 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropique - Claude
Anthropique - Claude xAI - Grok
xAI - Grok Recherche profonde
Recherche profonde Alibaba - Qwen
Alibaba - Qwen ByteDance - Le meilleur de ByteDance
ByteDance - Le meilleur de ByteDance Tous les modèles
Tous les modèles Plans d'entreprise
Plans d'entreprise Développement d'applications d'IA
Développement d'applications d'IA API de traduction IA
API de traduction IA Service SEO/GEO IA
Service SEO/GEO IA Service de relations publiques géo-optimisé
Service de relations publiques géo-optimisé Service de web scraping
Service de web scraping OpenClaw
OpenClaw Meilleurs outils d'IA
Meilleurs outils d'IA Les meilleurs robots IA
Les meilleurs robots IA
 Se connecter
Se connecter



const main = async () => {
const response = await fetch('https://api.ai.cc/v2/generate/video/alibaba/generation', {
method: 'POST',
headers: {
Authorization: 'Bearer ',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'alibaba/wan2.2-t2v-plus',
prompt: 'A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background',
aspect_ratio: '16:9',
}),
}).then((res) => res.json());
console.log('Generation:', response);
};
main()
import requests
def main():
url = "https://api.ai.cc/v2/generate/video/alibaba/generation"
payload = {
"model": "alibaba/wan2.2-t2v-plus",
"prompt": "A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background",
"aspect_ratio": "16:9",
}
headers = {"Authorization": "Bearer ", "Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print("Generation:", response.json())
if __name__ == "__main__":
main()

.webp)
Détails du produit
Alibaba Wan2.2 est à la pointe de la technologie Modèle d'IA conçu avec précision pour des applications avancées compréhension multimodaleIl intègre de manière transparente les entrées textuelles et visuelles, offrant des capacités robustes pour le traitement de contextes étendus et une précision supérieure dans les tâches complexes de conversion texte-vision et les défis de raisonnement complexes.
✨ Spécifications techniques
Indicateurs de performance
- ✅ Banc VQA : 78,3%
- ✅ Raisonnement multimodal : 52,7%
- ✅ Récupération intermodale : 81,9%
Indicateurs de performance (WAN 2.1)
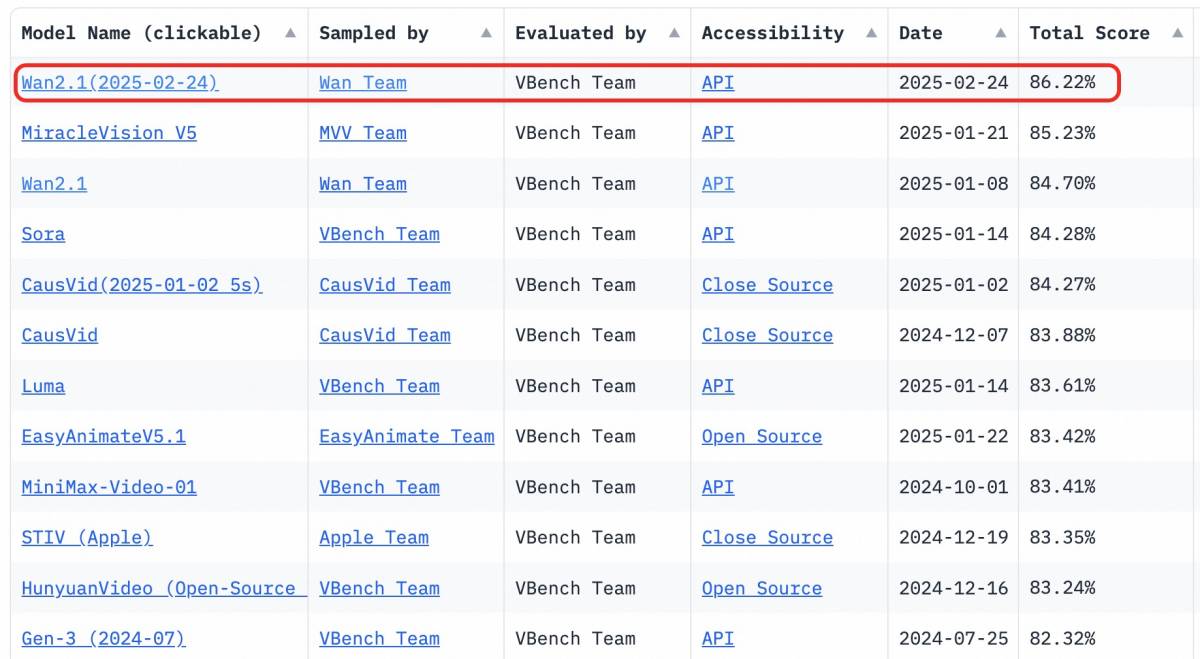
Wan2.1 se distingue par un score global impressionnant. Score VBench de 86,22%Ces modèles vidéo avancés offrent des performances exceptionnelles en matière de mouvement dynamique, de relations spatiales, de fidélité des couleurs et d'interaction multi-objets. Leur entraînement exige une puissance de calcul considérable et l'accès à de vastes ensembles de données de haute qualité. L'accès libre à ces modèles avancés réduit considérablement les obstacles, permettant ainsi à un plus grand nombre d'entreprises de créer des contenus visuels personnalisés et de haute qualité à moindre coût.
Capacités clés
- 💡 Fusion vision-langage : Excellant dans l'interprétation et la génération de réponses précises grâce à une combinaison harmonieuse de données d'image et de texte.
- 💡 Raisonnement avancé : Démontre de solides capacités de raisonnement à plusieurs étapes selon diverses modalités pour une analyse approfondie et une compréhension complexe.
💲 Tarification de l'API
- 🎥 480P : 0,105 $/vidéo
- 🎥 1080p : 0,525 $/vidéo
🚀 Cas d'utilisation optimaux
- ✅ Analyse multimodale : Améliorer la compréhension grâce à une combinaison experte de données visuelles et textuelles.
- ✅ Réponse visuelle aux questions (VQA) : Fournir des réponses précises et contextuelles basées sur des entrées image-texte intégrées.
- ✅ Récupération intermodale : Permettre une mise en correspondance et une récupération efficaces des informations dans les domaines de la vision et du langage.
- ✅ Veille stratégique : Faciliter l'interprétation de données complexes en intégrant le contenu visuel à l'analyse textuelle pour des connaissances plus approfondies.
💻 Exemple de code
📊 Comparaison avec d'autres modèles leaders
- Contre. Gemini 2.5 Flash: Alibaba Wan2.2 offre une précision multimodale plus élevée (78,3% par rapport à 70,8 % VQA-bench), ce qui en fait un choix supérieur pour les tâches intégrées de vision et de langage.
- Comparaison avec OpenAI GPT-4 Vision : Wan2.2 offre une fenêtre de contexte nettement plus large (65K vs. 32K jetons texte), permettant des conversations plus approfondies et cohérentes grâce à l'intégration d'images.
- Contre Qwen3-235B-A22B : Alibaba Wan2.2 démontre une précision de récupération intermodale supérieure (81,9% contre environ 78 % estimé), l'optimisant pour les flux de travail vision-langage à grande échelle exigeants.
⚠️ Limitations
Il arrive que les vidéos générées contiennent des éléments indésirables, comme des artefacts textuels ou des filigranes. Si l'utilisation de messages d'avertissement peut contribuer à atténuer ces problèmes, elle ne les élimine pas complètement.
🔗 Intégration API
Alibaba Wan2.2 est facilement accessible via le API IA/MLUne documentation complète est disponible pour faciliter un processus d'intégration fluide et efficace.
❓ Foire aux questions (FAQ)
A: Alibaba Wan2.2 est un modèle d'IA avancé conçu pour la compréhension multimodale, intégrant spécifiquement des entrées textuelles et visuelles pour un raisonnement complexe et des tâches de conversion texte-vision de haute précision.
A: Wan2.2 démontre une précision multimodale plus élevée (78,3 % VQA-bench) par rapport à Gemini 2.5 Flash (70,8 %), ce qui le rend particulièrement efficace pour les tâches intégrées de vision et de langage.
A : Ses principales capacités comprennent une fusion vision-langage robuste pour interpréter et générer du contenu à partir de données combinées d'images et de texte, et un raisonnement avancé en plusieurs étapes à travers différentes modalités.
A : Il arrive que les vidéos générées contiennent des éléments indésirables, comme des artefacts textuels ou des filigranes. Bien que les messages d'avertissement puissent atténuer ces problèmes, ils ne les éliminent pas complètement.
A: Alibaba Wan2.2 est facilement accessible via l'API IA/ML, avec une documentation complète fournie pour guider le processus d'intégration.
Terrain de jeu de l'IA

