 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'alibaba/qwen3-vl-32b-thinking',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="alibaba/qwen3-vl-32b-thinking",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Product Detail
💡 Unlocking Advanced Multimodal Cognition with Qwen3 VL 32B Thinking
The Qwen3 VL 32B Thinking represents a groundbreaking multimodal vision-language model (VLM) specifically engineered for intricate visual-textual reasoning and sophisticated, extended chain-of-thought processing. Its innovative "Thinking only" mode is meticulously optimized for deep analytical tasks, seamlessly integrating rich visual inputs with nuanced language understanding. This powerful combination makes it the ideal choice for use cases demanding unparalleled multimodal cognition and long-form logical deductions.
🔧 Technical Specifications
- ✓ Model Type: Multimodal Vision-Language Model (VLM)
- ✓ Parameter Size: 32 billion parameters
- ✓ Input: Visual data + Text prompts
- ✓ Output: Textual responses enriched with embedded reasoning and detailed explanations
- ✓ Architecture: Transformer-based with advanced cross-modal attention layers, highly optimized for complex reasoning tasks
- ✓ Thinking Mode: Features a deep chain-of-thought reasoning pipeline, enabling sophisticated and multi-step inference
- ✓ Latency: Optimized for efficient batch processing, with latency considerations tailored for profound analytical depth
📊 Exceptional Performance in Complex Tasks
The Qwen3 VL 32B "Thinking" mode excels by enabling sequential, chain-of-thought style reasoning. This capability proves highly effective for intricate, multi-step challenges across diverse domains:
- Advanced Coding: From generating to debugging complex code structures.
- Higher Mathematics: Solving challenging mathematical problems and proofs.
- Logical Deduction: Performing sophisticated logical inferences and problem-solving.
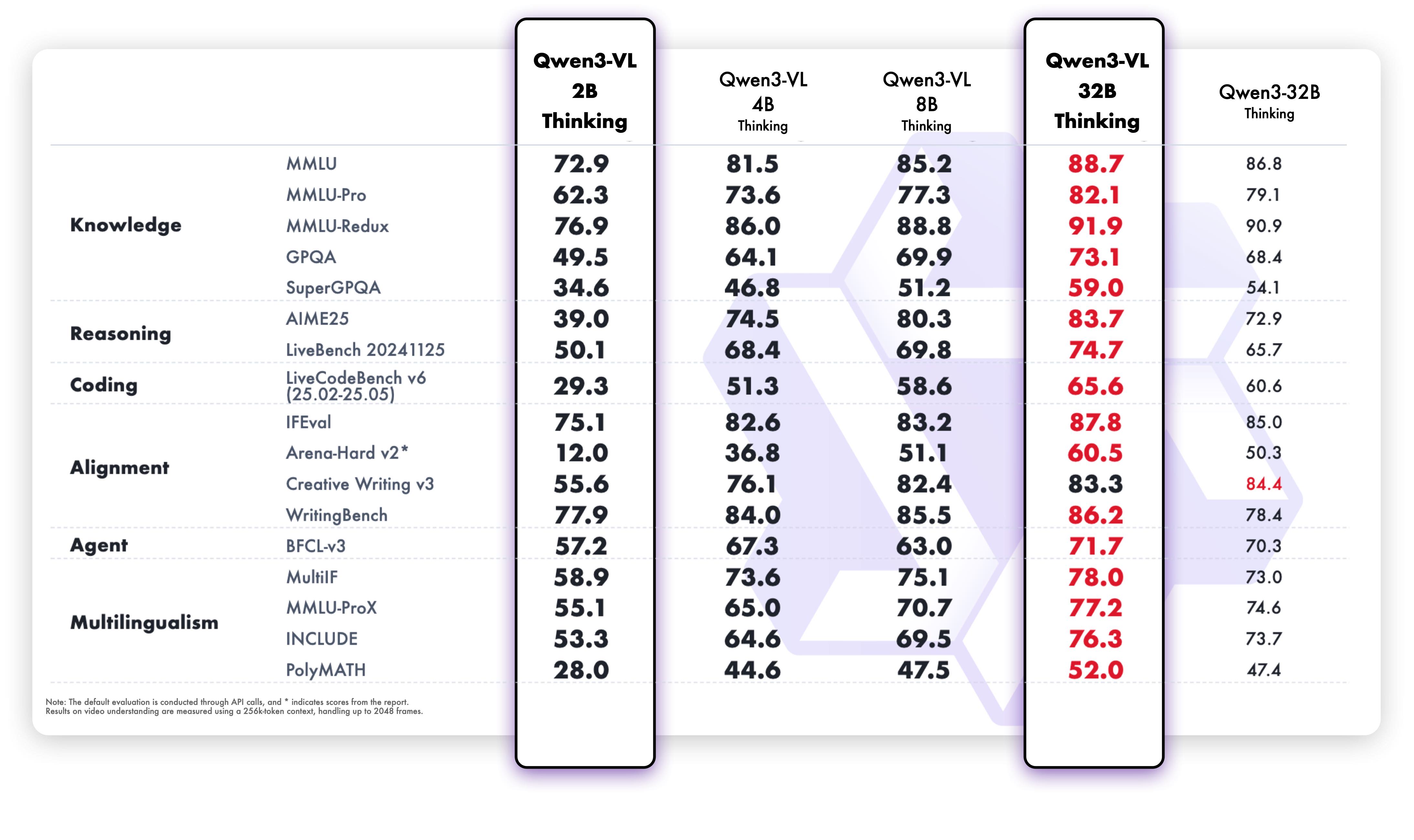
Visual insight into Qwen3 VL 32B's advanced reasoning capabilities.
★ Core Features & Advantages
- ✓ Superior Visual-Textual Reasoning: Capable of interpreting intricate imagery with profound contextual understanding.
- ✓ Extended Chain-of-Thought: Supports detailed, step-by-step analysis within responses, crucial for complex problem-solving.
- ✓ Dedicated "Thinking Only" Mode: Prioritizes cognitive depth and accuracy over speed, making it perfectly suited for demanding research-grade tasks.
- ✓ Seamless Cross-Modal Integration: Flawlessly integrates visual inputs with text to deliver comprehensive, unified outputs.
- ✓ Robust Memory & Context Window: Supports extensive context, ensuring unparalleled continuity in complex dialogues or lengthy documents.
- ✓ Broad Adaptability: Highly suitable for scientific, medical, and AI research environments necessitating advanced multimodal reasoning capabilities.
💰 Qwen3 VL 32B API Pricing
- ✓ Input: $0.735 / 1M tokens
- ✓ Output: $8.82 / 1M tokens
🔍 Diverse Practical Use Cases
Harness the exceptional power of Qwen3 VL 32B Thinking across a wide array of applications demanding advanced multimodal intelligence:
- ✓ Multimodal Research Assistant: Facilitate highly detailed image interpretation and reasoning within academic and scientific content.
- ✓ Medical Imaging Analysis: Significantly enhance diagnostic insights by intelligently linking visual scans with complex textual queries.
- ✓ Legal & Financial Documentation: Analyze charts, figures, and extensive long-form contracts that incorporate embedded visual elements.
- ✓ Interactive AI Tutoring: Provide clear, step-by-step explanations of visual concepts complemented by robust text-based educational support.
- ✓ Dynamic Content Creation: Generate rich, well-reasoned narratives grounded in images for diverse fields like journalism, marketing, and storytelling.
- ✓ Advanced Multimodal Data Mining: Extract profound and actionable insights from large datasets combining both images and text annotations.
💻 Code Sample for Integration
<snippet data-name="open-ai.chat-completion" data-model="alibaba/qwen3-vl-32b-thinking"></snippet>(Note: This is a placeholder; replace <snippet> with your actual API integration code.)
📜 Qwen3 VL 32B Thinking: Comparative Advantage
✓ vs. GPT-4o-VL: Qwen3 VL 32B Thinking provides significantly improved visual reasoning and superior longer-chain thought coherence in multimodal tasks. In contrast, GPT-4o-VL excels in conversational fluency but typically offers shorter reasoning contexts.
✓ vs. Claude 4.5 Haiku: Qwen3 VL 32B’s architecture is meticulously optimized for complex, stepwise logic within visual-text combinations. This gives it an edge over Claude 4.5 Haiku, which, while strong in creative and poetic language, places less emphasis on extensive chain-of-thought length.
✓ vs. Gemini 2.5 Pro: Both models demonstrate strong capabilities in multimodal reasoning and STEM domains. However, Qwen3 VL 32B Thinking distinguishes itself with notably larger context windows (up to 256K tokens, expandable) and dedicated optimization for comprehensive long-duration video and document understanding.
❓ Frequently Asked Questions (FAQ)
Q1: What is Qwen3 VL 32B Thinking?
A: It's a cutting-edge multimodal vision-language model (VLM) specifically designed for advanced visual-textual reasoning and extended chain-of-thought processing, particularly in its "Thinking only" mode for deep analytical tasks.
Q2: What are the key advantages of its "Thinking only" mode?
A: This mode prioritizes cognitive depth and analytical accuracy over processing speed, making it exceptionally well-suited for demanding research-grade tasks that require multi-step reasoning, such as complex coding, advanced math, and intricate logical deductions.
Q3: How does Qwen3 VL 32B Thinking support medical applications?
A: It's highly capable in medical imaging analysis, assisting diagnostic insights by effectively linking visual scans with complex textual queries and providing nuanced, reasoned interpretations, making it a powerful tool for healthcare professionals.
Q4: What is the pricing structure for Qwen3 VL 32B API?
A: The API is priced at $0.735 / 1M tokens for input and $8.82 / 1M tokens for output, designed for cost-effective advanced multimodal processing.
Q5: How does its context window compare to competitors like Gemini 2.5 Pro?
A: While both focus on multimodal reasoning, Qwen3 VL 32B Thinking offers significantly larger context windows (up to 256K tokens, expandable). This optimization makes it superior for processing and understanding long-duration video and extensive documents, providing deeper, more continuous contextual awareness.
AI Playground

