 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Антропический - Клод
Антропический - Клод xAI - Grok
xAI - Grok Глубокий поиск
Глубокий поиск Alibaba - Qwen
Alibaba - Qwen ByteDance - Лучшее от ByteDance
ByteDance - Лучшее от ByteDance Все модели
Все модели Планы предприятия
Планы предприятия Разработка приложений на основе искусственного интеллекта
Разработка приложений на основе искусственного интеллекта API для перевода с помощью ИИ
API для перевода с помощью ИИ Услуги SEO/ГЕ с использованием ИИ
Услуги SEO/ГЕ с использованием ИИ Географически оптимизированная PR-служба
Географически оптимизированная PR-служба Сервис веб-скрейпинга
Сервис веб-скрейпинга OpenClaw
OpenClaw Лучшие инструменты ИИ
Лучшие инструменты ИИ Лучшие роботы с искусственным интеллектом
Лучшие роботы с искусственным интеллектом
 Авторизоваться
Авторизоваться



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'alibaba/qwen3-next-80b-a3b-instruct',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="alibaba/qwen3-next-80b-a3b-instruct",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")

-p-130x130q80-p-130x130q80.png)
Подробная информация о товаре
Qwen3-Next-80B-A3B Инструкция Это высокотехнологичная, оптимизированная для конкретных инструкций модель обработки больших языков, разработанная для исключительной скорости, стабильности и обработки сверхдлинных контекстов с высокой пропускной способностью. Она обеспечивает значительное повышение скорости и экономической эффективности за счет активации лишь небольшой части из своих 80 миллиардов параметров, при этом не снижая производительность в критически важных областях, таких как сложные рассуждения и генерация кода.
⚙️ Технические характеристики
Устройство Qwen3-Next-80B-A3B Instruct оптимизирует свою работу за счет В процессе вывода активируется лишь около 3 миллиардов параметров из 80 миллиардов.Этот механизм разреженной активации обеспечивает существенные преимущества:
- Скорость и экономичность: Работает примерно в 10 раз быстрее и экономичнее по сравнению с предыдущей моделью Qwen3-32B.
- Пропускная способность: Обеспечивает более чем в 10 раз более высокую пропускную способность при обработке длинных контекстов, содержащих 32 000 токенов и более.
- Гибкое развертывание: Предлагает универсальные варианты развертывания, включая бессерверную архитектуру, выделенный хостинг по запросу и ежемесячный зарезервированный хостинг.
- Совместимость развертывания: Совместимость с SGLang и vLLM обеспечивает эффективное и масштабируемое использование, а также расширенные возможности прогнозирования на основе нескольких токенов.
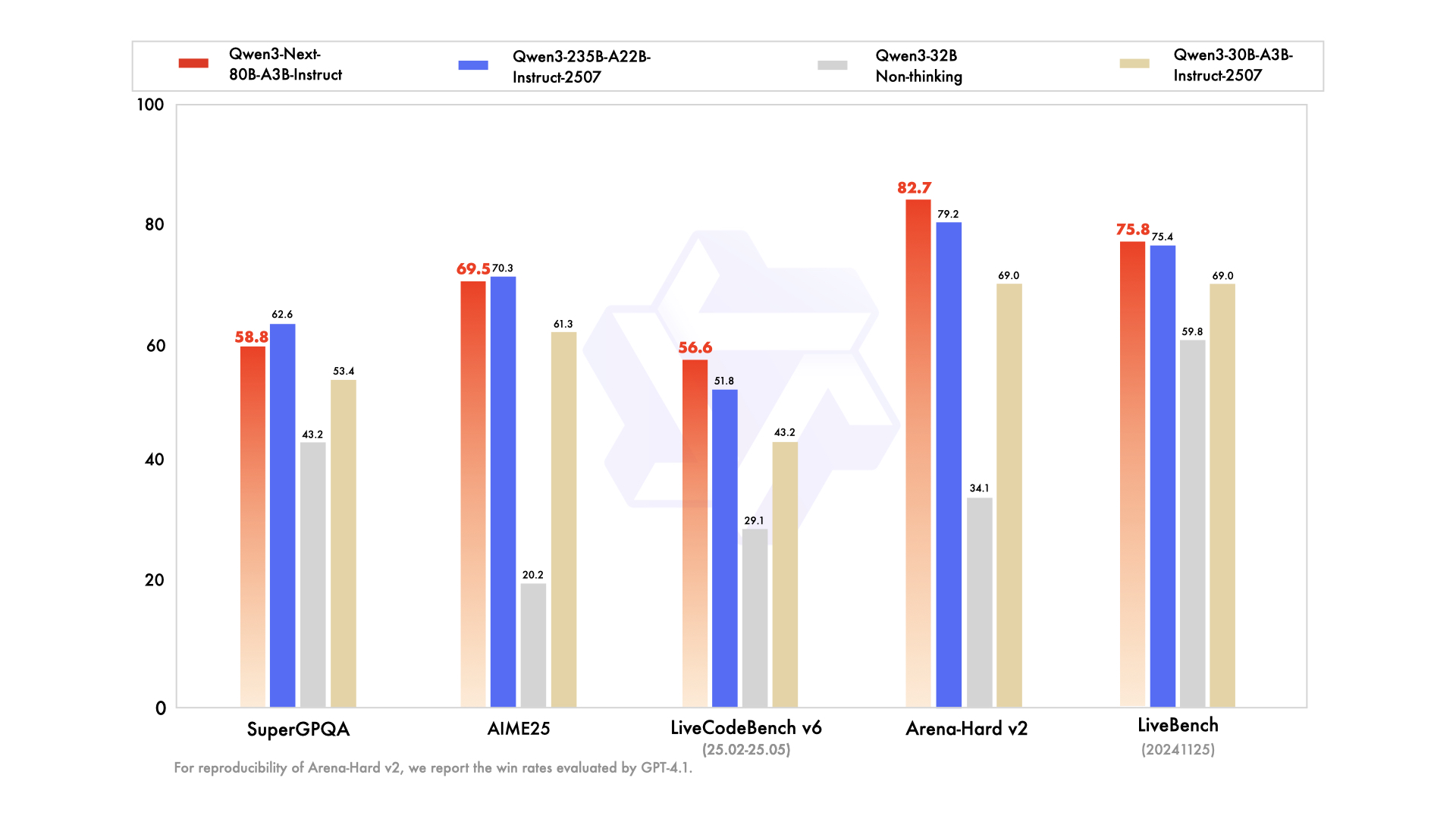
📊 Показатели производительности
- ✅ Высочайшая производительность: По своим характеристикам соответствует или очень близка к флагманской модели Qwen3-235B в различных задачах рассуждения, автозаполнения кода и выполнения инструкций.
- ✅ Безупречная обработка длинного контекста: Последовательно предоставляет стабильные и предсказуемые ответы, особенно преуспевая в задачах, требующих глубокого понимания контекста.
- ✅ Ресурсоэффективность: Превосходит по эффективности более ранние модели среднего размера, оптимизированные под конкретные инструкции, обеспечивая высокую производительность при меньших вычислительных ресурсах.
- ✅ Универсальная интеграция: Идеально подходит для интеграции инструментов, генерации с расширенным поиском (Retrieval-Augmented Generation, RAG) и сложных агентных рабочих процессов, требующих последовательной логической последовательности результатов.
💰 Цены на API
Вход: 0,1575 долл.
Выход: 1,6 доллара
✨ Ключевые возможности
- 🚀 Сверхэффективный вывод: Используется разреженная архитектура «смесь экспертов» (Mixture-of-Experts, MoE), динамически активирующая только 3 миллиарда параметров из 80 миллиардов, что обеспечивает значительно более быструю и экономичную обработку данных.
- 🧠 Исключительная эффективность выполнения задач: Отлично справляется с широким спектром сложных задач, включая логическое мышление, надежную генерацию кода, точное решение вопросов, требующих знаний, и разработку универсальных многоязычных приложений.
- ⚡️ Стабильные и быстрые ответы: Оптимизировано для режима обучения, обеспечивая быстрые и последовательные ответы без промежуточных этапов «размышления».
- 📖 Обработка сверхдлительных контекстов: Отличается собственной длиной контекста в 262 000 токенов, которая может быть расширена до впечатляющих 1 миллиона токенов с помощью передовой технологии масштабирования.
- 📈 Высокая пропускная способность: Обеспечивает десятикратное повышение пропускной способности при обработке обширных длинных контекстов по сравнению с предыдущими моделями.
- 💬 Последовательный диалог и ответы: Идеально подходит для многоходовых диалогов и задач, требующих детерминированных и непротиворечивых окончательных ответов.
- 🛠️ Расширенные рабочие процессы Agentic: Широкие возможности для вызова инструментов, многоэтапного выполнения задач и сложных рабочих процессов с участием агентов, а также бесшовная интеграция инструментов.
💡 Варианты использования
- Генерация кода: Ускорьте разработку программного обеспечения с помощью интеллектуальных подсказок в коде и генерации полных блоков кода.
- Создание и редактирование контента: Создавайте разнообразный контент, от статей до маркетинговых текстов, и выполняйте кропотливую редактуру в соответствии с подробными инструкциями.
- Анализ данных: Обеспечивает сложную интерпретацию данных, статистический анализ и составление исчерпывающих отчетов.
- Автоматизация обслуживания клиентов: Повысьте эффективность работы службы поддержки клиентов за счет точной обработки инструкций и автоматизированных ответов.
- Техническая документация: Упростите процесс создания технической документации, руководств и выходных файлов в различных форматах.
- Автоматизация процессов: Выполняйте многоэтапные задачи и интегрируйте вызов инструментов для автоматизации и оптимизации различных рабочих процессов.
- Длительные беседы и работа с документами: Эффективно управляйте продолжительными диалогами, обобщайте большие документы и извлекайте ключевую информацию из обширных текстов.
💻 Пример кода
import openai client = openai.OpenAI( base_url="https://api.perplexity.ai", # Пример базового URL, замените на фактическую конечную точку api_key="YOUR_API_KEY", # Замените на ваш фактический ключ API ) messages = [ { "role": "system", "content": "Вы Qwen3-Next-80B-A3B Instruct, полезный ИИ-помощник." }, { "role": "user", "content": "Объясните концепцию квантовой запутанности простыми словами для старшеклассника." }, ] response = client.chat.completions.create( model="alibaba/qwen3-next-80b-a3b-instruct", messages=messages, max_tokens=500, temperature=0.7, top_p=0.9, frequency_penalty=0, presence_penalty=0, ) print(response.choices[0].message.content) Примечание: `base_url` и `api_key` в приведенном выше примере являются заполнителями. Для получения подробной информации об интеграции обратитесь к официальной документации API.
🆚 Сравнение с другими моделями
Модель 80B A3B обеспечивает производительность, сопоставимую или близкую к флагманской модели 235B в задачах логического вывода и программирования, при этом будучи значительно более эффективной за счет активации меньшего количества параметров, что обеспечивает более быструю и экономичную обработку данных.
Qwen3-Next обеспечивает сопоставимые возможности отслеживания инструкций и обработки длинного контекста, отличаясь при этом преимуществом в пропускной способности и большим размером окна токена, что делает его особенно подходящим для задач понимания больших объемов документов.
Qwen3-Next демонстрирует превосходную производительность в многоходовых диалогах и рабочих процессах с участием агентов, обеспечивая более детерминированные результаты в очень длинных контекстах по сравнению с сильными сторонами Claude в области диалогов.
Qwen3-Next демонстрирует лучшую масштабируемость при обработке сверхдлинных контекстных данных и превосходную эффективность прогнозирования нескольких токенов, что дает ему явное преимущество при обработке сложных многоэтапных задач рассуждения.
❓ Часто задаваемые вопросы
В1: Что делает инструкцию Qwen3-Next-80B-A3B исключительно эффективной?
Модель использует разреженную архитектуру «смешанных экспертов» (Mixture-of-Experts, MoE), активируя во время вывода только приблизительно 3 миллиарда из 80 миллиардов параметров. Этот инновационный подход приводит к значительному ускорению обработки и снижению эксплуатационных затрат, обеспечивая до 10 раз большую эффективность по сравнению с более ранними моделями.
В2: Как он работает со сверхдлинными контекстами?
Инструкция Qwen3-Next-80B-A3B поддерживает длину контекста в 262 000 токенов, а благодаря передовой технологии масштабирования её можно увеличить до впечатляющих 1 миллиона токенов. Эта возможность делает её идеальной для задач, требующих глубокого понимания обширных документов и длительных разговоров.
В3: Как её производительность соотносится с другими ведущими языковыми моделями?
Обладая высокой эффективностью, Qwen3-Next-80B-A3B Instruct по производительности не уступает, а зачастую и приближается к флагманским моделям, таким как Qwen3-235B, в задачах сложных рассуждений и генерации кода. Он также предлагает сопоставимые или превосходящие возможности по пропускной способности, обработке длинных контекстов и детерминированным результатам по сравнению с такими моделями, как GPT-4.1, Claude 4.1 Opus и Gemini 2.5 Flash.
В4: Каковы основные варианты использования Qwen3-Next-80B-A3B Instruct?
Эта модель исключительно хорошо подходит для приложений, требующих высокой пропускной способности, точного выполнения инструкций и обширной обработки контекста. Ключевые сценарии использования включают в себя генерацию сложного кода, создание сложного контента, детальный анализ данных, автоматизированное обслуживание клиентов, техническую документацию и сложные рабочие процессы с участием агентов.
Q5: Совместима ли инструкция Qwen3-Next-80B-A3B с существующей инфраструктурой развертывания?
Да, модель разработана для бесшовной интеграции с существующими инструментами развертывания, такими как SGLang и vLLM, и поддерживает расширенные возможности прогнозирования с использованием нескольких токенов. Она также предоставляет гибкие варианты развертывания, включая бессерверную архитектуру, выделенный хостинг по запросу и ежемесячный резервированный хостинг, чтобы соответствовать различным операционным потребностям.
Игровая площадка для ИИ

