 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in



const axios = require('axios').default;
const api = axios.create({
baseURL: 'https://api.ai.cc/v1',
headers: { Authorization: 'Bearer ' },
});
const main = async () => {
const response = await api.post('/tts', {
model: 'inworld/tts-1',
text: 'OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.',
voice: 'coral',
});
console.log('Audio URL:', response.data.audio.url);
console.log('Characters:', response.data.usage.characters);
};
main();
import requests
def main():
url = "https://api.ai.cc/v1/tts"
headers = {
"Authorization": "Bearer ",
}
payload = {
"model": "inworld/tts-1",
"text": "OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.",
"voice": "coral"
}
response = requests.post(url, headers=headers, json=payload)
data = response.json()
print("Audio URL:", data["audio"]["url"])
print("Characters:", data["usage"]["characters"])
main()


Product Detail
✨ Inworld TTS-1 API: Advanced Real-time Speech Synthesis
The Inworld TTS-1 model represents a cutting-edge, Transformer-based autoregressive Text-to-Speech (TTS) solution, engineered for producing high-quality, real-time speech across multiple languages. It delivers audio with exceptionally low latency at a superior 48 kHz resolution. Furthermore, it incorporates advanced capabilities for fine-grained emotional control, making it versatile for both on-device and cloud-based applications.
⚙️ Technical Specifications
- • Architecture: Transformer-based autoregressive model
- • Parameter Count: 1.6 Billion (TTS-1)
- • Sample Rate: Up to 48 kHz high-resolution audio
- • Latency: Optimized for low-latency, real-time applications
- • Languages: Supports 11 languages with robust multilingual capabilities
- • Emotional Control: Advanced fine-grained expressiveness
🌟 Key Features
- • High-Fidelity Audio: Delivers 48 kHz speech generation with super-resolution techniques for crystal-clear audio.
- • Nuanced Emotional Control: Allows for fine-grained emotional and prosodic adjustments, enabling highly nuanced speech output.
- • Consistent Multilingual Quality: Ensures consistent, high-quality speech across all 11 supported languages.
- • Efficient Deployment: Optimized architecture for seamless integration into both cloud and edge (on-device) environments.
- • Robust Training: Built on a vast training dataset of over 300,000 hours of English and Chinese speech, enhancing naturalness and robustness.
🚀 Performance & Visual Benchmarks
Inworld TTS-1 consistently outperforms many competing models, particularly in areas of multilingual speech quality, emotional range, and ultra-low latency, establishing it as a leader for demanding real-time applications.
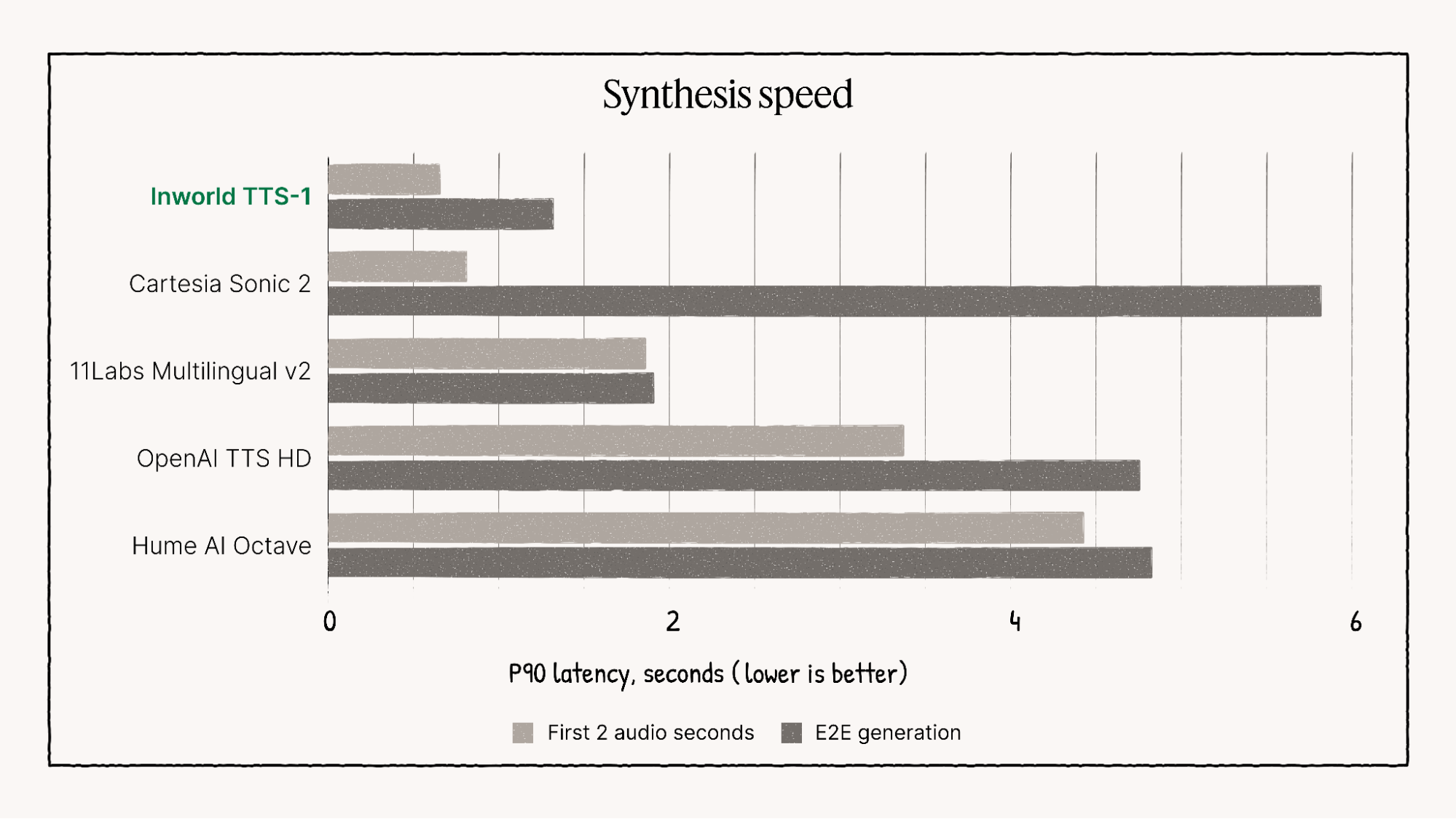
Visual representation of Inworld TTS-1's performance characteristics.
💲 API Pricing
$5.25 per 1 Million Characters
(approximately $0.00525 per minute of generated speech)
💡 Versatile Use Cases
- • Real-time Voice Assistants & Conversational AI: Perfect for applications demanding natural, low-latency speech for seamless interaction.
- • Multimedia Content Creation: Enhance audiobooks, podcasts, and video narrations with high-quality, multilingual voiceovers.
- • Interactive Voice Response (IVR) Systems: Infuse IVR systems with emotional nuance to significantly boost user engagement.
- • On-device TTS Applications: Efficiently deploy high-quality speech synthesis on mobile and embedded systems with limited resources.
- • Educational & Accessibility Tools: Provide high-quality multilingual speech synthesis to enrich learning and accessibility experiences.
🆚 Inworld TTS-1 vs. Leading Competitors
vs. Google WaveNet: Inworld TTS-1 excels with its lower latency and superior real-time synthesis, making it ideal for interactive applications. WaveNet offers highly natural and expressive speech but generally at a higher computational cost.
vs. 11LABS Multilingual V2: Inworld TTS-1 provides finer emotional nuance and even lower latency for live interaction scenarios. While 11LABS offers strong multilingual capabilities with a simpler interface, Inworld TTS-1 is the preferred choice for premium, expressive output.
vs. OpenAI TTS-1-HD: OpenAI TTS-1-HD delivers ultra-high-definition, studio-quality audio with exceptional fidelity, often surpassing Inworld in sheer audio richness. However, this comes at the expense of higher latency and cost. Inworld TTS-1 offers a more cost-efficient and versatile solution for multilingual and device-flexible deployments, perfectly suited for everyday real-time needs.
💻 Code Sample & Documentation
For detailed API usage and integration, refer to the official documentation:
Inworld TTS-1 API Documentation (External Link)
<snippet data-docs="https://docs.ai.cc/api-references/speech-models/text-to-speech/inworld/tts-1" snippet data-name="voice.tts-openai" data-model="inworld/tts-1"></snippet>❓ Frequently Asked Questions (FAQ)
Inworld TTS-1 is a state-of-the-art, Transformer-based autoregressive text-to-speech model designed for high-quality, real-time speech synthesis. It features low-latency audio at 48 kHz, supports fine-grained emotional control, and is optimized for multilingual applications across both cloud and on-device environments.
Key specifications include a 1.6 billion parameter architecture, up to 48 kHz high-resolution audio, and support for 11 languages. Its core features encompass high-fidelity speech generation, nuanced emotional and prosodic control, efficient cloud/edge deployment, and robustness from a 300,000+ hour training dataset.
Inworld TTS-1 distinguishes itself with lower latency and superior real-time capabilities compared to Google WaveNet, finer emotional nuance and lower latency for live interactions over 11LABS Multilingual V2, and better cost-efficiency and device flexibility than OpenAI TTS-1-HD, which prioritizes ultra-high definition at higher cost and latency.
Primary use cases include real-time voice assistants, multimedia content creation, emotionally intelligent IVR systems, on-device TTS, and multilingual educational/accessibility tools. The API is priced at $5.25 per 1 million characters, equating to approximately $0.00525 per minute of speech.
AI Playground

