistants visuels interactifs.
💰 Tarification de l'API Qwen3 VL 32B
- ➡️ Saisir: 0,735 $ / 1 million de jetons
- ⬅️ Sortir: 2,94 $ / 1 million de jetons
💡 Cas d'utilisation polyvalents
- 📸 Légende automatique des images : Idéal pour les systèmes de gestion d'actifs numériques, fournissant des descriptions instantanées et précises.
- 🗣️ Assurance qualité visuelle et assistance client : Améliore les chatbots du service client grâce à des fonctionnalités interactives de réponse aux questions visuelles.
- ✍️ Marketing et création de contenu : Permet la création de contenu pour les campagnes marketing, les réseaux sociaux et la narration créative à l'aide d'images.
- 🚶♀️ Assistance aux personnes malvoyantes : Il décrit les scènes visuelles avec une grande précision, offrant un soutien inestimable.
- 🔍 Recherche multimédia améliorée : Améliore les capacités des moteurs de recherche grâce à une compréhension avancée du contexte basé sur l'image.
- 📚 Applications éducatives : Il propose des explications visuelles interactives et des tutoriels, rendant l'apprentissage plus attrayant.
💻 Exemple de code pour l'intégration
Vous trouverez ci-dessous un extrait de code typique illustrant comment interagir avec l'API d'instructions Qwen3 VL 32B.
import openai client = openai.OpenAI( api_key="VOTRE_CLÉ_API", # Remplacez par votre clé API base_url="https://api.votre-fournisseur.com/v1" # Remplacez par votre point de terminaison API ) response = client.chat.completions.create( model="alibaba/qwen3-vl-32b-instruct", messages=[ {"role": "system", "content": "Vous êtes un assistant utile capable de décrire des images."}, {"role": "user", "content": [ {"type": "text", "text": "Que contient cette image ?"}, {"type": "image_url", "image_url": {"url": "https://example.com/image.jpg"}} ]} ], max_tokens=500 ) print(response.choices[0].message.content) 🆚 Qwen3 VL 32B Instruct vs. Autres modèles leaders
contre Qwen3 VL 32B Base :
Le Version d'instruction Il est méticuleusement optimisé pour une application optimale des consignes, ce qui permet de fournir des descriptions plus pertinentes et précises. En revanche, le modèle de base vise principalement la compréhension multimodale générale.
contre OpenAI GPT-4 (avec vision) :
Qwen3 VL 32B Instruct est conçu et optimisé pour le suivi d'instructions spécialisées et la génération de contenu visuel, ce qui réduit les hallucinations visuelles. Bien que GPT-4 offre des capacités d'IA générale plus étendues, il est moins spécialisé dans le respect direct des instructions visuelles.
vs. Claude 4.5 Visuel :
Qwen3 VL 32B Instruct offre une description d'images et une qualité de dialogue supérieures, avec une emphase particulière sur les instructions visuelles. Claude, bien qu'excellent pour le raisonnement textuel et la gestion de contextes plus larges, propose généralement une spécialisation visuelle légèrement moins poussée.
vs. DeepSeek V3.1 :
Qwen3 VL 32B Instruct excelle dans la génération de contenu détaillé et les tâches de visualisation sophistiquées. DeepSeek, quant à lui, est davantage orienté vers la recherche et la récupération sémantiques d'images.
❓ Foire aux questions (FAQ)
Q : À quoi sert principalement l'instruction Qwen3 VL 32B ?
A : Il s'agit d'un modèle vision-langage spécialisé, optimisé pour le suivi d'instructions dans des tâches telles que la description précise d'images, le dialogue visuel engageant et la génération intelligente de contenu basée sur des entrées visuelles et des invites textuelles.
Q : En quoi la version Qwen3 VL 32B Instruct se compare-t-elle à sa version de base ?
A : La version Instruct est spécifiquement optimisée pour une meilleure adhésion aux instructions, ce qui donne des descriptions plus précises et contextualisées, contrairement au modèle de base qui offre une compréhension multimodale générale.
Q : Quels sont les principaux avantages de l'utilisation de l'instruction Qwen3 VL 32B ?
A : Les principaux avantages comprennent une description précise des images, des capacités de dialogue visuel robustes, une génération de contenu créatif avec un alignement élevé des instructions, une gestion efficace des images haute résolution et une sortie de texte multilingue.
Q : L'instruction Qwen3 VL 32B peut-elle être utilisée dans des applications réelles ?
R : Absolument. C'est idéal pour la génération automatique de légendes d'images, les questions-réponses visuelles dans le service client, la création de contenu pilotée par l'IA, l'assistance aux utilisateurs malvoyants, l'amélioration de la recherche multimédia et les outils pédagogiques interactifs.
Q : Quelle est la structure tarifaire de l'API Qwen3 VL 32B ?
A : La tarification est progressive : les coûts d'entrée sont de 0,735 $ par million de jetons, et les coûts de sortie sont de 2,94 $ par million de jetons.
Terrain de jeu de l'IA

