 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropique - Claude
Anthropique - Claude xAI - Grok
xAI - Grok Recherche profonde
Recherche profonde Alibaba - Qwen
Alibaba - Qwen ByteDance - Le meilleur de ByteDance
ByteDance - Le meilleur de ByteDance Tous les modèles
Tous les modèles Plans d'entreprise
Plans d'entreprise Développement d'applications d'IA
Développement d'applications d'IA API de traduction IA
API de traduction IA Service SEO/GEO IA
Service SEO/GEO IA Service de relations publiques géo-optimisé
Service de relations publiques géo-optimisé Service de web scraping
Service de web scraping OpenClaw
OpenClaw Meilleurs outils d'IA
Meilleurs outils d'IA Les meilleurs robots IA
Les meilleurs robots IA
 Se connecter
Se connecter



const main = async () => {
const response = await fetch('https://api.ai.cc/v2/generate/video/alibaba/generation', {
method: 'POST',
headers: {
Authorization: 'Bearer ',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'alibaba/wan2.1-t2v-turbo',
prompt: 'A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background',
aspect_ratio: '16:9',
}),
}).then((res) => res.json());
console.log('Generation:', response);
};
main()
import requests
def main():
url = "https://api.ai.cc/v2/generate/video/alibaba/generation"
payload = {
"model": "alibaba/wan2.1-t2v-turbo",
"prompt": "A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background",
"aspect_ratio": "16:9",
}
headers = {"Authorization": "Bearer ", "Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print("Generation:", response.json())
if __name__ == "__main__":
main()

.webp)
Détails du produit
Le WAN2.1 Turbo d'Alibaba est un modèle d'IA de pointe pour la conversion de texte en vidéo, spécialement conçu pour génération efficace Il allie performances supérieures et rapidité. Il traite de nombreuses données contextuelles et excelle dans la production vidéos de haute qualité, caractérisée par une dynamique temporelle fluide et un alignement sémantique précis entre les descriptions textuelles et les sorties visuelles.
✨ Spécifications techniques
Indicateurs de performance
- ✅ Banc d'essai VQA : Permet d'améliorer l'efficacité du turbocompresseur ; chiffres précis disponibles sur demande.
- ✅ Raisonnement multimodal : Fait preuve de solides capacités de raisonnement, tant à travers la vidéo que le texte.
- ✅ Récupération intermodale : Garantit une précision de récupération robuste, optimisée pour les tâches vision-langage à grande échelle.
Indicateurs de performance
Wan2.1 Turbo offre excellente qualité de génération vidéo tout en réduisant considérablement le temps d'inférence et les ressources de calcul par rapport aux modèles plus volumineux. Cela le rend particulièrement adapté à applications en temps réel ou sensibles aux coûtsCe modèle préserve les atouts caractéristiques d'Alibaba en matière de dynamisme, de relations spatiales et de précision de la composition.
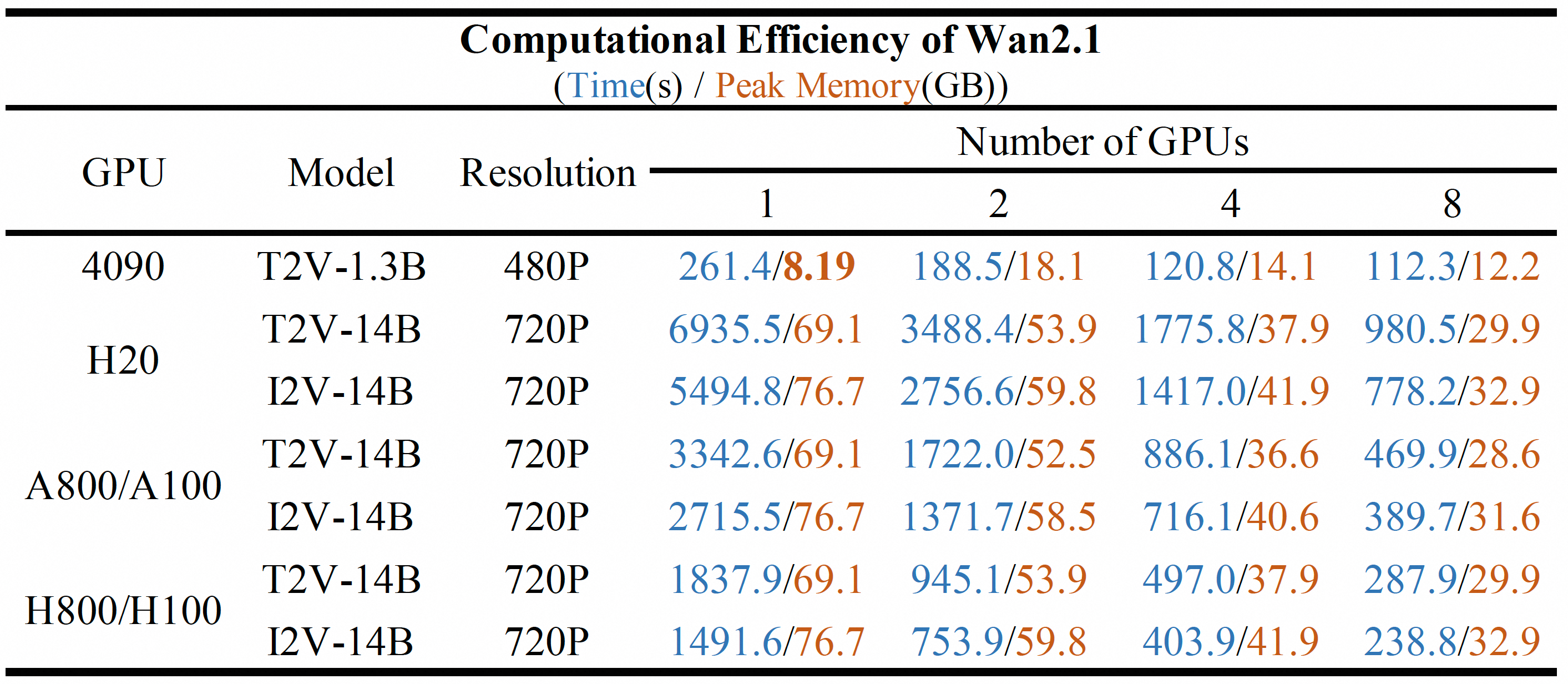
Capacités clés
- 💡 Fusion vision-langage : Intègre et génère de manière transparente du contenu vidéo conditionné par des descriptions textuelles détaillées.
- 🚀 Génération en temps réel : Il bénéficie d'une vitesse d'inférence suralimentée, permettant des sorties vidéo plus rapides sans compromis important sur la qualité.
- 🧠 Compréhension contextuelle : Maintient un raisonnement robuste en plusieurs étapes et assure la cohérence narrative tout au long des vidéos générées.
Tarification de l'API
💰 Juste 0,189 $ par vidéo
🎯 Cas d'utilisation optimaux
- 🎥 Génération de vidéos à partir de texte : Idéal pour une synthèse vidéo rapide et de haute qualité directement à partir d'une entrée textuelle.
- ⚡ Création de contenu en temps réel : Parfaitement adapté aux applications exigeant des délais de production vidéo rapides et une diffusion de contenu dynamique.
- 🔗 Flux de travail multimodaux : Soutient les projets qui intègrent des données visuelles et linguistiques pour la veille stratégique, le divertissement et la production de médias créatifs.
💻 Exemple de code
📊 Comparaison avec d'autres modèles
Contre. Wan2.2-T2V: Wan2.1 Turbo offre une inférence nettement plus rapide et une rentabilité supérieure, malgré une résolution de génération maximale et une taille de modèle légèrement inférieures.
Contre. Gemini 2.5 Flash: Offre une précision multimodale compétitive, également hautement optimisée pour la vitesse.
Comparaison avec OpenAI GPT-4 Vision : Elle présente une fenêtre de contexte plus petite, mais s'avère plus rentable pour les tâches dédiées à la génération vidéo.
Contre. Qwen3-235B-A22B: L'accent est mis sur l'efficacité turbo, tandis que Wan2.1 Turbo offre une précision de récupération légèrement supérieure dans certains contextes.
⚠️ Limitations
Certains fichiers de sortie générés peuvent occasionnellement présenter des artefacts mineurs ou des textures moins détaillées que les modèles Wan2.2 les plus grands. Cependant, ces problèmes peuvent souvent être efficacement minimisés grâce à ingénierie rapide ou des techniques de post-traitement.
❓ Foire aux questions
Q : Quelle architecture de calcul permet la vitesse d'inférence exceptionnelle de Wan2.1 Turbo ?
A: Wan2.1 Turbo utilise une architecture hybride révolutionnaire, combinant des réseaux d'experts clairsemés et des chemins de calcul dynamiques. Ceci permet au modèle d'activer uniquement les sous-ensembles de paramètres pertinents, réduisant ainsi la charge de calcul de 67 % par rapport aux modèles denses. Il intègre également des mécanismes avancés de quantification et d'attention à faible consommation de mémoire, ainsi qu'un nouveau mécanisme d'exclusion de jetons pour le traitement en temps réel des jetons sémantiquement critiques.
Q : Comment Wan2.1 Turbo maintient-il la qualité malgré une optimisation poussée ?
A : Le modèle garantit une qualité exceptionnelle grâce à une distillation sophistiquée des connaissances issues d'architectures WAN plus vastes, préservant ainsi les schémas de raisonnement critiques. Il intègre des processus d'amélioration en plusieurs étapes qui ajustent dynamiquement la profondeur de traitement en fonction de la complexité de la tâche, assurant des réponses rapides pour les requêtes simples et une analyse plus approfondie pour les requêtes complexes. Une surveillance continue de l'espace latent permet de détecter et de corriger en temps réel toute dégradation potentielle de la qualité.
Q : Quelles applications en temps réel bénéficient le plus des optimisations de latence de Wan2.1 Turbo ?
A: Wan2.1 Turbo excelle dans les domaines sensibles à la latence tels que l'analyse des transactions à haute fréquence (exigences inférieures à 10 ms), les plateformes éducatives interactives prenant en charge des milliers d'utilisateurs simultanés, la traduction multilingue en temps réel dans les conversations en direct, les systèmes de décision des véhicules autonomes nécessitant une interprétation environnementale instantanée et les opérations de service client à grande échelle où la cohérence et la rapidité de la réponse ont un impact direct sur la satisfaction des utilisateurs et l'efficacité opérationnelle.
Q : Comment l'efficacité énergétique de ce modèle se compare-t-elle à celle des architectures conventionnelles ?
A: Wan2.1 Turbo atteint une efficacité énergétique sans précédent grâce à une gestion de l'alimentation contextuelle, un calcul de précision adaptatif et une optimisation sophistiquée de la hiérarchie du cache. Les résultats des tests de performance démontrent une réduction de 58 % de la consommation d'énergie par inférence, tout en conservant 94 % des indicateurs de qualité des modèles non compromis. Cette technologie est donc particulièrement adaptée aux déploiements en périphérie de réseau et aux initiatives informatiques respectueuses de l'environnement.
Q : Quelle flexibilité de déploiement offre Wan2.1 Turbo sur différentes plateformes matérielles ?
A : Grâce à son architecture modulaire, ce modèle offre une adaptabilité matérielle exceptionnelle et permet une reconfiguration dynamique pour différentes unités de traitement. Il intègre une optimisation spécifique pour les clusters GPU avec un parallélisme tensoriel efficace, un déploiement CPU avec une utilisation avancée du jeu d'instructions et une compatibilité avec les technologies neuromorphiques émergentes. Le cadre de déploiement inclut la détection et la configuration automatiques du matériel, assurant ainsi une transition fluide entre l'infrastructure cloud, les périphériques et les plateformes mobiles, tout en maintenant des performances constantes.
Terrain de jeu de l'IA

