 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in



const main = async () => {
const response = await fetch('https://api.ai.cc/v2/video/generations', {
method: 'POST',
headers: {
Authorization: 'Bearer ',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'tencent/hunyuan-video-foley',
video_url: 'https://storage.googleapis.com/falserverless/model_tests/video_models/1_video.mp4',
prompt: 'A person walks on frozen ice',
}),
}).then((res) => res.json());
console.log('Generation:', response);
};
main()
import requests
def main():
url = "https://api.ai.cc/v2/video/generations"
payload = {
"model": "tencent/hunyuan-video-foley",
"video_url": "https://storage.googleapis.com/falserverless/model_tests/video_models/1_video.mp4",
"prompt": "A person walks on frozen ice",
}
headers = {"Authorization": "Bearer ", "Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print("Generation:", response.json())
if __name__ == "__main__":
main()


Product Detail
✨ HunyuanVideo Foley: AI-Powered Sound Generation for Videos
HunyuanVideo Foley represents an innovative artificial intelligence model developed by Tencent's Hunyuan team. This advanced solution is meticulously engineered to generate high-quality, richly detailed sound effects for silent videos, thereby profoundly enhancing the auditory experience of visual media. By leveraging state-of-the-art multimodal diffusion techniques and extensive large-scale data training, it expertly synthesizes audio that precisely aligns with both video content and accompanying textual descriptions.
⚙️ Technical Specifications
- Architecture: A robust multimodal diffusion model, seamlessly combining video, text, and audio modalities, further enhanced with specialized alignment loss and audio VAE optimization.
- Audio Sample Rate: Delivers exceptional high-fidelity audio output at 48 kHz.
- Model Components: Integrates DAC-VAE for superior audio reconstruction and a sophisticated multimodal transformer block for coherent joint video and text integration.
- Training Data: Extensive training on vast datasets including Kling-Audio-Eval, VGGSound, and MovieGen-Audio, covering an expansive array of sounds, music, and speech domains.
- Output Features: Generates temporally synchronized audio streams that are precisely aligned, both visually and semantically, with corresponding video frames.
🚀 Unrivaled Performance Benchmarks
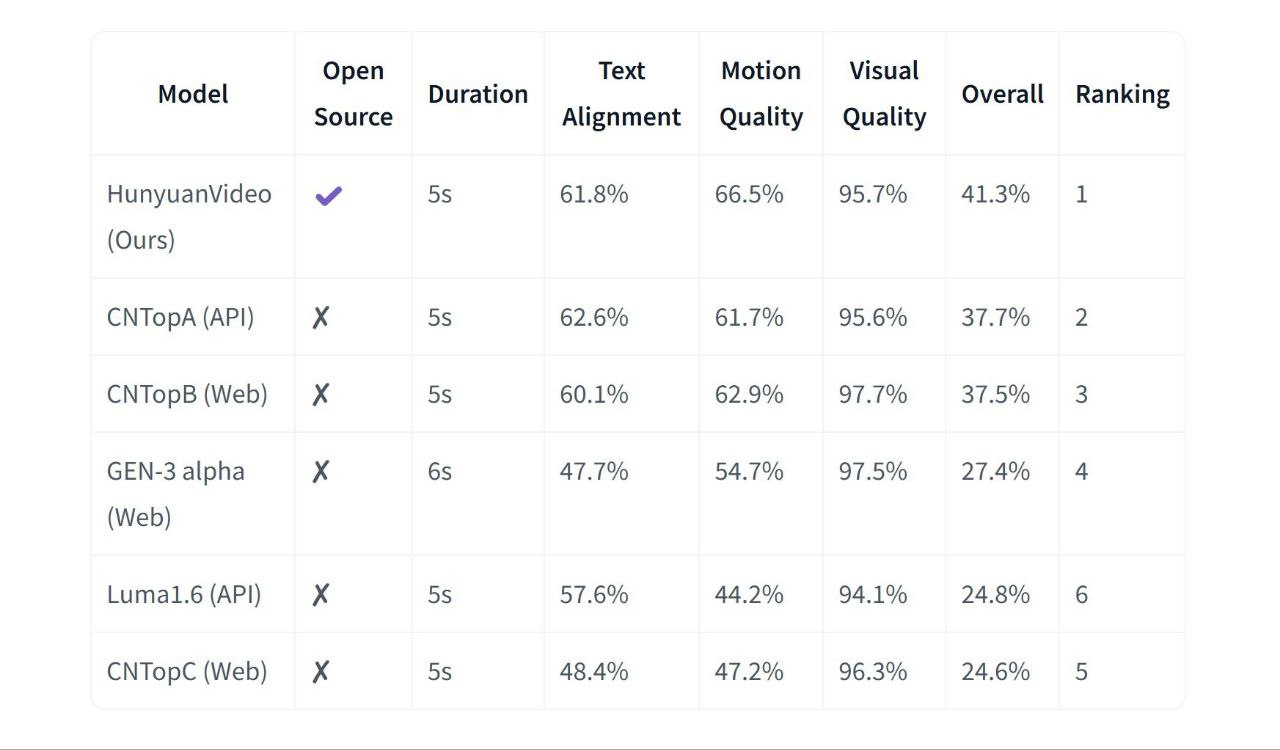
Across a suite of rigorous benchmarks, including Kling-Audio-Eval, VGGSound-Test, and MovieGen-Audio-Bench, HunyuanVideo Foley consistently demonstrates superior performance, surpassing leading competitors such as FoleyCrafter, MMAudio, V-AURA, and ThinkSound.

The model consistently leads in crucial performance metrics: audio fidelity, semantic alignment between visuals and sound, temporal synchronization, and distribution matching. It consistently outperforms all well-known open-source models in these areas. Verified by both objective evaluations and expert human assessments, HunyuanVideo Foley exhibits robust and stable performance across an extensive array of video content and audio scenarios, confirming its reliability in diverse real-world applications.
💡 Key Features & Benefits
- ✅ Automatic Foley Generation: Transforms silent videos and accompanying text into vibrant, contextually aware, and immersive sound effects.
- 🌍 Multi-Scenario Applicability: Highly adaptable for diverse applications, including short video creation, professional movie post-production, dynamic advertisements, and immersive game development.
- 🔊 High-Fidelity Audio Output: Captures even the most minute audio details, from subtle object collisions to complex and expansive environmental ambiances.
- ⚖️ Semantic Equalization Response: Intelligently processes and balances input video and textual descriptions to construct holistic and perfectly balanced soundscapes.
- 🏗️ Robust Audio Reconstruction: Powered by its DAC-VAE backbone, ensuring consistently strong and reliable performance across general sounds, intricate music pieces, and clear speech domains.
💰 Flexible API Pricing
Remarkably affordable at just $0.0105 per second.
🎯 Diverse Applications & Use Cases
- 🎥 Short and Social Video Creation: Significantly enhance viewer engagement with dynamic and contextually rich sound effects.
- 🎬 Film and TV Post-Production Sound Design: Streamline and elevate professional sound design workflows, saving time and resources.
- 📈 Marketing and Advertising Video Audio Enhancement: Elevate video campaigns with captivating and persuasive audio, boosting impact.
- 🎮 Immersive Audio for Game Development: Create rich, interactive, and truly immersive soundscapes that enhance player experience.
- 🗣️ Automated Dubbing and Foley Replacement: Efficiently replace or generate crucial audio elements, including dialogue and sound effects, for global reach.
💻 Integration: Code Samples
Generation Code Sample
Output Code Sample
🆚 HunyuanVideo Foley vs. Competitors
vs Runway Gen-3: HunyuanVideo Foley excels in generating highly synchronized, high-fidelity audio specifically for videos, prioritizing precise sound-to-video alignment and realism. In contrast, Runway Gen-3 primarily focuses on visual text-to-video synthesis and offers broader video editing tools but does not feature integrated audio effect generation capabilities.
vs Luma 1.6: Foley significantly surpasses Luma 1.6 in terms of audio-visual semantic synchronization and overall sound quality. Luma 1.6 is specialized in maintaining spatial and temporal video consistency but does not offer sound effect generation. HunyuanVideo Foley uniquely automates professional-grade Foley sound creation.
vs Wan 2.1: While Wan 2.1 is designed for multilingual text-to-video generation and is generally more accessible with lower hardware requirements, Foley focuses on high-end, computationally intensive Foley sound generation tailored for professional applications. Critically, Wan 2.1 does not support synchronized audio effects like those proficiently generated by HunyuanVideo Foley.
❓ Frequently Asked Questions (FAQ)
Q1: What is HunyuanVideo Foley?
HunyuanVideo Foley is an advanced AI model developed by Tencent's Hunyuan team. It specializes in automatically generating high-quality, perfectly synchronized sound effects for silent videos, based on the visual content and any accompanying text descriptions.
Q2: What types of projects can benefit from HunyuanVideo Foley?
It's highly versatile and ideal for a wide range of applications including short and social video creation, professional film and TV post-production, enhancing marketing and advertising videos, and creating immersive audio for game development.
Q3: How does HunyuanVideo Foley ensure such high-fidelity audio?
The model leverages a sophisticated multimodal diffusion architecture, incorporating a DAC-VAE backbone, and is trained on vast datasets. This meticulous design ensures robust audio reconstruction and the ability to capture fine sound details at an impressive 48 kHz sample rate.
Q4: Is the output from HunyuanVideo Foley compatible with mobile devices?
Yes, the generated audio and the HTML structure provided are designed to be fully responsive and compatible, ensuring a seamless and high-quality experience for users across various mobile devices and platforms.
Q5: How does HunyuanVideo Foley compare to other prominent AI models like Runway Gen-3?
HunyuanVideo Foley differentiates itself by focusing specifically on superior audio-visual synchronization and high-fidelity sound generation. While models like Runway Gen-3 excel in visual text-to-video synthesis, Foley provides a distinct advantage in integrated audio effect generation and overall realism for sound.
AI Playground

