 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Антропический - Клод
Антропический - Клод xAI - Grok
xAI - Grok Глубокий поиск
Глубокий поиск Alibaba - Qwen
Alibaba - Qwen ByteDance - Лучшее от ByteDance
ByteDance - Лучшее от ByteDance Все модели
Все модели Планы предприятия
Планы предприятия Разработка приложений на основе искусственного интеллекта
Разработка приложений на основе искусственного интеллекта API для перевода с помощью ИИ
API для перевода с помощью ИИ Услуги SEO/ГЕ с использованием ИИ
Услуги SEO/ГЕ с использованием ИИ Географически оптимизированная PR-служба
Географически оптимизированная PR-служба Сервис веб-скрейпинга
Сервис веб-скрейпинга OpenClaw
OpenClaw Лучшие инструменты ИИ
Лучшие инструменты ИИ Лучшие роботы с искусственным интеллектом
Лучшие роботы с искусственным интеллектом
 Авторизоваться
Авторизоваться



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'alibaba/qwen3-vl-32b-instruct',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="alibaba/qwen3-vl-32b-instruct",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Подробная информация о товаре
✨ Откройте для себя Qwen3 VL 32B Instruct: ваш продвинутый искусственный интеллект для обработки изображений и языка.
Он Инструкция Qwen3 VL 32B Это передовая модель обработки изображений и языка, специально разработанная для точного выполнения инструкций в широком спектре визуальных задач. Она выделяется своей способностью интерпретировать сложные визуальные входные данные и генерировать высококогерентные, контекстно-зависимые текстовые выходные данные. Эта модель тщательно оптимизирована для превосходного описания изображений, создания увлекательного визуального диалога и универсальной генерации контента, что делает ее мощным инструментом для многомодальных приложений искусственного интеллекта.
Как подробно описано в нем Официальный обзор Qwen3 VL 32BQwen3 VL 32B Instruct — это версия, "не требующая только мышления", то есть она оптимизирована для прямого и эффективного выполнения визуальных задач, а не для более широкого общего рассуждения, что обеспечивает превосходную производительность в своей специализированной области.
⚙️ Краткий обзор технических характеристик
- Тип модели: Модель «зрение-язык» (Vision-Language Large Model, VL)
- Количество параметров: 32 миллиарда параметров
- Архитектура: Многомодальная архитектура на основе трансформеров, объединяющая надежный визуальный кодировщик со сложным декодером текста.
- Способы ввода: Обеспечивает бесшовную интеграцию изображений и текстовых инструкций/подсказок.
- Способы вывода: Специализируюсь на создании высококачественного текста (описания, диалоги, креативный контент).
- Тренировочные данные: Модель обучена на обширном, крупномасштабном мультимодальном наборе данных, включающем тщательно аннотированные изображения в сочетании с подробным описательным и разговорным текстом.
- Возможности вывода: Обеспечивает эффективное обучение без использования оружия и с небольшим количеством выстрелов, что исключает необходимость в длительной переподготовке.
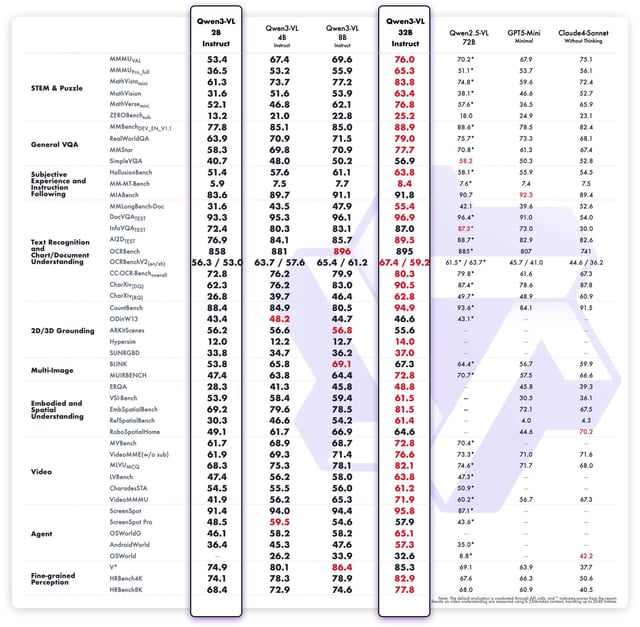
🚀 Непревзойденная производительность и результаты тестов
- 🎯 Достигает высочайшая точность на ведущих наборах данных для визуального описания, тщательно протестированных в сравнении с задачами COCO Caption и VQA.
- 📈 Демонстрирует превосходные навыки следования инструкциям, подтверждено в ходе экспертной оценки на предмет исключительной релевантности и согласованности.
- 💡 Превосходит предыдущие версии Qwen VL. в качестве генерации мультимодального контента и точном согласовании инструкций.
- 🔒 Выставки надежная работа без подзарядки в сложных задачах визуального диалога по сравнению с базовыми моделями.
🌟 Основные характеристики и преимущества
- ✨ Точное описание изображений: Оптимизировано для создания исключительно четких и точных описаний изображений на основе инструкций пользователя.
- 💬 Увлекательные визуальные диалоги: Способен понимать сложные визуальные контексты и участвовать в динамичных визуальных диалогах.
- 🎨 Создание креативного контента: Создает высокорелевантный и инновационный визуальный контент непосредственно на основе текстовых подсказок.
- ✔️ Высокая степень согласованности инструкций: Сводит к минимуму нерелевантный или галлюцинаторный контент, обеспечивая строгое соответствие инструкциям пользователя.
- 🖼️ Эффективная обработка с высоким разрешением: Эффективно обрабатывает большие изображения высокого разрешения, обеспечивая детальное визуальное восприятие.
- 🌍 Многоязычный вывод: Поддерживает многоязычный вывод текста, демонстрируя высокий уровень владения различными языками.
- 🔌 Простая интеграция: Разработан для простой интеграции в конвейеры создания контента на основе ИИ и интерактивные визуальные помощники.
💰 Цены на API Qwen3 VL 32B
- ➡️ Вход: 0,735 доллара США / 1 миллион токенов
- ⬅️ Выход: 2,94 доллара США / 1 миллион токенов
💡 Универсальные варианты использования
- 📸 Автоматическое создание подписей к изображениям: Идеально подходит для систем управления цифровыми активами, обеспечивая мгновенное и точное описание.
- 🗣️ Визуальный контроль качества и поддержка клиентов: Расширяет возможности ботов службы поддержки клиентов, добавляя интерактивные визуальные функции ответа на вопросы.
- ✍️ Маркетинг и создание контента: Обеспечивает создание контента для маркетинговых кампаний, социальных сетей и креативного повествования с использованием изображений.
- 🚶♀️ Помощь людям с нарушениями зрения: Подробно описывает визуальные сцены, оказывая неоценимую поддержку.
- 🔍 Расширенный мультимедийный поиск: Улучшает возможности поисковых систем за счет углубленного понимания контекста на основе изображений.
- 📚 Образовательные приложения: Поддерживает интерактивные визуальные пояснения и обучающие материалы, делая обучение более увлекательным.
💻 Пример кода для интеграции
Ниже приведён типичный фрагмент кода, демонстрирующий взаимодействие с API инструкций Qwen3 VL 32B.
import openai client = openai.OpenAI( api_key="YOUR_API_KEY", # Замените на ваш фактический ключ API base_url="https://api.your-provider.com/v1" # Замените на вашу конечную точку API ) response = client.chat.completions.create( model="alibaba/qwen3-vl-32b-instruct", messages=[ {"role": "system", "content": "Вы полезный помощник, который может описывать изображения."}, {"role": "user", "content": [ {"type": "text", "text": "Что изображено на этом изображении?"}, {"type": "image_url", "image_url": {"url": "https://example.com/image.jpg"}} ]} ], max_tokens=500 ) print(response.choices[0].message.content) 🆚 Qwen3 VL 32B Инструкция по сравнению с другими ведущими моделями
против Qwen3 VL 32B Base:
Он Инструктивная версия Тщательно настроена для обеспечения превосходного соответствия инструкциям, что позволяет получать более контекстно-релевантные и точные описания. В отличие от неё, базовая модель в первую очередь ориентирована на общее мультимодальное понимание.
против OpenAI GPT-4 (с компьютерным зрением):
Qwen3 VL 32B Instruct специально разработан и оптимизирован для выполнения специализированных инструкций и генерации визуального контента, демонстрируя меньшее количество визуальных галлюцинаций при работе с входными данными. Хотя GPT-4 предлагает более широкие возможности общего искусственного интеллекта, он может быть менее специализирован на непосредственном выполнении визуальных инструкций.
против Клода 4.5 Визуальное изображение:
Qwen3 VL 32B Instruct обеспечивает более качественное описание изображений и диалогов, с упором на визуальные инструкции. Claude, хотя и отлично справляется с рассуждениями на основе текста и управлением более широкими контекстами, обычно предлагает несколько меньшую визуальную специализацию.
против DeepSeek V3.1:
Qwen3 VL 32B Instruct отлично справляется с задачами детального создания контента и сложной визуализации. DeepSeek, напротив, больше ориентирован на семантический поиск и извлечение изображений.
❓ Часто задаваемые вопросы (FAQ)
В: Для чего в первую очередь предназначена программа Qwen3 VL 32B Instruct?
А: Это специализированная модель визуально-языкового восприятия, оптимизированная для выполнения инструкций в таких задачах, как точное описание изображений, увлекательный визуальный диалог и интеллектуальная генерация контента на основе визуальных данных и текстовых подсказок.
В: Чем Qwen3 VL 32B Instruct отличается от своей базовой версии?
A: Версия Instruct специально оптимизирована для повышения точности выполнения инструкций, что приводит к более точным и контекстно-релевантным описаниям, в отличие от базовой модели, которая обеспечивает общее мультимодальное понимание.
В: Каковы основные преимущества использования Qwen3 VL 32B Instruct?
A: Ключевые преимущества включают точное описание изображений, надежные возможности визуального диалога, создание креативного контента с высокой степенью согласованности инструкций, эффективную обработку изображений высокого разрешения и многоязычный текстовый вывод.
В: Можно ли использовать инструкцию Qwen3 VL 32B в реальных условиях?
А: Безусловно. Это идеально подходит для автоматического создания подписей к изображениям, визуальных вопросов и ответов в службе поддержки клиентов, создания контента с помощью ИИ, оказания помощи пользователям с нарушениями зрения, улучшения поиска мультимедийного контента и интерактивных образовательных инструментов.
В: Какова структура ценообразования для API Qwen3 VL 32B?
A: Ценообразование ступенчатое: стоимость ввода составляет 0,735 доллара США за 1 миллион токенов, а стоимость вывода — 2,94 доллара США за 1 миллион токенов.
Игровая площадка для ИИ

